By: lew 


 on 20 February 2024 - 13:04
Tags:
on 20 February 2024 - 13:04
Tags:
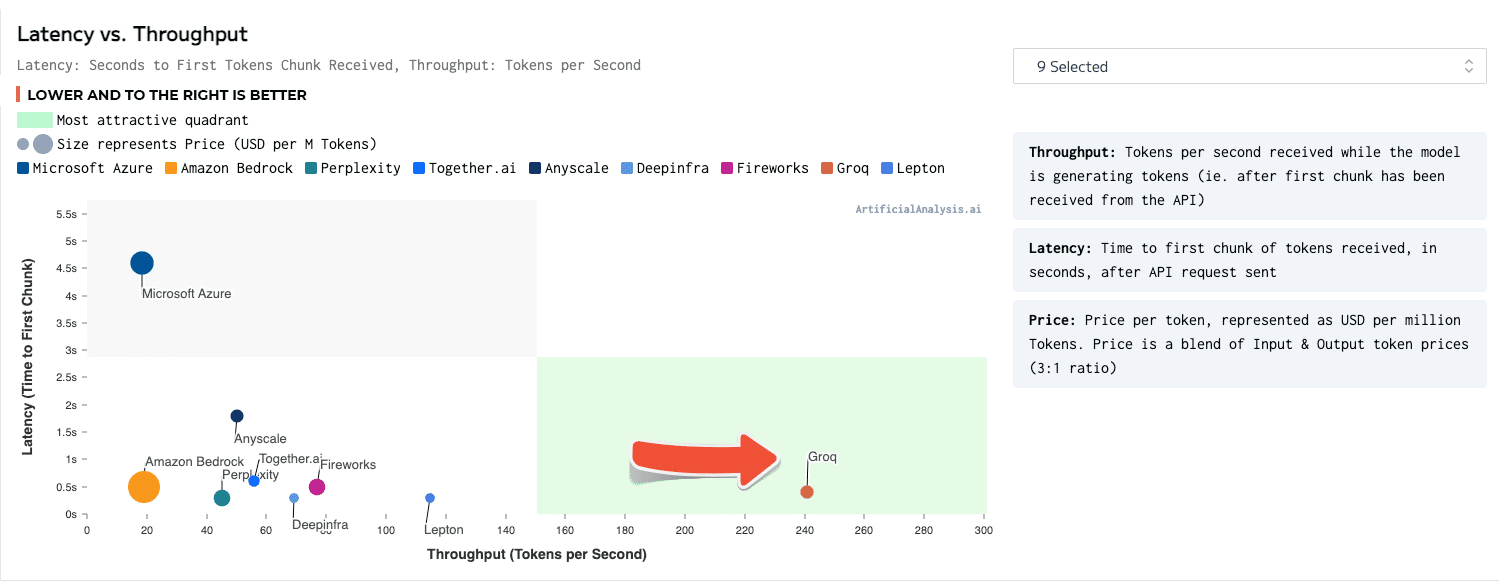
Groq สตาร์ตอัพผู้พัฒนาชิป GroqChip 1 สำหรับการรันโมเดลปัญญาประดิษฐ์ LLM และผู้ให้บริการ LLM แบบคลาวด์ระบุถึงผลทดสอบของ ArtificialAnalysis.ai ที่แสดงให้เห็นว่า Groq เป็นผู้ให้บริการที่สามารถประมวลผล LLM ได้เร็วที่สุดในตลาด
โมเดลที่ใช้ทดสอบเป็นโมเดล Llama 2 70B ที่มีคลาวด์หลายเจ้าให้บริการกัน รวมถึงคลาวด์รายใหญ่อย่าง Amazon Bedrock และ Azure แต่จุดที่ Groq นำมาเน้นคือความเร็วในการตอบ ที่ระยะเวลาจนถึงการตอบ 100 token แรกนั้นกินเวลาเพียง 0.7 วินาที และอัตราการตอบรวมได้เร็วกว่า 240 token ต่อวินาที นับว่าเร็วกว่าคู่แข่งอันดับสองแบบห่างไกล (Lepton รันได้สูงกว่า 120 token ต่อวินาทีไปเล็กน้อย)
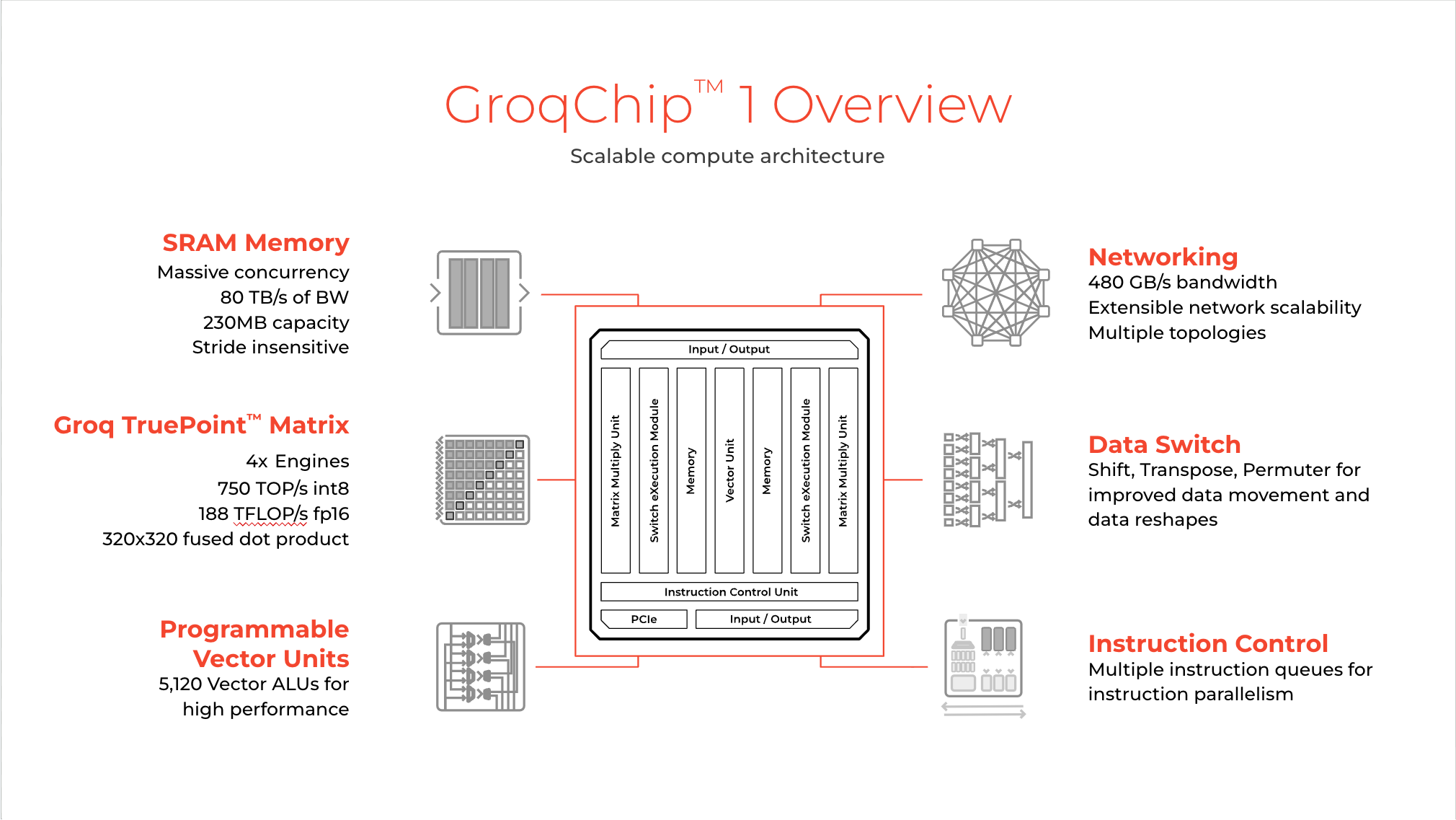
