By: neizod 

 on 5 March 2016 - 16:54
Tags:
on 5 March 2016 - 16:54
Tags:
Topics:

Git เป็นระบบจัดการซอร์ส (source code management หรือบางที่ก็เรียกว่า version control system) ตัวหนึ่งที่ได้รับความนิยมจากนักพัฒนาซอฟต์แวร์ในปัจจุบัน เพียงแค่หน้าที่หลักของมันในการติดตามการเปลี่ยนแปลงและเรียกคืนไฟล์ตามช่วงเวลาต่างๆ ก็ทำให้การทำงานโดยใช้ Git บริหารไฟล์มีประสิทธิภาพมากขึ้นหลายเท่าตัว
ประวัติศาสตร์และแนวคิดของระบบจัดการซอร์ส
ยุคก่อนระบบจัดการซอร์ส
ตั้งแต่คอมพิวเตอร์ส่วนบุคคลเริ่มแพร่หลายในช่วงทศวรรษที่ 1970 การสร้างสรรค์ผลงานผ่านคอมพิวเตอร์นั้น จะเกี่ยวข้องกับการแก้ไขไฟล์แทบทั้งสิ้น ชิ้นงานง่ายๆ ขนาดเล็ก อาจถูกสร้างสรรค์จนเสร็จสิ้นในช่วงระยะเวลาสั้นๆ ภายใต้การเปิดโปรแกรมแก้ไขไฟล์ขึ้นมาทำงานเพียงครั้งเดียวเท่านั้น
ส่วนชิ้นงานที่มีความซับซ้อนและต้องใช้ระยะเวลาแก้ไขไฟล์นานขึ้น หากเกิดการแก้ไขที่ผิดพลาดระหว่างใช้โปรแกรมแก้ไขไฟล์ ผู้ใช้ก็ยังสามารถเรียกคืนรุ่นก่อนหน้ากลับมาได้ผ่านการสั่งเลิกทำ (undo) ซึ่งโปรแกรมแก้ไขไฟล์แต่ละโปรแกรมก็สามารถจดจำรุ่นก่อนหน้าได้ไม่เท่ากัน เช่น โปรแกรมวาดภาพ Paint บนระบบปฏิบัติการ Windows XP สามารถย้อนกลับไปยังรุ่นก่อนหน้าได้ไกลที่สุดเพียง 3 รุ่น หรือโปรแกรมแก้ไขไฟล์อย่าง vi ที่สามารถย้อนกลับได้แบบสลับที่เท่านั้น ซึ่งก็คือสามารถย้อนกลับได้เพียงรุ่นเดียว หากสั่งย้อนกลับซ้ำอีกครั้งจะกลายเป็นการเรียกคืนรุ่นล่าสุดแทน
แต่หากผู้ใช้สั่งบันทึกและปิดโปรแกรมแก้ไขไฟล์ไปแล้ว เมื่อเรียกไฟล์ขึ้นมาแก้ไขอีกครั้ง ผู้ใช้จะไม่สามารถย้อนกลับไปยังรุ่นก่อนหน้าได้อีก นั่นก็เพราะว่าไฟล์รุ่นล่าสุดที่มีการแก้ไขและบันทึกไปนั้น ถูกคอมพิวเตอร์จัดเก็บทับลงไปในหน่วยความจำเดิมที่เคยใช้เก็บไฟล์รุ่นก่อนหน้านั่นเอง
ดังนั้นเมื่อผู้ใช้เกิดอาการไม่แน่ใจว่า ชิ้นงานที่ทำเพิ่มเติมเป็นรุ่นใหม่จะดีกว่าของเดิมหรือไม่ ผู้ใช้ต้องบอกให้คอมพิวเตอร์บันทึกไฟล์ลงในตำแหน่งใหม่บนหน่วยความจำ หรือไม่เช่นนั้นก็ต้องคัดลอกไฟล์รุ่นเดิมเก็บแยกไว้ต่างหาก ซึ่งอาจส่งผลให้แฟ้มที่เก็บชิ้นงานดังกล่าว มีโครงสร้างดังรูปที่ 1 และ 2

รูปที่ 1: จัดเก็บไฟล์รุ่นใหม่โดยการตั้งชื่อ
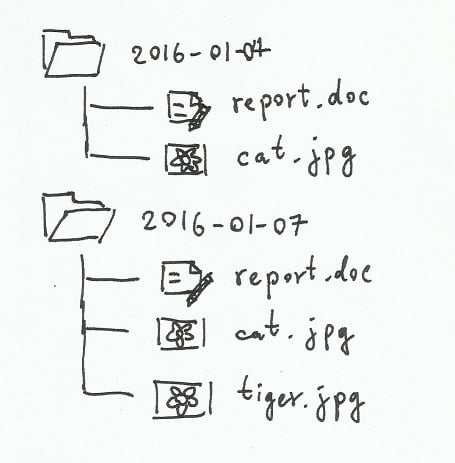
รูปที่ 2: จัดเก็บไฟล์แยกรุ่นด้วยแฟ้มวันที่
จะเห็นว่า การเก็บไฟล์ด้วยการตั้งชื่อตามรูปที่ 1 มีข้อเสียที่ชื่อไฟล์มีความกำกวม เช่น ผู้ใช้ไม่สามารถแยกไฟล์ที่ลงท้ายด้วยคำว่า “ล่าสุด” กับ “สุดท้าย” ได้ว่า ไฟล์ไหนเป็นไฟล์ที่ใหม่กว่ากัน หรือไม่สามารถบอกได้ว่าไฟล์ดังกล่าวถูกพัฒนาต่อยอดขึ้นมาจากไฟล์ไหนในรุ่นก่อนหน้า
