By: lew 


 on 31 October 2018 - 19:14
Tags:
on 31 October 2018 - 19:14
Tags:
Topics:

GitHub รายงานเหตุการณ์เว็บล่มเมื่อวันที่ 22 ตุลาคมที่ผ่านมา พร้อมกับระบุถึงบทเรียนที่ได้จากการล่มครั้งนี้
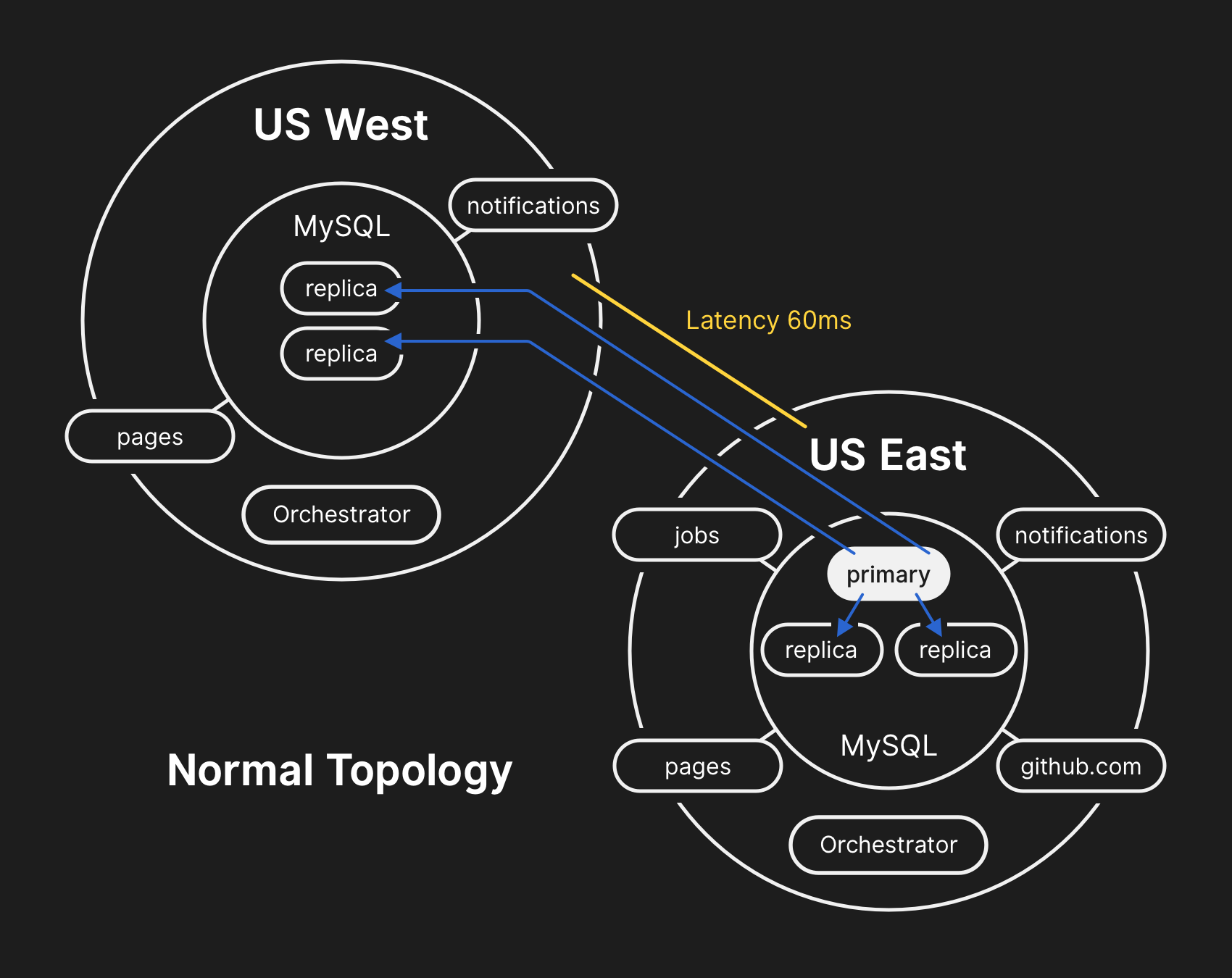
เรื่องทั้งหมดเริ่มจากการบำรุงรักษาอุปกรณ์ไฟเบอร์ 100G ที่เริ่มทำงานไม่เต็มประสิทธิภาพ โดยการเปลี่ยนอุปกรณ์ทำให้เน็ตเวิร์คที่เชื่อมระหว่างศูนย์ข้อมูลหลัก คือฝั่งตะวันตก (US West) และฝั่งตะวันออก (US East) ดับไปเป็นเวลา 43 วินาที
ระบบฐานข้อมูลของ GitHub ใช้คลัสเตอร์ MySQL โดยก่อนเน็ตเวิร์คดับ เซิร์ฟเวอร์หลัก (primary) ที่รับข้อมูลเขียนฐานข้อมูลอยู่ที่ US East โดยคลัสเตอร์ถูกควบคุมด้วย Orchestrator ของ GitHub เอง เมื่อเน็ตเวิร์คดับไป ตัว Orchestrator ก็พยายามเลือกเซิร์ฟเวอร์ในศูนย์ข้อมูล US West เป็นเซิร์ฟเวอร์หลักใหม่ และส่งข้อมูลการเขียนลงฐานข้อมูลไปยัง US West อย่างไรก็ตาม มีข้อมูลการเขียนส่วนหนึ่งที่ US East เขียนไปแล้ว ไม่กี่วินาที แต่ US West ไม่ได้รับ ทำให้คลัสเตอร์ไม่สามารถกลับมาซิงก์กันได้
ทีมงานตัดสินใจหยุดงานที่ต้องเขียนลงฐานข้อมูล เช่น การรับ push เพื่อรักษาความถูกต้องของข้อมูลเอาไว้ โดยสถานะสุดท้ายคือ US West มีข้อมูลที่ US East ไม่มีอยู่นาน 40 นาที ขณะที่ US East มีข้อมูลที่ US West ไม่มีอยู่ไม่กี่วินาที
หลังจากนั้นทางออกคือการสร้างคลัสเตอร์ขึ้นใหม่จากไฟล์แบ็กอัพ กระบวนการ restore ฐานข้อมูลขนาดใหญ่ปกติก็ใช้เวลาหลายชั่วโมงอยู่แล้ว แม้นโยบายของ GitHub จะสำรองฐานข้อมูลทุก 4 ชั่วโมงและทดสอบไฟล์สำรองอย่างน้อยวันละครั้ง แต่ก็ไม่เคยมีการซ้อมสร้างคลัสเตอร์ใหม่ทั้งหมดจริงๆ ทำให้ใช้เวลานาน และหลังจากกู้เรียบร้อยแล้วก็ยังต้องวิเคราะห์ล็อก MySQL ว่ามีข้อมูลอะไรผิดพลาดหรือไม่
ทาง GitHub ระบุว่าหลังจากนี้จะคอนฟิก Orchestrator ใหม่ ให้เลี่ยงการเลือกเซิร์ฟเวอร์หลักข้ามทวีป ซึ่งทำให้คลัสเตอร์แยกเป็นสองส่วนในครั้งนี้ ทาง GitHub เชื่อว่าการย้ายเซิร์ฟเวอร์หลักในโซนเดียวกันโดยปกติค่อนข้างปลอดภัย
ในระยะยาว ทางบริษัทมีแนวทางจะออกแบบให้ระบบทนทานมากขึ้นโดยเตรียมออกแบบ active/active/active แนวคิดคือศูนย์ข้อมูลหนึ่งสามารถล่มไปทั้งศูนย์ได้โดยผู้ใช้ยังไม่ได้รับผลกระทบ
ที่มา - GitHub Blog

