By: arjin 

 on 23 May 2023 - 06:13
Tags:
on 23 May 2023 - 06:13
Tags:

Meta ประกาศเผยแพร่โมเดลและโค้ด ของโครงการพัฒนาระบบเสียงพูดในภาษาต่าง ๆ ขนาดใหญ่ (Massively Multilingual Speech - MMS) เพื่อให้ผู้ที่ทำงานวิจัยในส่วนนี้สามารถนำไปพัฒนาต่อยอดได้ โดยโครงการนี้พัฒนาเพิ่มจากระบบแปลงเสียงเป็นข้อความ wav2vec และโมเดลแปลภาษา NLLB ที่เคยเผยแพร่ก่อนหน้านี้
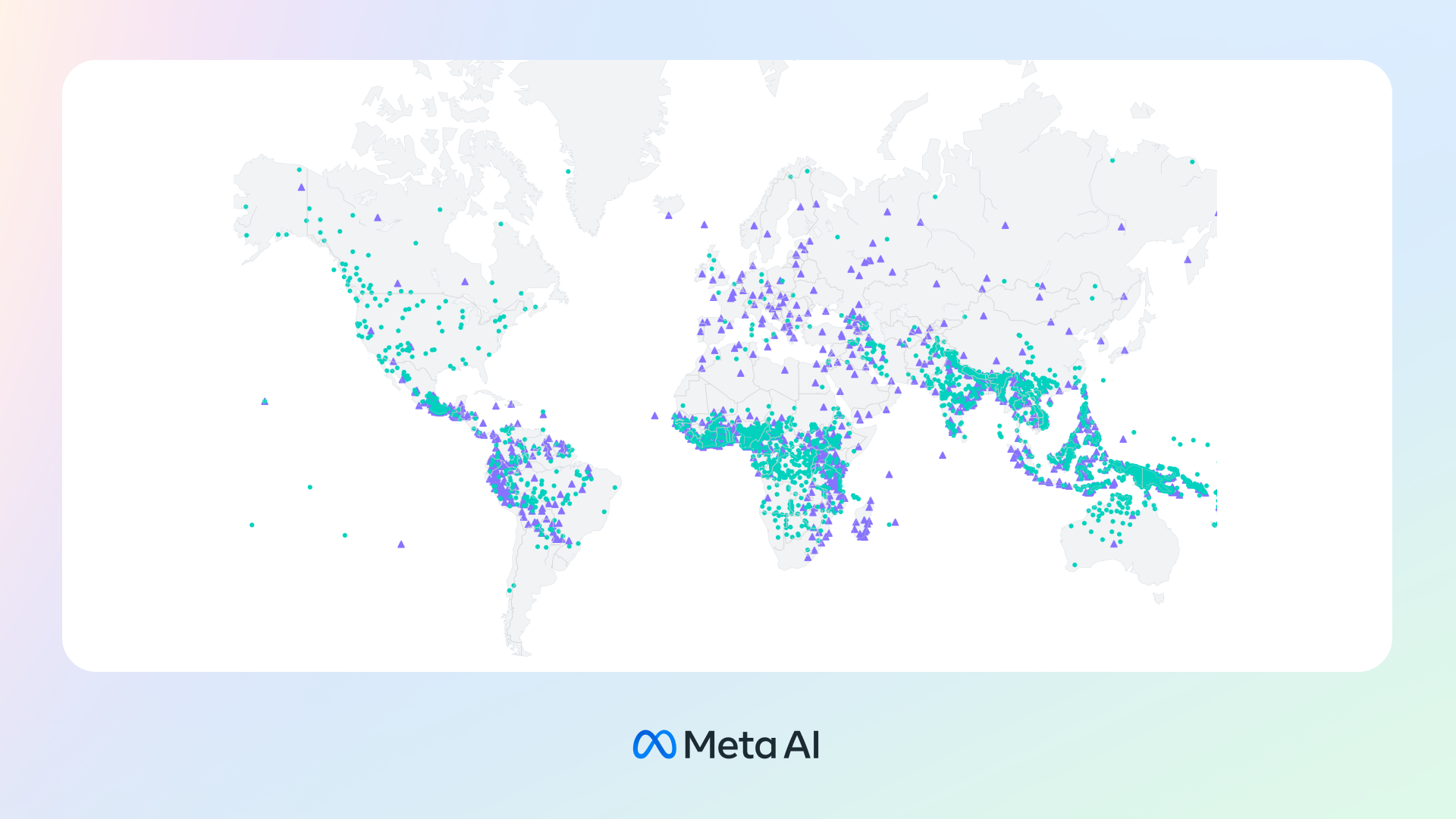
โครงการ MMS เป็นการพัฒนาโมเดลเรียนรู้ภาษาต่าง ๆ ด้วย AI โดยสามารถรู้จำเสียงในภาษาต่าง ๆ ได้มากกว่า 4,000 ภาษา และสร้างเสียงจากข้อความ (text-to-speech) ได้มากกว่า 1,100 ภาษา ซึ่งเป็นการพัฒนาที่มากกว่าเครื่องมือระบบรู้จำเสียงภาษาต่าง ๆ ที่มีอยู่ปัจจุบัน ซึ่งรองรับประมาณ 100 ภาษา เพราะยังมีอีกหลายพันภาษาในโลกที่มีฐานข้อมูลเบื้องต้นน้อยมาก และกว่าครึ่งหนึ่งในนั้นกำลังจะหายไปเนื่องจากมีคนใช้งานน้อยลง บางภาษามีคนที่ยังพูดและใช้อยู่ไม่กี่ร้อยคนในโลกเท่านั้น
ความท้าทายของโครงการนี้คือภาษาที่มีชุดข้อมูลละเอียดครบถ้วนในโลก มีระดับ 100 ภาษา แล้วภาษาอื่นนอกจากนี้ที่มีผู้ใช้งานไม่มาก จะหาข้อมูลได้อย่างไร? Meta