ส่วนการแยกรุ่นไฟล์ตามแฟ้มวันที่ดังรูปที่ 2 ก็มีปัญหาตรงที่ผู้ใช้ไม่สามารถบอกได้โดยง่ายว่า ไฟล์รุ่นนั้นๆ สำคัญอย่างไร มีการเปลี่ยนแปลงอะไรเกิดขึ้นบ้าง ทำให้การค้นหาไฟล์ที่ถูกต้องเมื่อต้องการเรียกคืนรุ่นเดิมนั้นยุ่งยากมาก
นอกจากนี้แล้ว การเก็บไฟล์ด้วยวิธีทั้งสองข้างต้น ยังสิ้นเปลืองพื้นที่จัดเก็บโดยใช่เหตุอีกด้วย เช่น การเก็บไฟล์นำเสนองานรุ่นใหม่ที่มีการเปลี่ยนแปลงสไลด์เพียงไม่กี่หน้า หรือการต้องคัดลอกไฟล์รูปภาพขนาดใหญ่ที่ไม่มีการแก้ไขไปวางไว้ในทุกแฟ้มที่อ้างถึงไฟล์รูปภาพไฟล์นั้น
ผู้ใช้ที่ตระหนักถึงข้อจำกัดบางประการข้างต้น อาจใช้เครื่องมือตรวจสอบจุดที่มีการเปลี่ยนแปลงระหว่างรุ่น แล้วจัดเก็บเพียงแค่ส่วนต่างเหล่านั้นในรูปของแพตช์ (patch) เพื่อลดการใช้พื้นที่จัดเก็บอย่างซ้ำซ้อน เช่น การเก็บรุ่นของระบบปฏิบัติการ Linux ในยุคแรก

รูปที่ 3: ตัวอย่างแพตช์ระหว่างไฟล์ 2 รุ่น
รูปที่ 3 แสดงถึงตัวอย่างแพตช์ที่สร้างจากโปรแกรม GNU Diff โดยมีไฟล์รุ่นเก่าและใหม่ วางเปรียบเทียบไว้ทางด้านซ้ายและขวาตามลำดับ แพตช์ที่สร้างออกมาจะแสดงถึงบรรทัดที่มีการเปลี่ยนแปลงเกิดขึ้น โดยใช้เครื่องหมาย < นำหน้าบรรทัดที่หายไป และเครื่องหมาย > สำหรับบรรทัดที่เพิ่มเข้ามา
แม้การเก็บรุ่นด้วยแพตช์จะแก้ปัญหาการใช้หน่วยความจำอย่างสิ้นเปลืองได้ แต่ก็แลกมากับความเสี่ยงที่ต้องดูแลแพตช์ทั้งหมดเป็นอย่างดี การทำแพตช์บางรุ่นเสียหาย นอกจากจะทำให้ไม่สามารถเรียกคืนรุ่นนั้นกลับมาได้แล้ว อาจส่งผลให้ไม่สามารถย้อนกลับไปยังรุ่นก่อนหน้านั้นทั้งหมดได้อีกด้วย
ยุคระบบจัดการซอร์สแบบเฉพาะที่ (Local Version Control System)
RCS (Revision Control System) เป็นระบบแรกที่เกิดขึ้นมาในปี 1982 เพื่อแก้ไขปัญหาข้างต้นทั้งหมด โดยหลักการทำงานคร่าวๆ ของมัน จะเริ่มจากสร้างฐานข้อมูลรุ่น แล้วจึงจัดเก็บ (check-in) ชิ้นงานพร้อมข้อความช่วยจำ (log message) ลงฐานข้อมูลนั้น เมื่อผู้ใช้ต้องการทำงานต่อยอด ก็เริ่มจากเรียกคืน (check-out) ชิ้นงานออกมาจากฐานข้อมูลก่อน หลังจากปรับปรุงชิ้นงานเรียบร้อยแล้วจึงสั่งจัดเก็บชิ้นงานกลับลงฐานข้อมูลอีกครั้ง การทำงานดังกล่าวสามารถอธิบายด้วยแผนภาพกรณีใช้งาน (use case diagram) ได้ตามรูปที่ 4
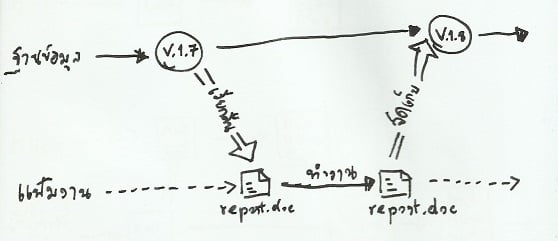
รูปที่ 4: หลักการทำงานโดยสังเขปของระบบจัดการซอร์ส RCS
