By: mk 
 on 28 May 2021 - 16:18
Tags:
on 28 May 2021 - 16:18
Tags:
Topics:

กูเกิลออก Chrome 91 ที่ระบุว่าเร็วขึ้นสูงสุด 23% อันเป็นผลมาจากคอมไพเลอร์จาวาสคริปต์ตัวใหม่ Sparkplug
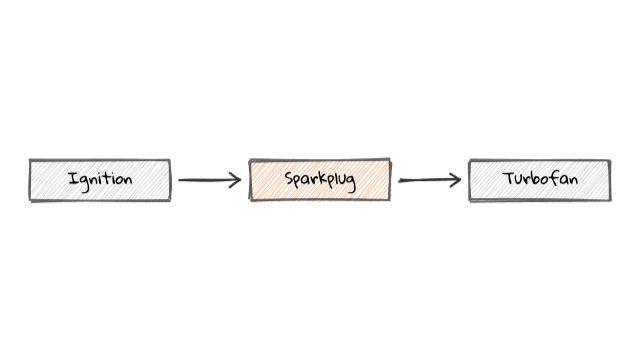
เดิมทีเอนจิน V8 ของ Chrome มีคอมไพเลอร์ 2 ระดับคือ Ignition ที่เริ่มแปลงจาวาสคริปต์ชั้นแรกเป็น byte code และ Turbofan ทำหน้าที่ปรับแต่ง (optimize) เป็น machine code ที่มีประสิทธิภาพสูง โดยอิงจากข้อมูลที่ได้ตอนแปลง byte code มาช่วยปรับแต่ง ปัญหาของแนวทางเดิมคือ Turbofan เริ่มทำงานช้ากว่า Ignition มาก
ทางแก้คือเพิ่มคอมไพเลอร์ Sparkplug มาคั่นตรงกลาง โดย Sparkplug จะสร้าง machine code แต่ไม่อิงข้อมูลตอน Ignition รัน ทำให้ไม่ต้องรอกัน ผลที่ได้คือ machine code ที่มีประสิทธิภาพดีในระดับหนึ่ง แต่ได้ผลลัพธ์ออกมาเร็วกว่า Turbofan มาก จากนั้นค่อยนำโค้ดที่ได้ไป optimize ด้วย Turbofan อีกทีถ้าจำเป็น
เทคนิคอีกอย่างที่ V8 นำมาใช้งานคือ short builtins เป็นวิธีการจัดวาง machine code ไว้ในแรม โดยนำชุดคำสั่งที่ใช้บ่อยๆ (common routines) คัดลอกมาวางไว้ในตำแหน่งหน่วยความจำใกล้ๆ กับที่ใช้งาน เพื่อให้ซีพียูไม่ต้องเรียกโค้ดที่อยู่ไกลๆ (ทำเรื่อง branch prediction ได้ดีขึ้น)
กูเกิลบอกว่าเทคนิคนี้ใช้ได้ดีกับสถาปัตยกรรมซีพียูบางตัว เช่น Apple M1 ที่อนุญาตให้ call คำสั่งได้ไกล (4 GiB) การนำคำสั่งที่ใ้ช้บ่อยๆ มาวางใกล้ๆ จึงทำให้ซีพียูเรียกคำสั่งเหล่านี้ได้เร็วขึ้นมาก
ที่มา - Chromium Blog

Get latest news from Blognone
Follow @twitterapi
Hiring! บริษัทที่น่าสนใจ



Cloudnone
- AWS มาไทย ย้ายเลยดีไหม อะไรยังมาไม่ครบบ้าง? | Cloudnone Ep. 23
- NVIDIA จะไปหยุดที่ตรงไหน ทำไมครองโลกดาต้าเซ็นเตอร์ | Cloudnone EP.22
- ถึงคลาวด์เคราะห์: ทำอย่างไรเมื่อบริการคลาวด์ที่ใช้ถูกยกเลิก | Cloudnone EP. 21
- รู้จักอาชีพ Site Reliability Engineer สำคัญยังไง? | Cloudnone EP. 20
- อธิบาย CrowdStrike ทางเทคนิค ทำไมถึงทำพีซีจอฟ้าเป็นล้านๆ เครื่อง | Cloudnone EP.19
Comments
แบบนี้ nodejs ก็จะเร็วขึ้นด้วย ในอนาคตเมื่อปรับมาใช้ v8 ตัวนี้ รึเปล่า?
Bi-Turbo Fan
จากที่ผมอ่านใน dev blog ไม่มีส่วนที่อ้างอิงถึงการนำโค้ดของ Sparkplug ไป optimize บน TurboFan อีกทีนะ เป็นแค่ตัว optimize ของ Ignition โดยการอิง call pointer ของ Sparkplug เองเท่านั้น
จากในบล็อก: In fact, Sparkplug code is basically just builtin calls and control flow:
เมื่อไหร่ webassembly จะทำ DOM ได้สักทีน้า จะได้ไม่ต้องางมด้วย optimizer แบบนี้อีก - -)
บล็อกส่วนตัวที่อัพเดตตามอารมณ์และความขยัน :P
ชอบที่ เมื่อใช้กับ M1 จะสุดไปอีก
WE ARE THE 99%
กูเกิลบอกว่าเทคนิคนี้ใช้ได้ดีกับสถาปัตยกรรมซีพียูบางตัว เช่น Apple M1 ที่อนุญาตให้ call คำสั่งได้ไกล (4 GiB) การนำคำสั่งที่ใ้ช้บ่อยๆ มาวางใกล้ๆ จึงทำให้ซีพียูเรียกคำสั่งเหล่านี้ได้เร็วขึ้นมาก
--->
ทั้งบน x86-64 และ M1 , indirect jump/call ที่ระยะไกลกว่า 4GB ได้รับผลกระทบจาก misprediction หมด
+1
Apple M1 มีปัญหาใหญ่กับ indirect call prediction > 4 GiB ไม่ใช่เพราะตัวมันอนุญาตให้ call คำสั่งได้ไกลครับ แต่ตัวมันไม่สามารถ predict indirect call > 4 GiB distance ได้(เหมือนกับบ x86/64 ที่มีปัญหานี้) ซึ่งการที่ M1 มี ROB ใหญ่กว่าชาวบ้านทำให้เกิดปัญหามากกว่าเพราะสิ่งที่ predict ใน buffer จะกลายเป็น mispredicted หมด
ดังนั้นการนำข้อมูลมาวางใกล้ๆ (<= 4 GiB) ทำให้ indirect prediction สามารถทำงานได้ถูกต้องครับ
Russia is just nazi who accuse the others for being nazi.
someone once said : ผมก็ด่าของผมอยู่นะ :)
หวังว่า machine code ของ SparkPlug กับ TurboFan ทำงานได้ผลเหมือนกันจริงๆไม่มีหลุดนะ
ไม่งั้นหา bug กันไม่เจอแน่ๆ