By: mk 
 on 14 May 2022 - 10:43
Tags:
on 14 May 2022 - 10:43
Tags:
Topics:

Google Cloud เปิดตัวบริการใหม่ที่สำคัญในงาน I/O 2022 ปีนี้คือ ฐานข้อมูล AlloyDB ที่เข้ากันได้กับ PostgreSQL 100% (อิงอยู่บน PostgreSQL 14 เวอร์ชันล่าสุด) แต่สถาปัตยกรรมข้างหลังออกแบบใหม่หมด มีความเร็วอ่านเขียนทั่วไปเพิ่มขึ้นจาก PostgreSQL 4 เท่า และถ้าเป็นการคิวรีข้อมูลมาวิเคราะห์จะเร็วขึ้นสูงสุด 100 เท่า
เราสามารถเรียก AlloyDB ว่าเป็นคู่แข่งของ Amazon Aurora ที่ AWS นำ MySQL/PostgreSQL มาปรับแต่งเพิ่มเติม (แต่ฝั่งกูเกิลมีเฉพาะ PostgreSQL) ซึ่งกูเกิลก็ชูว่า AlloyDB เร็วกว่า Aurora PostgreSQL 2 เท่าด้วยเช่นกัน
ฟีเจอร์อื่นของ AlloyDB คือฟีเจอร์ด้านวิเคราะห์ข้อมูล และใช้ machine learning ช่วยจัดการฐานข้อมูล ทั้งการแบ็คอัพ แพตช์ สเกล และ replication ให้อัตโนมัติ กูเกิลการันตี SLA ที่ 99.99% ซึ่งน้อยกว่าฐานข้อมูล Cloud Spanner หนี่งหลัก (99.999%) แต่ก็มีโจทย์การใช้งานและราคาที่ต่างกัน


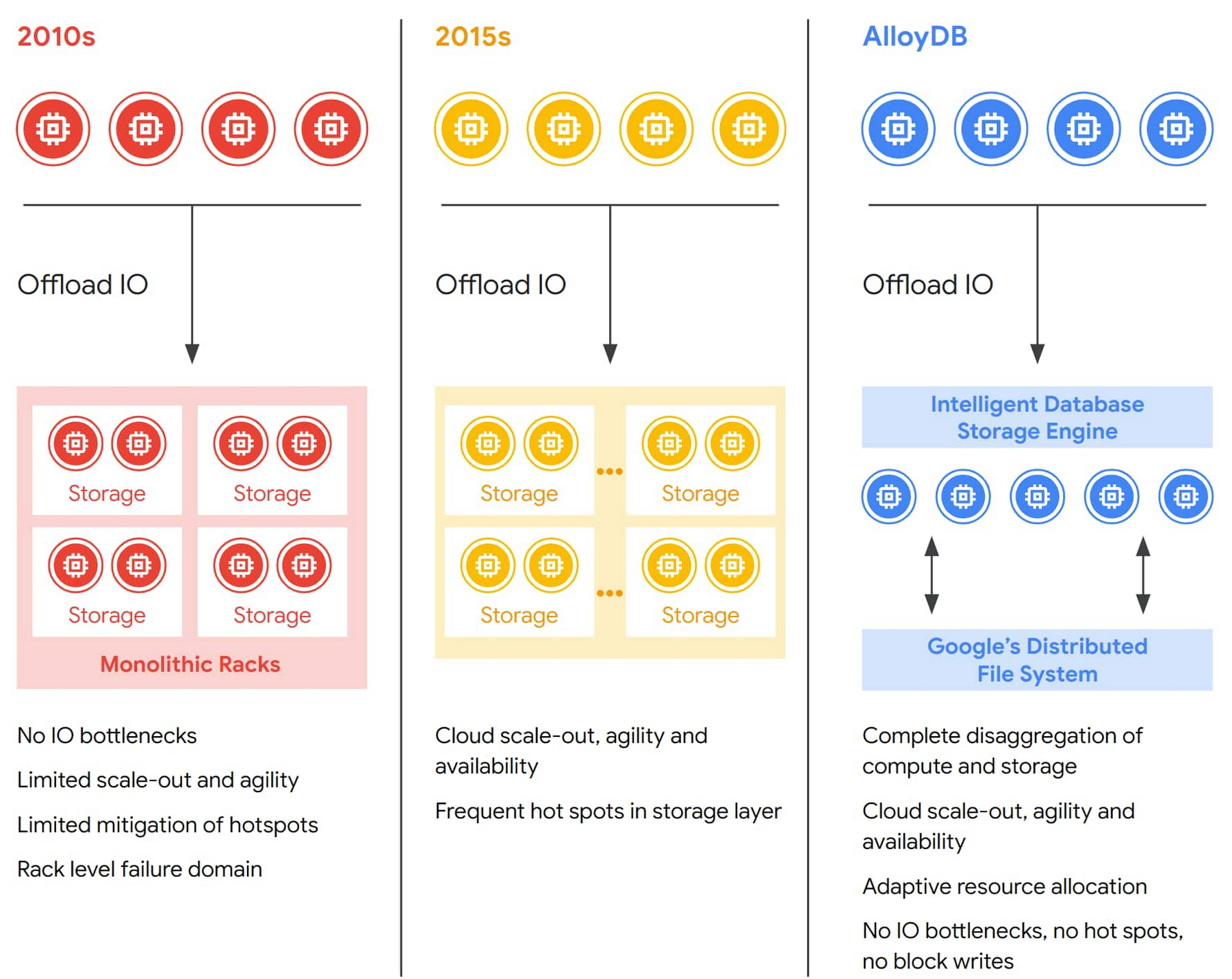