ถึงปัญหาเก่าๆ จะหมดไป แต่ RCS ก็ได้เปิดเผยปัญหาใหม่ขึ้นมาแทน เพราะเหตุการณ์ทั้งหมดที่เราคำนึงถึงนั้น เป็นการพัฒนาชิ้นงานโดยผู้ใช้คนเดียวทั้งสิ้น หากลองพิจารณาเหตุการณ์ที่มีคนสองเรียกคืนชิ้นงานออกมาสร้างสรรค์ต่อยอดพร้อมกัน ฝ่ายที่ทำงานเสร็จและจัดเก็บชิ้นงานก่อน จะสูญเสียเนื้อหาส่วนที่ได้แก้ไขในชิ้นงานรุ่นต่อไป เมื่ออีกฝ่ายจัดเก็บชิ้นงานที่ทำเสร็จทีหลังลงฐานข้อมูล
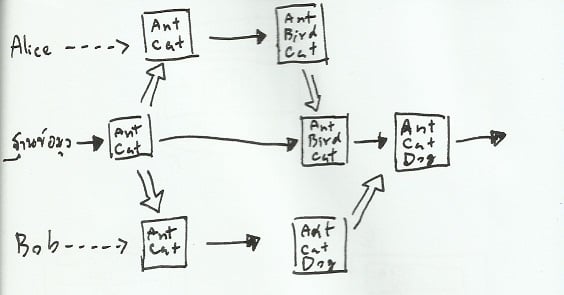
รูปที่ 5: การสูญเสียข้อมูลของชิ้นงานรุ่นล่าสุด เมื่อทำงานพร้อมกันหลายคน
รูปที่ 5 แสดงถึงการเรียกคืนชิ้นงานออกมาทำพร้อมกันของ Alice และ Bob ในเหตุการณ์นี้ Alice เป็นคนที่ทำงานเสร็จและจัดเก็บชิ้นงานกลับลงฐานข้อมูลก่อน แต่เมื่อ Bob ทำงานส่วนของตนเสร็จสิ้นและจัดเก็บชิ้นงานตามมา ระบบจัดการซอร์สจะมองว่า เนื้อหาที่เพิ่งเพิ่มเติมโดย Alice ถูกลบทิ้งโดย Bob ทำให้ชิ้นงานผลลัพธ์มีแต่เนื้อหาที่ถูกเพิ่มเติมจาก Bob เท่านั้น
แม้เหตุการณ์นี้อาจไม่สามารถเกิดขึ้นได้จริงกับ RCS เนื่องจากระบบดังกล่าวจะล็อกฐานข้อมูลไว้ไม่ให้ผู้ใช้ที่ทำงานเสร็จช้ากว่าสามารถจัดเก็บชิ้นงานตามหลังได้ แต่ข้อจำกัดดังกล่าวก็กลับกลายเป็นจุดอ่อนอันยิ่งใหญ่ในโลกความเป็นจริง เมื่อการทำงานพร้อมกันหลายคนเป็นสิ่งที่ยากจะหลีกเลี่ยง
ยุคระบบจัดการซอร์สแบบรวมศูนย์ (Centralized Version Control System)
ระบบจัดการซอร์สในยุคถัดมา จึงพยายามทำให้การทำงานพร้อมกันหลายคนเป็นไปได้ โดยเริ่มจากแนวคิดที่ว่า ใช้เซิร์ฟเวอร์ศูนย์กลาง 1 ตัว ทำหน้าที่เป็นคลังข้อมูลชิ้นงาน (repository) โดยคลังข้อมูลดังกล่าว นอกจากจะทำหน้าที่เก็บฐานข้อมูลชิ้นงานแล้ว ยังมีหน้าที่ในการจัดเก็บรุ่นใหม่ๆ ลงฐานข้อมูล และเรียกคืนรุ่นเก่าออกมาเมื่อถูกร้องขออีกด้วย
ผู้ใช้แต่ละคนที่ทำงานบนระบบดังกล่าว จะส่งคำสั่งเรียกคืนรุ่นที่ต้องการไปยังคลังข้อมูลกลาง เพื่อเรียกคืนชิ้นงานรุ่นนั้นออกมาทำงานต่อยอด เมื่อทำงานสำเร็จและสั่งจัดเก็บชิ้นงาน คลังข้อมูลจะตรวจเช็กเนื้อหาส่วนที่เปลี่ยนแปลงเทียบกับรุ่นที่ผู้ใช้คนนั้นๆ เรียกคืนออกไป แล้วบันทึกส่วนต่างลงฐานข้อมูล
ด้วยวิธีการนี้ เมื่อมีผู้ใช้หลายคนจัดเก็บชิ้นงานพร้อมกัน คลังข้อมูลจะพยายามรวมเนื้อหา (merge) ของผู้ใช้ทั้งหลายเข้าด้วยกัน หากเนื้อหาที่นำมารวมกันนั้นอยู่ในรูปแบบที่เรียบง่ายมากพอ ระบบจะรวมเนื้อหาดังกล่าวให้โดยอัตโนมัติ แต่หากเนื้อหามีความซับซ้อนคาบเกี่ยวกันจนระบบไม่สามารถรวมเนื้อหาให้เองได้ ผู้ใช้จะถูกถามว่าต้องการเลือกเก็บเนื้อหาใหม่อย่างไร ซึ่งไม่ว่าจะทางไหน ขั้นตอนการทำงานวิธีนี้ สามารถรับประกันได้ว่า ผู้ใช้คนที่ส่งงานช้ากว่าจะไม่เผลอลบเนื้อหาจากผู้ใช้คนก่อนโดยไม่ตั้งใจอย่างแน่นอน