บอกว่าทีมงานเริ่มด้วยการเอกสารทางศาสนาและไบเบิ้ล ซึ่งถูกแปลเป็นภาษาต่าง ๆ และใช้งานอยู่มากในโครงการวิจัยทางภาษา พร้อมกับชุดข้อมูลเสียงที่อ่านข้อความ ทำให้ได้ชุดข้อมูลที่มีการกำกับ (label) ออกมาระดับมากกว่า 1,000 ภาษา รวมกับข้อมูลเสียงที่ไม่มีการกำกับเป็นมากกว่า 4,000 ภาษา
อย่างไรก็ตาม Meta ให้คำเตือนว่าโมเดลแปลภาษาในวิธีการดังกล่าวยังไม่สมบูรณ์ดีนัก โดยอาจมีการแปลที่ไม่ตรงความหมาย หรืออาจมีการใช้คำที่ไม่เหมาะสมซึ่งเป็นข้อจำกัดของ AI งานวิจัยนี้มีเป้าหมายเพื่อให้ภาษาที่ไม่เป็นที่นิยมยังถูกเก็บข้อมูลไว้ และแปลงเป็นเสียงพูดออกมาได้นั่นเอง
ที่มา: Meta

Get latest news from Blognone
Follow @twitterapi
Hiring! บริษัทที่น่าสนใจ



Blognone Jobs Premium
Cloudnone
- สงคราม GenAI บนคลาวด์ในปี 2024 ไปถึงไหนกันแล้ว | Cloudnone x AWS
- Kubernetes คืออะไร [Part 1] เกิดขึ้นมาอย่างไร? ทำไมต้องใช้มัน? | Cloudnone EP.14
- CI/CD ยังไงดี ตั้งเซิร์ฟเวอร์เอง vs เช่าคลาวด์ | Cloudnone EP.13
- รู้จักโน้ตบุ๊กบนคลาวด์ เช่าใช้งาน Jupyter Notebook ที่ไหนดี | Cloudnone Ep.12
- สรุปข่าวใหญ่ปี 23 และคาดการณ์เทรนด์ปี 24 ในวงการ Cloud | Cloudnone EP.11