
การใช้งานคอมพิวเตอร์ทุกวันนี้เรายังคงใช้งานคอมพิวเตอร์ในรูปแบบที่ตรงไปตรงมา เช่น คำนวณสมการคณิตศาสตร์ หรือการประมวลข้อความที่เป็นมีกฎตรงไปตรงมา ข้อดีของคอมพิวเตอร์ที่เราใช้ตลอดมาคือความเร็วที่คอมพิวเตอร์สามารถทำงานซ้ำๆ ได้อย่างรวดเร็วเกินกว่าคนจะทำได้ แต่ในงานที่คนเราทำได้ง่ายๆ เช่น การทำความเข้าใจภาพถ่ายสักภาพมีอะไรอยู่ในภาพบ้างสำหรับคนทั่วไปสามารถทำได้โดยง่าย เราสามารถวงได้ว่าภาพใดมีบ้าน, รถ, หรือวัตถุอื่นๆ ในบ้านได้อย่างรวดเร็วและแม่นยำ แต่กระบวนการเหล่านี้กลับยากมากสำหรับคอมพิวเตอร์
Feature จุดเริ่มต้นของการเรียนรู้
ความพยายามในการพัฒนาให้คอมพิวเตอร์สามารถทำงานได้เหมือนมนุษย์หรือดีกว่าเป็นงานวิจัยที่มีมายาวนาน สิ่งที่เราเรียนรู้คือหากต้องการให้คอมพิวเตอร์ทำความเข้าใจกับข้อมูลที่เราป้อนให้เข้าไป เราต้องสอนให้คอมพิวเตอร์เข้าใจข้อมูลในแบบเดียวกับเรา เช่นว่าหากเรากำลังมองตัวอักษร เราไม่ได้มองจุดขาวหรือจุดดำจุดใดจุดหนึ่งในภาพ แต่เรากำลังมองเส้นของตัวตัวอักษรที่ลากไป แล้วเราจึงเริ่มทำความเข้าใจว่าลายเส้นแบบใด เป็นตัวอักษรใด เราเรียกคุณสมบัติของข้อมูลเช่นนี้ว่าฟีเจอร์ (feature)
ตัวอย่างเช่นใบหน้าคน คนเราสามารถแยกใบหน้าคนออกจากกัน หรือสามารถจำหน้าได้จากรูปวาดที่เป็นการ์ตูน โดยเราแยกแยะจากลักษณะบางอย่างของใบหน้า อาจจะเป็น สัดส่วนระหว่างจมูกกับรูปหน้าโดยรวม ระยะห่างระหว่างตา และข้อมูลอื่นๆ
เราใช้คุณสมบัติคล้ายๆ กันนี้ในการเรียนรู้ข้อมูลอีกหลายอย่าง เช่น เสียงพูด เมื่อเราได้ยินเสียงพูดของคนๆ หนึ่ง เราสามารถบอกได้ว่าเป็นเสียงของเพื่อนของเรา แม้ว่าเราไม่เคยได้ยินเพื่อนของเราพูดประโยคเดียวกันมาก่อนในชีวิต แต่เพราะเราสามารถรับรู้ฟีเจอร์ของเสียง เช่น ความต่ำสูง, ระยะเวลาการออกเสียงต่างๆ, และลักษณะอื่นๆ ที่นักวิจัยก็ยังต้องเรียนรู้กันต่อไป