สถาปัตยกรรมเบื้องหลัง AlloyDB คือการแยกส่วน compute และ storage ออกจากกัน ในฐานข้อมูล relational database แบบดั้งเดิม เซิร์ฟเวอร์เครื่องเดียวมีทั้งส่วน compute/storage รวมกัน ทำงานจบในตัว และขยายด้วยวิธี scale up เพิ่มเครื่องให้ใหญ่ขึ้น ซีพียูแรงขึ้น สตอเรจมากขึ้น ซึ่งไม่ค่อยยืดหยุ่นนัก
ฐานข้อมูลยุคถัดมาที่เริ่มมีคลาวด์ เปลี่ยนมาใช้วิธี scale out เพิ่มจำนวนเครื่องแทน ข้อดีคือแก้ปัญหาเรื่องปริมาณพื้นที่สตอเรจให้ยืดหยุ่นกว่าเดิม แต่ยังเจอข้อจำกัดเรื่องการวางแผนพื้นที่สตอเรจให้เหมาะสม ต้องบาลานซ์ระหว่างพื้นที่เยอะเกินความต้องการ กับพื้นที่หรือ I/O ไม่เพียงพอในจังหวะโหลดหนักๆ (spike หรือ hotspot)
AlloyDB แก้ปัญหาข้างต้นด้วยการแยกส่วน compute และ storage จากกันอย่างสิ้นเชิง ทั้งสองส่วนสามารถสเกลแบบคลัสเตอร์ได้ และใช้แคชมาคั่นกลางในหลายจุดเพื่อรองรับโหลดแต่ละประเภท
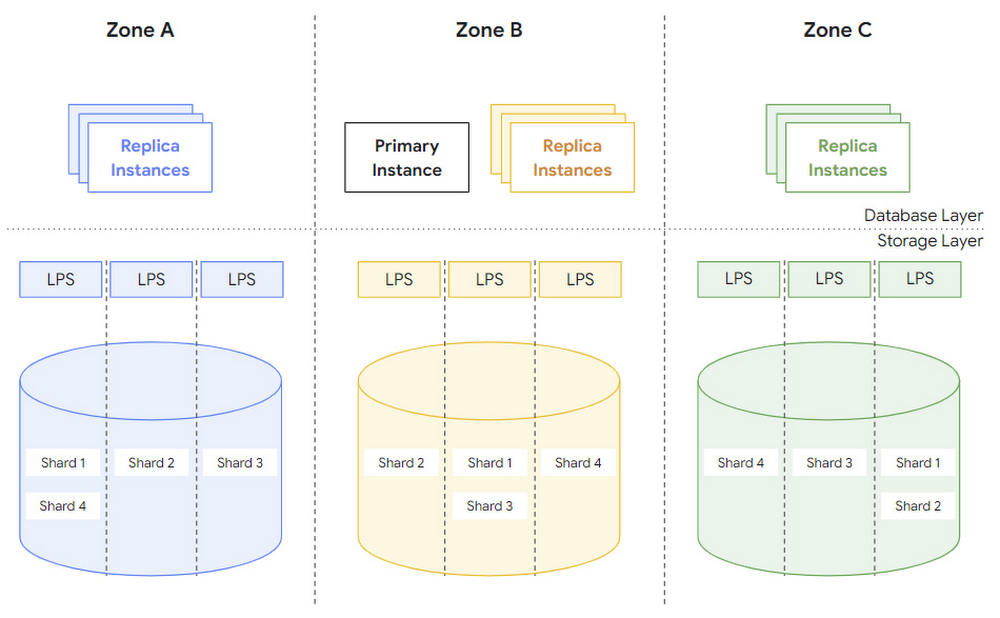
จุดเด่นอย่างหนึ่งของ AlloyDB คือแก้ปัญหาเรื่อง read-only replica หรือการทำซ้ำฐานข้อมูลให้อ่านได้อย่างเดียว (แก้ปัญหาฐานข้อมูลเดียวรองรับโหลดการอ่านไม่ไหว ซึ่งมีข้อจำกัดเรื่องการซิงก์ข้อมูลระหว่าง replica ตามมา) ด้วยการสร้าง multiple read-only replica instances ขึ้นมาหลายๆ ชุด โดยไม่ต้องทำสำเนาฐานข้อมูลจริงๆ