ชิป GroqChip 1 นั้นทาง Groq เรียกว่าเป็น LPU หรือ language processing unit จุดแตกต่างคือในชิปมี SRAM มากถึง 230MB สำหรับการรัน AI โดยเฉพาะ สถาปัตยกรรมโดยรวมเรียบง่ายกว่าชิปกราฟิก
ตอนนี้โมเดลที่ดีที่สุดที่ Groq ให้บริการคือ Mixtral 8x7B 32k สามารถรันได้ที่ระดับ 500 token ต่อวินาที และเว็บ Groq เปิดให้ทุกคนทดสอบได้โดยไม่ต้องสมัครสมาชิก
ที่มา - Groq

Get latest news from Blognone
Follow @twitterapi



Blognone Jobs Premium
Cloudnone
- สงคราม GenAI บนคลาวด์ในปี 2024 ไปถึงไหนกันแล้ว | Cloudnone x AWS
- Kubernetes คืออะไร [Part 1] เกิดขึ้นมาอย่างไร? ทำไมต้องใช้มัน? | Cloudnone EP.14
- CI/CD ยังไงดี ตั้งเซิร์ฟเวอร์เอง vs เช่าคลาวด์ | Cloudnone EP.13
- รู้จักโน้ตบุ๊กบนคลาวด์ เช่าใช้งาน Jupyter Notebook ที่ไหนดี | Cloudnone Ep.12
- สรุปข่าวใหญ่ปี 23 และคาดการณ์เทรนด์ปี 24 ในวงการ Cloud | Cloudnone EP.11