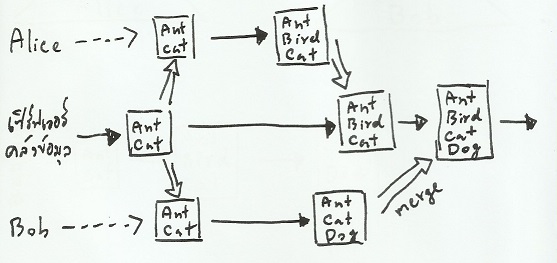
รูปที่ 6: การรวมเนื้อหาของชิ้นงานรุ่นล่าสุด เมื่อทำงานพร้อมกันหลายคน
รูปที่ 6 แสดงถึงเหตุการณ์เมื่อผู้ใช้เรียกคืนชิ้นงานออกมาทำพร้อมกัน 2 คน เหตุการณ์ดังกล่าวมีความคล้ายคลึงกับเหตุการณ์ในรูปที่ 5 ยกเว้นตอนท้ายสุดเมื่อ Bob ซึ่งเป็นคนทำงานเสร็จทีหลัง Alice จัดเก็บชิ้นงานกลับคลังข้อมูล ระบบจะทำการรวมเนื้อหาส่วนที่เพิ่มขึ้นมาทั้งจาก Alice และ Bob เข้าด้วยกันโดยอัตโนมัติ ทำให้ไฟล์ผลลัพธ์มีเนื้อหาครบถ้วนไม่ตกหล่น ไม่ว่าใครจะทำงานเสร็จก่อนหรือหลังก็ตาม
จะเห็นได้ว่า ความสามารถในการรวมเนื้อหาจากผู้ใช้หลายคน เป็นความสามารถที่มีความสำคัญอย่างยิ่งยวดในระบบจัดการซอร์สสำหรับทำงานพรอ้มกันหลายคน
ระบบจัดการซอร์สแบบรวมศูนย์ที่ได้รับความนิยมอย่างมาก คือ CVS (Concurrent Version System) ที่ออกมาเมื่อปี 1990 แม้แนวคิดด้านการทำงานพร้อมกันหลายคนจะดีแล้ว แต่ขั้นตอนการรวมเนื้อหาก็ยังมีความยุ่งยากอยู่ ระบบถัดมาที่พยายามแก้ไขความไม่สมบูรณ์ดังกล่าวในปี 2000 คือ Subversion (มักย่อกันว่า SVN) และมันก็ยังได้รับความนิยมอยู่จนถึงทุกวันนี้
ยุคระบบจัดการซอร์สแบบกระจายศูนย์ (Distributed Version Control System)
แม้ระบบจัดการซอร์สแบบรวมศูนย์จะมีความสามารถครบถ้วนสมบูรณ์เพียงพอต่อการใช้งานแล้ว แต่ด้วยแนวคิดแบบรวมศูนย์ของมันนั่นเอง ที่กลับกลายมาเป็นปัญหาจุดเดียวของความล้มเหลว (single point of failure) ไปเสียได้ กล่าวคือ หากเซิร์ฟเวอร์ที่เก็บชิ้นงานล่มไปชั่วขณะ ผู้ใช้จะไม่สามารถจัดเก็บหรือเรียกคืนชิ้นงานในช่วงเวลานั้นได้ และหากเซิร์ฟเวอร์เสียหายจนไม่สามารถกู้ข้อมูลได้ ผู้ใช้ก็แทบจะสูญเสียประวัติทั้งหมดของชิ้นงานชิ้นนั้นไปเลยทีเดียว
เพื่อแก้ปัญหาดังกล่าว ระบบจัดการซอร์สแบบรวมศูนย์อาจนำเซิร์ฟเวอร์สำรอง (redundant server) ซึ่งมีข้อมูลเหมือนกันกับเซิร์ฟเวอร์หลักทุกประการ มาใช้งานยามฉุกเฉินเมื่อเซิร์ฟเวอร์หลักเสียหาย แต่การใช้เซิร์ฟเวอร์สำรองก็ยังไม่สามารถรับประกันการเข้าถึงประวัติชิ้นงานได้ตลอดเวลาอยู่ดี เช่น ทั้งเซิร์ฟเวอร์หลักและสำรองต่างเสียหายในเวลาเดียวกัน หรือการขาดแคลนซึ่งระบบเครือข่าย (network) ทำให้ไม่สามารถติดต่อกับเซิร์ฟเวอร์ที่เก็บคลังข้อมูลชิ้นงานได้ นี่จึงเป็นที่มาของแนวคิดระบบจัดการซอร์สแบบกระจายศูนย์ ที่จะคัดลอกประวัติชิ้นงานทั้งหมดมาไว้ยังเครื่องของผู้ใช้ เพื่อให้ผู้ใช้สามารถเข้าถึงประวัติชิ้นงานได้ตลอดเวลา โดยลดจำนวนครั้งที่ต้องการติดต่อกับเซิร์ฟเวอร์ลง เหลือเพียงเมื่อต้องการส่งงานที่ปรับปรุงแก้ไขไปให้เพื่อนร่วมงานเท่านั้น