เหตุผลเป็นเพราะ AlloyDB แยกตัวข้อมูลที่เก็บจริง (storage layer) กระจายอยู่หลายๆ โซนของคลาวด์อยู่แล้ว ดังนั้นก็แค่สร้าง replica instance ขึ้นมาหลายๆ ตัว ซึ่งอาจเรียกข้อมูลจริงที่อยู่คนละแห่งกันได้เลย
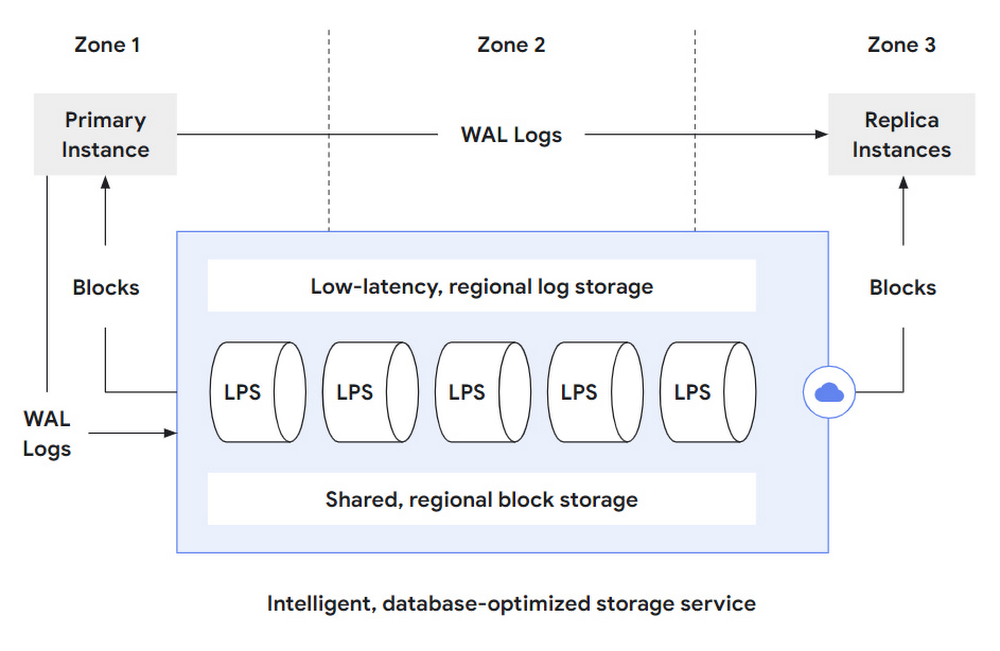
สถาปัตยกรรมส่วน storage layer ของ AlloyDB (กรอบสีฟ้าในภาพ) แยกได้เป็น 3 ส่วนย่อยคือ
- log storage สำหรับเขียน write-ahead log (WAL) แบบรวดเร็วมาก
- log processing service (LPS) เพื่อประมวลผล WAL และสร้างบล็อคสำหรับเก็บข้อมูล
- block storage พื้นที่เก็บข้อมูลจริงๆ โดยมีฟีเจอร์ sharding, แยกเก็บตาม region ของคลาวด์ เพื่อป้องกันปัญหาสตอเรจพังทั้งโซน
จากภาพ เริ่มจาก primary database instance เขียนการเปลี่ยนแปลงของฐานข้อมูล (INSERT/DELETE/UPDATE) เป็น WAL log ส่งเข้ามาที่ log processing service (LPS) ให้ดำเนินการเปลี่ยนแปลงข้อมูลจริงๆ ที่เก็บใน block storage อีกที
จากนั้น บล็อคข้อมูลสามารถถูกส่งให้ replica instance อื่นๆ ได้โดยตรง เมื่อนำมาประกอบเข้ากับ WAL log ที่ส่งมาจาก primary instance เราก็จะได้ replica instance ที่สามารถทำงานได้เหมือนกันทันที โดยไม่ต้องสร้างสำเนาข้อมูลขึ้นมาทั้งก้อน
