By: lew 


 on 27 March 2025 - 01:48
Tags:
on 27 March 2025 - 01:48
Tags:
Topics:
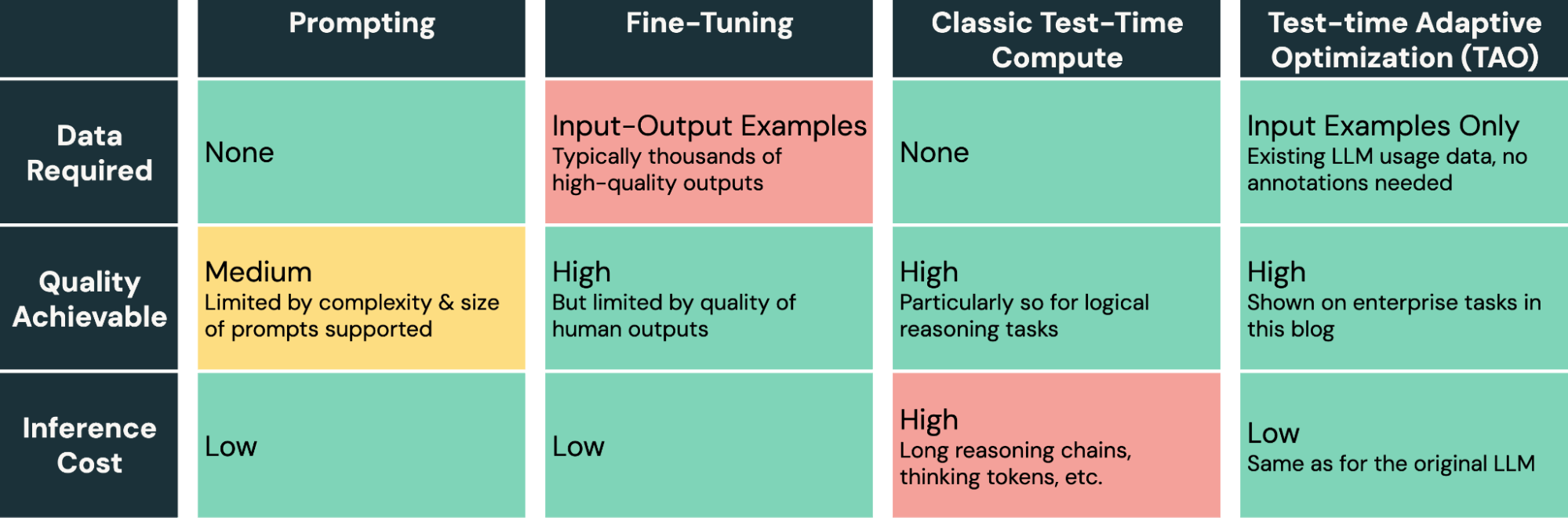
Databricks นำเสนอแนวทางการฝึกโมเดลปัญญาประดิษฐ์แบบ LLM ในชื่อว่า Test-time Adaptive Optimization (TAO) ที่มุ่งเป้าไปยังองค์กรที่ใช้งาน LLM อยู่แล้วแต่ต้องการโมเดลสำหรับใช้งานภายในที่เก่งใกล้เคียงกัน
แนวทางของ TAO แยกออกเป็นสี่ขั้น ได้แก่
- สร้างคำตอบจากพรอมพ์ต่างๆ ที่เคยเก็บการใช้งานในองค์กรไว้ก่อนแล้ว
2.เมื่อโมเดลที่ต้องการฝึกตอบคำตอบตามพรอมพ์ที่ใส่เข้าไปไป ให้คะแนนว่าคำตอบใดมีคุณภาพดี โดยอาจใช้ LLM หรือซอฟต์แวร์อื่นตัดสิน - ฝึกแบบ Reinforcement Learning (RL) ดึงให้โมเดลที่กำลังฝึกทำคะแนนให้ดีที่สุดเท่าที่เป็นไปได้
- เก็บข้อมูลแล้วฝึกซ้ำตั้งแต่ข้อ 1
กระบวนการฝึกแบบ RL ทำให้การฝึกใช้ทรัพยากรสูงขึ้น อย่างไรก็ดี โมเดลที่ได้นั้นใช้ทรัพยากรไม่ต่างจากโมเดลดั้งเดิม โดยไม่ต้องเสียโทเค็นไปกันการคิด
ทาง Databricks เองใช้เทคนิค TAO ในการสร้างโมเดลเพื่อให้บริการลูกค้า เช่น การตอบคำถามจากฐานข้อมูล หรือการแปลงข้อความเป็น SQL แนวทางการฝึกแบบ TAO เปิดทางให้โมเดลท่ี่ได้มีความสามรถใกล้เคียงกับ GPT-4o หรือ o3-mini เลยทีเดียว แม้จะใช้เพียง Llama 3.3 70B หรือหากใช้โมเดลเล็ก Llama 3.1 8B ก็ยังได้ความสามารถระดับเดียวกับ GPT-4o-mini แนวทางนี้ทำให้ต้นทุนการให้บริการลดลงมาก
test-time fine-tuning เป็นแนวทางสำคัญที่ทีมวิจัยจำนวนมากใช้แข่งขัน ARC-AGI ที่มีตัวอย่างให้น้อยมาก โมเดลต้องเรียนรู้จากตัวอย่างเพียง 3-5 ตัวอย่างเท่านั้น
ที่มา - Databricks

Get latest news from Blognone
Follow @twitterapi



Comments
ในการสร้างโมเดล