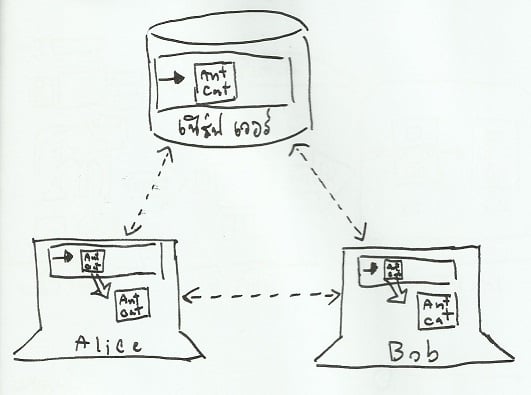
รูปที่ 7: โครงสร้างโดยสังเขปของระบบจัดการซอร์สแบบกระจายศูนย์
รูปที่ 7 แสดงถึงการใช้ระบบจัดการซอร์สแบบกระจายศูนย์ที่มีผู้ใช้ 2 คน ผู้ใช้แต่ละคนจะคัดลอกคลังข้อมูลชิ้นงานทั้งหมดจากเซิร์ฟเวอร์มาเก็บไว้ในเครื่องตนเอง ทำให้สามารถเข้าถึงประวัติชิ้นงานได้ตลอดเวลาแม้จะขาดการเชื่อมต่อ นอกจากนี้แล้ว ผู้ใช้ยังสามารถส่งข้อมูลให้กันเองโดยไม่ต้องผ่านเซิร์ฟเวอร์ก็ย่อมได้
ผลพลอยได้จากการยินยอมให้เครื่องแต่ละเครื่องเก็บประวัติชิ้นงานทั้งหมดนั้น นอกจากจะทำให้แต่ละเครื่องเปรียบเสมือนที่สำรองไฟล์ชิ้นงานแล้ว การทำงานหลายๆ อย่างยังมีความเร็วสูงขึ้นอย่างมีนัยสำคัญ และเปิดมิติใหม่ในการใช้ระบบจัดการซอร์สช่วยสร้างสรรค์ชิ้นงานอีกด้วย
ระบบจัดการซอร์สแบบกระจายศูนย์ที่ขึ้นชื่อนอกจาก Git ได้แก่ BitKeeper จากปี 1998 ที่เป็นแรงบันดาลใจสำคัญให้แก่ Git และ Mercurial จากปี 2005 คู่แข่งรายสำคัญซึ่งมีจุดขายเป็นส่วนติดต่อผู้ใช้ที่ดูเป็นมิตรและสง่างามกว่านั่นเอง
ประวัติความเป็นมาของ Git
สำหรับประวัติของ Git นั้น อาจเล่าย้อนกลับไปได้ไกลถึงจุดเริ่มต้นของโครงการ Linux เลยทีเดียว เมื่อ Linus Torvalds ผู้ริเริ่มโครงการ Linux ตัดสินใจเก็บรุ่นต่างๆ ของโครงการด้วยแพตช์เท่านั้น เนื่องจากเขาไม่นิยมระบบจัดการซอร์สแบบรวมศูนย์อย่าง CVS

รูปที่ 8: Linus Torvalds บิดาแห่งระบบปฏิบัติการ Linux และระบบจัดการซอร์ส Git
ผ่านไปราวหนึ่งทศวรรษ เมื่อถึงปี 2002 Linus ได้ตัดสินใจนำ BitKeeper มาใช้กับโครงการ Linux เหตุการณ์เป็นไปอย่างเรียบร้อยดีจนกระทั่งปี 2005 เมื่อ Larry McVoy เจ้าของ BitKeeper ยกเลิกสัญญาการใช้งานฟรีแก่ชุมชน Linux เพราะเขาไม่พอใจที่ Andrew Tridgell ทำวิศวกรรมผันกลับ (reverse engineering) บนโพรโทคอลของ BitKeeper เพื่อศึกษาว่ามันทำงานอย่างไร
เมื่อขาดระบบจัดการซอร์สที่ดี และไร้ซึ่งวี่แววของระบบที่ใช้งานได้อย่างทัดเทียมกัน Linus จึงตัดสินใจสร้างระบบดังกล่าวขึ้นมาเองในวันที่ 3 เมษายน 2005 การพัฒนาเป็นไปอย่างรวดเร็วเพราะเพียงวันที่ 16 มิถุนายน Git ก็เสถียรพอที่ถูกใช้เพื่อจัดการซอร์สของ Linux รุ่นที่ 2.6.12 แล้ว เมื่อเป็นที่พอใจในผลลัพธ์ Linus ได้ยกหน้าที่ดูแลโครงการ Git ให้ Junio Hamano นักพัฒนาคนสำคัญเข้ารับช่วงต่อในวันที่ 26 กรกฎาคม และเพียงแค่ครึ่งปี Git รุ่น 1.0 ซึ่งถือเป็นรุ่นเสถียรสำหรับการใช้งานโดยบุคคลทั่วไป ก็ได้ฤกษ์เปิดตัวแก่ชาวโลก ณ วันที่ 21 ธันวาคม 2005