ที่ผ่านมา นักวิจัยพยายามสอนคอมพิวเตอร์ให้เข้าใจข้อมูลในโลกความเป็นจริง ด้วยการสร้างกฎของการสร้างฟีเจอร์ให้กับข้อมูลแบบต่างๆ ทั้งเรื่องของภาษา, ภาพ, เสียง แต่ละหมวดของข้อมูลเป็นหัวข้อการวิจัยขนาดใหญ่ มีนักวิจัยทั่วโลกนับพันนับหมื่นทำงานวิจัยมาต่อเนื่องนับสิบปีเพื่อให้คอมพิวเตอร์สามารถเข้าข้อมูลได้ใกล้
แต่ Deep Learning ก็เป็นความหวังใหม่ที่จะรวบเอากระบวนวิธีที่คอมพิวเตอร์จะสามารถเข้าใจข้อมูลคล้ายคนมากขึ้น ภายใต้กระบวนการพื้นฐานเดียวกัน
Sparse Coding
จากเดิมที่เราต้องสร้างกระบวนการหาฟีเจอร์ของข้อมูลแต่ละอย่างเป็นการเฉพาะ มีการเสนอกระบวนการหาฟีเจอร์ของข้อมูลที่เรียกว่า Sparse Coding จากข้อมูลที่เราใช้ เช่น ภาพ, เสียง, ภาษา, ไปจนถึงข้อมูลแปลกๆ เช่น สัมผัส
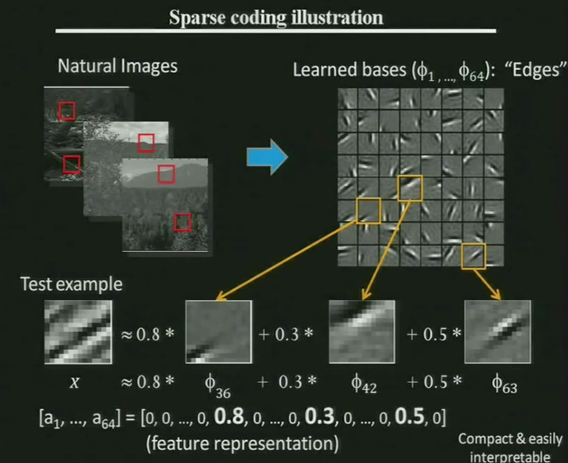
กระบวนวิธี Sparse Coding สามารถสร้างข้อมูลที่เป็นตัวแทนของข้อมูลที่เราแสนใส่เข้า ทำให้ข้อมูลง่ายลง เช่นในภาพจากการนำเสนอของ Andrew Ng นักวิจัยชื่อดังในสาย Deep Learning ในปี 2011 ที่กูเกิล (ขณะนั้น Andrew ยังเป็นอาจารย์ในมหาวิทยาลัยสแตนฟอร์ด) เราสามารถใช้ภาพเพียง 64 ภาพที่สร้างจากการเรียนรู้ข้อมูลแทนข้อมูลที่เป็นพิกเซลได้ เมื่อเราได้ภาพใดๆ มาก็สามารถตัดแบ่งเป็นภาพเล็กๆ แล้วแทนแต่ละส่วนของภาพด้วยตัวเลขของฟีเจอร์
เมื่อเราแปลงภาพจากระดับพิกเซล เป็นส่วนของภาพที่แสดงด้วยข้อมูลที่ง่ายลง เราสามารถทำกระบวนการนี้ซ้ำไปเรื่อยๆ เพื่อหาความหมายของภาพในระดับที่สูงขึ้นไปได้
Deep Learning ความหวังใหม่
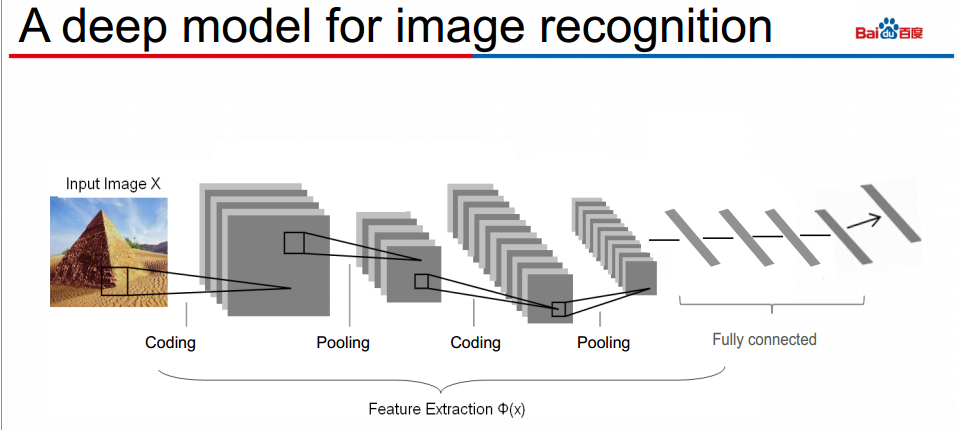
ในกระบวนการเดิมที่เราแปลงภาพให้กลายเป็นฟีเจอร์แบบต่างๆ เมื่อเราทำซ้ำไปเรื่อๆ เราสามารถสร้างโครงข่าย เช่นในภาพของ Andrew Ng เขาแปลงภาพจากระดับพิกเซล เป็นรูปร่างต่างๆ ในภาพเล็กๆ แล้วค่อยๆ แปลงมันเป็นส่วนต่างๆ ของใบหน้า จากนั้นจึงแปลงเป็นใบหน้า
Andrew พบว่าในในความเป็นจริงแล้วเราสามารถใช้ฟีเจอร์ของข้อมูลชนิดเดียวกันในข้อมูลที่ต่างกันไปได้ เช่น เราสามารถใช้ข้อมูลการตรวจจับใบหน้าคน ร่วมกับข้อมูลตรวจจับภาพรถยนต์ เมื่อรวมกันเราสามารถสามารถสร้างโครงข่าย Deep Learning ที่แยกระหว่างรถยนต์ออกจากใบหน้าคนได้