Get latest news from Blognone
Follow @twitterapi



Comments
เน็ตเวิร์คดับ
Mekokung's Story บล็อกส่วนตัวที่ย้ายไป Blogger แล้วนะ
พี่ไม่คิดจะจับดาวน์หน่อยเหรอ นาทีเดียวเอง - -'
คงมั่นใจว่าระบบตัวเองคงเอาอยู่รึเปล่าครับ เลยไม่อยากดาวน์ระบบเพื่อแก้ปัญหา
ยังไงมันก็ต้องล่มอยู่ดีอะครับ เพราะ primary มันมีได้ที่เดียว split brain เมื่อไรก็ต้องหยุด
ระหว่างสั่ง down ฝั่ง slave vs. ปล่อยให้มันจัดการเอง ถ้าทำได้ก็ควรเลือกสั่ง down ครับ
งั้นแสดงว่า active/passive แบบเปลี่ยน mode เป็น passive/active ได้ ไม่ work สิครับ เพราะเกิดปัญหาแบบนี้ จะทำให้ข้อมูลไม่ตรงกัน
แต่ถ้า active/passive แบบไม่ต้องเปลี่ยน mode แล้วถ้าข้อมูลไม่ตรง ก็แค่ สร้าง passive ตัวใหม่ ขึ้นมา หรือเปล่าครับ
ใช่ครับ กรณี split brain ขึ้นมาทีนึงคือ consistency พังพินาศกันง่ายๆ เลย
อ่าว ก็นึกว่าจะเปลี่ยนไปใช้ MSSQL ซะอีก
สรุป ไม่เกี่ยวกับไมโครซอฟท์
นั่นสิ ดูเหมือนเป็นแพะไปละ...
แสดงว่าถ้าทีมงานตัดสินใจหยุดงานที่ต้องเขียนลงฐานข้อมูลตั้งแต่แรก(มี downtime) ก็จะไม่ล่มนานขนาดนี้สินะครับ
Github ไม่ได้ใช้พวก NoSQL หรอกหรอนี่
เข้ามาเก็บความรู้ ^^
..: เรื่อยไป
Link ระหว่างกัน ไม่มีสำรองหรอเนี่ยถึง down ได้