รูปที่ 9: Junio Hamano ผู้ดูแลโครงการ Git คนปัจจุบัน
ปัจจุบันมีเว็บฝากซอร์สออนไลน์จำนวนมากที่รองรับ Git ควบคู่ไปกับระบบจัดการซอร์สตัวอื่น และก็มีเว็บไซต์อีกไม่น้อยที่รองรับแต่ Git เพียงอย่างเดียว เว็บไซต์บางเว็บเช่น GitHub นั้น นอกจากจะทำหน้าที่รับฝากซอร์สโปรแกรมแล้ว ยังเป็นแหล่งชุมชนสำหรับนักพัฒนาอีกด้วย นักพัฒนาบางคนอาจเลือกฝากซอร์สโครงการที่ตนเองดูแลแบบเปิดเผยต่อสาธารณะ เพื่อสร้างโพรไฟล์ของตนเองให้เป็นที่รู้จักในชุมชนพัฒนานั้นๆ
เกร็ดทิ้งท้ายสำหรับ Git คือชื่ออันแสนประหลาดของมันนั่นเอง ถ้าใครคุ้นเคยกับสแลงภาษาอังกฤษแบบบริติช อาจรู้สึกตกใจไม่น้อยเมื่อได้ยินคำดังกล่าวถูกนำไปตั้งเป็นชื่อโปรแกรม เพราะ git สามารถแปลได้ว่า “คนที่ไม่มีใครคบ” หรือจะแปลว่า “คนโง่” ก็ย่อมได้ โดย Linus ออกมาอธิบายว่าเขาตั้งชื่อโครงการต่างๆ ตามหลังตัวเขา ซึ่งได้แก่ โครงการ Linux ที่ตั้งชื่อเลียนเสียงกับชื่อต้นของเขา และโครงการ Git ที่ตั้งชื่อตามนิสัยมุทะลุของเขา ส่วนใครที่ไม่ประทับใจในที่มาของชื่อนี้ Linus ได้เล่นมุกว่า ให้มองว่าชื่อดังกล่าวเป็นคำย่อของ Global Information Tracker แทนก็ย่อมได้
แนวคิดสำคัญของ Git
ในเมื่อ Git ก็เป็นระบบจัดการซอร์สตัวหนึ่ง แล้วระบบจัดการซอร์สตัวนี้มีกลไลการทำงานอย่างไรบ้าง ยิ่งไปกว่านั้น อะไรที่ทำให้ Git แตกต่างออกไปจากระบบจัดการซอร์สตัวอื่นๆ นอกจากข้อเท็จจริงที่ว่า Linus Torvalds เป็นผู้สร้างแล้ว ยังมีคุณลักษณะอย่างอื่นที่ช่วยขับให้ Git เฉิดฉายหรือไม่ หัวข้อนี้จะแจกแจงแนวคิดและคุณสมบัติต่างๆ เพื่อความเข้าใจอย่างถ่องแท้ว่า อะไรคือ Git และอะไรที่ทำให้มันโดดเด่น
เก็บภาพชั่วขณะของรุ่น ไม่ใช่ส่วนต่างระหว่างรุ่น
เราได้ตั้งข้อสังเกตไปแล้วว่า ระบบจัดการซอร์สโดยทั่วไป มีแนวคิดการจัดเก็บรุ่นด้วยการเก็บเพียงแค่ส่วนต่างระหว่างรุ่น อย่างไรก็ตาม Git ได้เปลี่ยนมุมมองการจัดเก็บรุ่นไปเป็นการเก็บภาพชั่วขณะ (snapshot) ของไฟล์ทั้งหมดแทน นั่นหมายถึงทุกครั้งที่มีการแก้ไขไฟล์และจัดเก็บมันเข้าระบบ Git จะบันทึกเนื้อหาของไฟล์นั้นทั้งไฟล์ ไม่ใช่แค่ส่วนต่างเทียบเมื่อเทียบกับรุ่นก่อนหน้า พฤติกรรมดังกล่าวสามารถอธิบายได้โดยรูปที่ 10

รูปที่ 10: แนวคิดการมองภาพรุ่นของ Git เมื่อเทียบกับระบบอื่นๆ
ดังนั้น การมองประวัติของรุ่นที่ถูกจัดเก็บใน Git จะเปรียบเหมือนการมองภาพชั่วขณะของรุ่นต่างๆ ที่ถูกร้อยเรียงเข้าด้วยกัน ไม่ใช่การมองแค่ภาพส่วนต่างที่เปลี่ยนแปลงระหว่างรุ่นดังเช่นระบบจัดการซอร์สอื่นๆ