เขานำเสนองานวิจัน โดยสร้างโครงข่ายเรียนรู้ "กิจกรรม" เช่น ภาพคนกำลังกอดกัน, ภาพคนกำลังเดิน ฯลฯ เมื่อนำมาทดสอบพบว่ามีความแม่นยำถึง 52% ดีกว่างานก่อนๆ อย่างมาก
กระบวนการ Deep Learning เดียวกันสามารถใช้เพื่อจดจำและเข้าใจเสียง จากการแปลงภาพ spectrogram ของเสียง และได้กระบวนวิธีจดจำเสียงที่ได้ความแม่นยำดีขึ้นจากงานวิจัยนานนับสิบปีได้อย่างมีนัยสำคัญ Deep Learning สามารถสร้างระบบตรวจเพศของผู้พูด, ตรวจสอบประเภทของเพลง, หรือกระทั่งบอกเจ้าของเพลง โดย Andrew ระบุว่าในทีมวิจัยไม่มีใครเป็นผู้เชี่ยวชาญด้านเสียง มีเพียงนักวิจัยด้าน machine learning อย่างเดียว
การใช้งาน Deep Learning ในโลกความเป็นจริง
กระบวนการ Deep Learning สามารถสร้างแนวทางการใช้งานใหม่ๆ ให้กับคอมพิวเตอร์ได้มากมาย เราสามารถสร้างระบบจดจำเสียงที่ทนทานต่อเสียงรบกวน เช่น ในกรณีของ Baidu สามารถสร้างระบบจดจำเสียงที่แมนยำกว่า 80% แม้จะทำงานในภาพเสียงที่มีเสียงรบกวน

กระบวนการค้นหาจะสามารถหาข้อมูลในรูปแบบที่เราไม่เคยทำได้ในอดีต เราสามารถหาภาพที่ "คล้าย" กับภาพที่ใส่ให้กับระบบ แทนที่จะเป็นการหาภาพที่เหมือนกัน เช่นในตัวอย่าง ระบบค้นหาสามารถค้นหาภาพทุ่งดอกไม้และท้องฟ้าได้ แม้ทุ่งดอกไม้อาจจะเป็นทุ่งดอกไม้คนละสี และท้องฟ้าจะเป็นท้องฟ้าลักษณะต่างกัน เพราะระบบค้นหาทำความเข้าใจกับภาพได้คล้ายมนุษย์มากขึ้น
การแปลภาษาในอนาคตอาจจะแปลภาษาได้ใกล้เคียงนักแปลมืออาชีพขึ้นมาก ทุกวันนี้กระบวนการ Deep Learning สามารถค้นหาประโยคที่คล้ายกัน เช่น สามารถจัดหมวดหมู่ได้ว่าประโยคใดเป็นข่าวร้ายหรือข่าวดี, ประโยคใดเป็นประโยคบอกเล่า กระบวนการเหล่านี้ทำให้เรามีโอกาสเปรียบเทียบกระบวนการแปลจากนักแปลมืออาชีพในแปลประโยคแบบเดียวกัน
DARPA หน่วยงานวิจัยของกองทัพสหรัฐฯ ประกาศระบบ Deep Learning ของตัวเอง ที่ชื่อว่า Deep Exploration and Filtering of Text (DEFT) สามารถวิเคราะห์ถึงภัยจากข้อความที่ได้รับมา ตัวอย่างที่ DARPA แสดงคือคนสองคนสนทนากัน หากคนหนึ่งระบุว่า "ผมแพ้แอปเปิล" และอีกคนเตือนว่า "อย่ากินเค้ก" DEFT จะรับรู้ได้ทันทีว่าในเค้กนั้นมีแอปเปิลผสมอยู่