กูเกิลอธิบายว่า สถาปัตยกรรมนี้แยกส่วน compute/storage จากกันอย่างสิ้นเชิง ในการประมวลผล log (LPS) สามารถ scale-out ต่างหากได้โดยไม่ต้องยุ่งกับการสำเนาข้อมูล ฝั่งการเก็บข้อมูลบล็อค ก็สามารถกระจายความเสี่ยงข้อมูลพังทั้งโซน (zonal failure) โดยสำเนาบล็อคทั้งหมดข้ามโซนของคลาวด์ได้
การแยก compute/storage ด้วยกันยังช่วยแก้ปัญหาคอขวด IO และไม่จำเป็นต้องทำจุด checkpoint ของฐานข้อมูลทั้งก้อน เลเยอร์ของ compute ทำหน้าที่แค่คิวรีงานตามสั่งอย่างเดียว ส่วนเลเยอร์ storage ก็เก็บข้อมูลอย่างเดียว การสั่งแบ็คอัพ ทำที่เลเยอร์ storage ไม่กระทบทรัพยากรที่ใช้ในเลเยอร์ของ compute
รายละเอียดทางเทคนิคเพิ่มเติมอ่านได้จาก Google Cloud
กูเกิลเน้นกลุ่มลูกค้าที่ต้องการย้ายจากฐานข้อมูลแบบเดิมๆ (เช่น Oracle) มายัง AlloyDB ที่เป็นฐานข้อมูลโอเพนซอร์ส แต่มีประสิทธิภาพสูงกว่า และออกบริการช่วยย้ายข้อมูล Oracle to PostgreSQL มาให้พร้อมกัน
ส่วนวิธีคิดเงินของ AlloyDB แยกคิด 3 ส่วน (ตัวอย่างราคาเขต us-central1) คือ
- CPU/memory ($0.06608 / vCPU hour + $0.0112 / GB hour)
- Storage ($0.0004109 per GB)
- Networking (ingress ฟรี, egress ข้ามเขต $0.02/GB)
ที่มา - Google

Get latest news from Blognone
Follow @twitterapi