อย่างไรก็ตาม นี่เป็นแนวคิดในระดับบนของ Git เพื่อให้ผู้ใช้สามารถทำความเข้าใจกับการเก็บรุ่นได้ง่ายและชัดเจนเท่านั้น การจัดเก็บไฟล์ในระดับล่างยังคงเป็นการเก็บส่วนต่างระหว่างรุ่นที่มีประสิทธิภาพด้านการใช้หน่วยความจำอยู่ดี ผู้ใช้จึงไม่จำเป็นต้องห่วงเรื่องการใช้พื้นที่อย่างฟุ่มเฟือยแต่อย่างใด
3 สถานะของการจัดเก็บไฟล์
เมื่อพูดถึงสถานะของไฟล์ที่ถูกจัดเก็บด้วยระบบจัดการซอร์ส เราอาจแบ่งได้อย่างเรียบง่ายออกเป็น 2 สถานะ ได้แก่ ไฟล์ที่ถูกจัดเก็บลงคลังข้อมูลชิ้นงานเรียบร้อยแล้ว กับไฟล์ที่ยังไม่ถูกจัดเก็บลงคลังข้อมูลชิ้นงาน นี่เป็นแนวคิดโดยทั่วไปของระบบจัดการซอร์สส่วนใหญ่ แต่สำหรับ Git แล้ว ยังมีสถานะพิเศษเพิ่มขึ้นมาคั่นกลางระหว่างสถานะทั้งสอง ซึ่งก็คือ ไฟล์ที่กำลังจะถูกจัดเก็บลงคลังข้อมูลชิ้นงาน ทำให้ Git แบ่งสัดส่วนของสถานที่เก็บไฟล์เป็น 3 ระดับ ตามแต่ละสถานะได้ดังนี้
- หน้างาน (working directory) พื้นที่สำหรับทดลองดัดแปลงแก้ไขชิ้นงาน โดย Git จะไม่เข้าไปยุ่งเกี่ยวกับการจดบันทึกประวัติของชิ้นงานที่ยังอยู่ในส่วนนี้
- นั่งร้าน (stage) พื้นที่ชั่วคราวสำหรับนำชิ้นงานที่ถูกดัดแปลงมาจัดวางองค์ประกอบ เพื่อพิจารณาว่าจะเลือกการดัดแปลงตรงไหนบ้างที่จะเก็บเป็นภาพชั่วขณะเข้าสู่คลังต่อไป
- คลัง (repository) สถานที่สำหรับจัดเก็บภาพชิ้นงานทั้งหลายที่ได้สร้างสรรค์ไปแล้ว
สถานะและสถานที่ดังกล่าว สามารถวาดออกมาเป็นแผนภาพกรณีใช้งานได้ดังรูปที่ 11
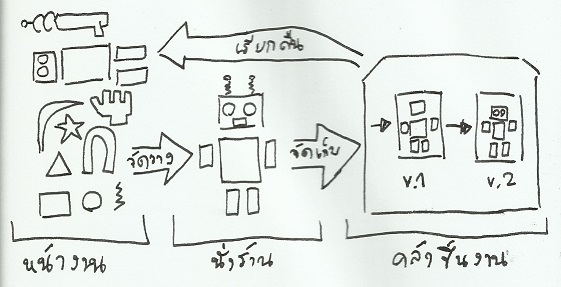
รูปที่ 11: สถานะทั้ง 3 ใน Git
การกระจายศูนย์ การแตกกิ่งก้าน และการรวมเนื้อหาที่ทรงพลัง
นอกจาก Git จะใช้แนวคิดกระจายศูนย์การเก็บซอร์ส ทำให้ผู้ใช้หลายคนสามารถสร้างสรรค์ชิ้นงานพร้อมกันตามแนวทางที่ได้ตกลงกันไว้ Git ยังมีแนวคิดของการแตกกิ่งก้าน (branch) ที่เปรียบเสมือนการแตกสายการพัฒนาชิ้นงานชิ้นนั้น เพื่อทดลองนำแนวทางอื่นๆ มาใช้พัฒนาชิ้นงานโดยไม่ต้องสนใจแนวทางเดิม หรือดัดแปลงนำความสามารถนี้ไปกำหนดสายการพัฒนาก็ย่อมได้ รูปที่ 12 แสดงตัวอย่างการแยกสายการพัฒนารูปแบบหนึ่งที่ได้รับความนิยม
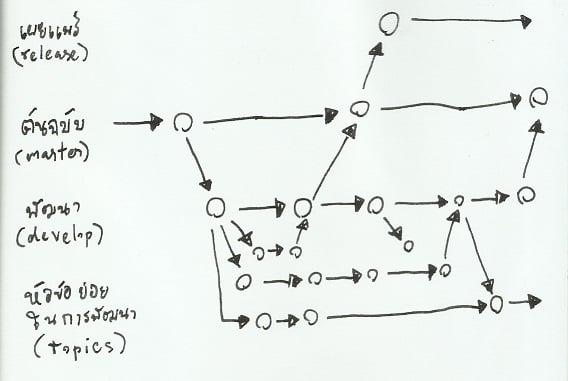
รูปที่ 12: การแตกสายการพัฒนาจากต้นฉบับ
แต่จุดขายสำคัญที่สุดของ Git คืออัลกอริทึมการรวมเนื้อหาจากกิ่งก้านต่างๆ เหล่านั้น ให้กลับมารวมกันได้อย่างราบรื่น เราจะกล่าวถึงเรื่องการแตกกิ่งและการรวมเนื้อหาอย่างละเอียดในตอนถัดๆ ไป