Deep Learning กับโลกความจริง
การทำงานของ Deep Learning ทุกวันนี้ที่เราเห็นยังคงเป็นบริการออนไลน์ที่เราใช้ผ่านเว็บหรือแอพพลิเคชั่นต่างๆ แต่ในอนาคตเราอาจะจะเริ่มเห็นอุปกรณ์รอบตัวของเราเชื่อมต่อกับคลาวด์ เพื่อเข้าถึงกระบวนการ Deep Learning แล้วสามารถพัฒนาการทำงานไปได้
ตัวอย่างการใช้งานเช่นหุ่นยนต์ในคลังสินค้าที่สามารถเรียนรู้ที่จะปรับแต่งเส้นทางการเดินทางให้สั้นที่สุด เพื่อให้สามารถขนสินค้าได้อย่างมีประสิทธิภาพ หุ่นยนต์ยุคใหม่จะไม่ต้องอยู่บนเส้นที่กำหนดไว้เฉพาะแบบในโรงงานทุกวันนี้อีกต่อไป แต่สามารถใช้ทางเดินร่วมกับคนทั่วไปแต่ยังทำงานได้อย่างรวดเร็วและปลอดภัย
อีกแนวทางการใช้งาน เช่น การแนะนำมนุษย์ให้ทำกิจกรรมบางอย่างได้อย่างมีประสิทธิภาพ เมื่อเดือนที่แล้วทาง Baidu เพิ่งเปิดโครงการ DuBike OS ที่จะช่วยในการขับขี่จักรยาน ตัวจักรยานจะสามารถเลือกเส้นทางให้เราจากแผนที่ไปพร้อมๆ กับความต้องการบางอย่าง เช่น ไม่อยากผ่านเส้นทางที่หนาแน่น, หรือต้องการออกกำลังกายก่อนที่จะไปถึงที่หมาย Deep Learning จะทำให้คอมพิวเตอร์เข้าใจความต้องการที่ซับซ้อนเช่นนี้ จากเดิมที่คอมพิวเตอร์จะเน้นเงื่อนไขที่ตรงไปตรงมาเช่นระยะทางสั้นที่สุด หรือเดินทางเร็วที่สุด การสื่อสารกับผู้ใช้ยังสามารถใช้ระบบจดจำเสียงที่มีความแม่นยำสูง
กระบวนการ Deep Learning เป็นงานที่กำลังเข้ามาในชีวิตประจำวัน เมื่อคอมพิวเตอร์สามรถเข้าใจบริบทที่มนุษย์เข้าใจได้ไม่ยากนัก แต่ยังคงความสามารถในการทำงานทำงานอัตโนมัติที่รวดเร็วและมีประสิทธิภาพ ในอนาคตนวัตกรรมที่เกิดขึ้นใหม่ๆ คงมีอะไรให้เราเรียนรู้กันอีกมา

Get latest news from Blognone
Follow @twitterapi



Comments
เขานำเสนองานวิจัน > เขานำเสนองานวิจัย
onedd.net
การใช้ไม้ยมก
เมื่อเราทำซ้ำไปเรื่อๆ => เมื่อเราทำซ้ำไปเรื่อย ๆ
แม้จะทำงานในภาพเสียงที่มีเสียงรบกวน => แม้จะทำงานในสภาพเสียงที่มีเสียงรบกวน
เมื่อคอมพิวเตอร์สามรถเข้าใจ => เมื่อคอมพิวเตอร์สามารถเข้าใจ
คงมีอะไรให้เราเรียนรู้กันอีกมา => คงมีอะไรให้เราเรียนรู้กันอีกมาก
ผมว่า ไปตู้ นี่เป็น บ.ที่มีนวัตกรรม มากเหมือนกันนะ
หลายๆอย่างใช้ได้เลย เสียตรงชื่อฉาวนี่ละ
+1
+1
อะไรๆ ก็ดี ... ถ้าไม่เห็นโลโก้
ก็ว่าจะอ่านถึงจะเป็นแอดก็เถอะ พอเห็นรูปหัวข่าวผมนี่ถึงกับสะอึกเลย
อะไรที่มาจากแบรนด์นี้เห็นแล้วไม่กล้าใช้อ่ะ ต่อให้ทำมาดีแค่ไหนก็ไม่เอาจริงๆ กลัวลงตัวเดียวแล้วเพื่อนๆจะตามมาทั้งโคลง
Baidu Anti Virus ยังไม่เคลียร์เลยครับ
ผมว่าเคลียร์แล้วนะ
เคลียร์ว่ามันเป็น ไวรัสที่อำพลางตัวมาในรูปตัวแสกนไวรัส :P
30 กพ เคลียร์แน่นอน
เคลียร์ตรงไหนครับ ออกมาแถลงข่าวโบ๊ยคนอื่น ไม่ได้รับผิดชอบอะไร ก่อนหน้าก็ให้รายการไอทีมาด่าชาวบ้านว่าลงวินโดว์เถื่อนอีก แบบนี้มันเคลียร์เหรอครับ
+1024
ก็เคลียอยู่นะครับ เคลียข้อมูลในเครื่อง
เจ็บมาจริง
เมื่อทำดีก็สมควรชม
จะเหมือนเรื่อง rockman ไหม
อ่านแล้วเข้าใจว่า Google วิจัย Baidu พัฒนา?
Andrew Ng นักวิจัยอันดับต้นๆ ของสายนี้เพิ่งย้ายจากกูเกิลไปไป่ตู้มาครึ่งปีครับ
lewcpe.com, @wasonliw
วันนี้ผมไประยองเพื่อติดตั้ง webapp ที่ทีมงานผมพัฒนาขึ้น ไปเครื่อง user เจอ baitu spark 555.in.th ผมไม่มีวันให้อภัย..ลาก่อย โครตเกลียด
ชาตินี้ไม่มีวันใช้แน่นอน ทำไว้แสบมาก
มี Deep Speech แล้ว รอบนี้มี Deep Learning...
ต่อไปจะ Deep อะไร...?
แต่ต่อให้ Deep แค่ไหนก็ไม่กล้าใช้...
เพราะความประทับใจแรกของเจ้าน่ะ มันตายไปแล้ว!!
Deep T***** /เผ่นก่อน
Deep Thought สินะครับ
ไปดูมาพูดเรื่องนี้เนี่ยนะ ไม่ติดที่เอารูปแฟนผมมาพูดด้วยนะ ด่ากระเจิง อิอิ
กลัวถูกบังคับให้ดีพจัง ยุคนี้ด้วยแล้ว
หากมันทำงานได้จริงก็น่านับถือครับ แต่ผมว่า ... โม้ มากกว่าครับ
ดูจาก Alpha Go นี่ยอมรับเลย ต่อไปก็เริ่มเล่นเกมที่ซับซ้อนขึ้น
อย่าง Dota2 / LOL เล่นได้นี่นับถือเลยฮะ เล่นดีดีนะ 555
เจเนซิส , รวงผึ้ง , แมทริกซ์
แมนยำ => แมนยูโดนยำ