ข้อมูลที่ถูกจัดเก็บมีการตรวจสอบความถูกต้อง และการนับเลขรุ่นด้วยแฮช
Git ให้ความสำคัญกับความถูกต้องของข้อมูลเป็นอย่างมาก ไฟล์ทั้งหมดที่ถูกจัดเก็บจะต้องถูกตรวจค่าผลรวม (checksum) เสมอด้วยอัลกอริทึมแฮช SHA-1 ทำให้เมื่อมีการเสียหายของข้อมูลแม้เพียงเล็กน้อย ก็จะสามารถถูกตรวจพบได้ทันที
ผลพลอยได้จากการตรวจค่าผลรวม คือเลขรุ่นสำหรับอ้างอิงชิ้นงานใน Git จะไม่ใช่ตัวเลขที่นับไล่ตามลำดับเวลาจัดเก็บชิ้นงานแล้ว แต่จะใช้ค่า SHA-1 ที่คำนวณได้นั้นมาอ้างรุ่นแทน
ระบบเสรีและเปิดซอร์ส
นี่อาจเป็นเหตุผลสำคัญที่สุดที่ทำให้ Git แพร่หลายในทุกวันนี้ก็เป็นได้ เพราะ Git เริ่มด้วยแนวคิดที่ว่า จะต้องเป็นระบบเสรี (freedom) และเปิดซอร์ส (open source) การเผยแพร่ Git ภายใต้สัญญาอนุญาตแบบ GPL 2.0 ทำให้ผู้ใช้มีอิสระในการใช้ Git อย่างไรก็ได้ตามต้องการ ซึ่งรวมไปถึงการปรับแต่ง Git ให้เหมาะสมกับการใช้งานของตน มันจึงสามารถดึงดูดนักพัฒนาจำนวนไม่น้อยมาช่วยปรับปรุงแก้ไขระบบให้ดียิ่งขึ้น และแจกจ่ายมันออกไปในวงกว้าง จนตอนนี้แทบไม่มีนักพัฒนาคนไหนที่ไม่เคยได้ยินชื่อ
สิทธิ์ดังกล่าว ยังครอบคลุมไปถึงการอนุญาตให้พัฒนาต่อยอด Git ภายใต้ชื่ออื่น แล้วคิดค่าใช้งานจากระบบนั้นๆ ได้อีกด้วย ดังจะเห็นต่อไปในตอนหน้า เมื่อเราแนะนำระบบ Git ที่มีส่วนติดต่อผู้ใช้แบบกราฟิก และถูกพัฒนาโดยนักพัฒนาภายนอก (third-party)
ลองเล่น Git ผ่านเว็บ
เว็บไซต์ http://try.github.io/ จาก Code School เป็นเว็บที่เปิดให้ผู้สนใจ Git สามารถมาลองใช้งานมันในรูปแบบของการทดลองขับ (test drive) ได้
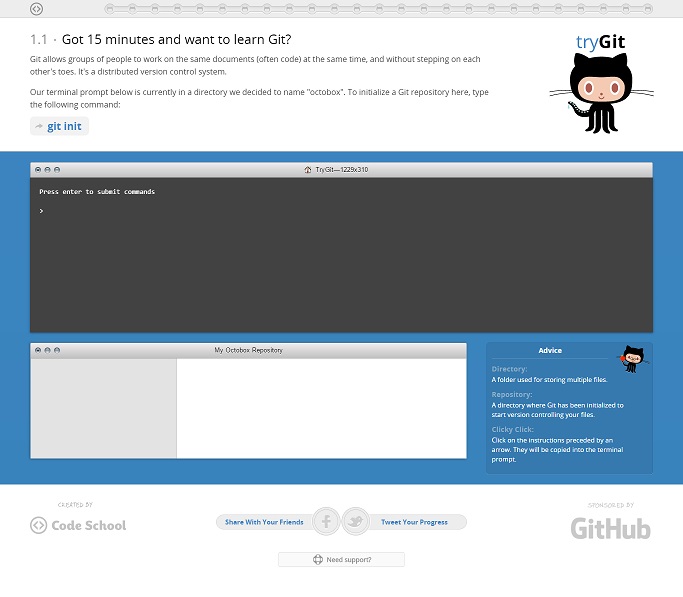
รูปที่ 13: หน้าเว็บสำหรับทดลองใช้ Git ที่ try.github.io
เมื่อเข้าสู่หน้าเว็บ จะพบกับบทเรียนแรกทันทีดังรูปที่ 13 โดยแต่ละบทจะเป็นตอนสั้นๆ ที่ทางเว็บบังคับให้พิมพ์คำสั่งตาม (หรือหากไม่ต้องการพิมพ์ยาวๆ ก็แค่คลิกเมาส์บนคำสั่งเหล่านั้นแทนได้) แล้วสังเกตความเปลี่ยนแปลงต่างๆ ที่เกิดขึ้นกับชิ้นงานและ Git
บทเรียนทั้งหมดมี 25 บท สามารถกดข้ามหรือย้อนกลับไปยังบทใดก็ได้ ส่วนเวลาที่ใช้เรียนจนจบหลักสูตร จะตกราว 15 นาทีตามที่ทางเว็บกล่าวอ้าง แม้จะเป็นเวลาสั้นๆ และไม่สามารถทดลองอะไรนอกหลักสูตรได้มากนัก แต่อย่างน้อยแล้ว บทเรียนทั้งหมดก็น่าจะทำให้คุ้นเคยกับรูปแบบคำสั่งของ Git พอสมควร

Get latest news from Blognone
Follow @twitterapi



Comments
ซอร์ซ => ซอร์ส
ระบบปฎิบัติการ => ระบบปฏิบัติการ
ตรวจเช็ค => ตรวจเช็ก
กราฟฟิก => กราฟิก
เรียบร้อยครับ
บอกเลยนึกว่าเรียน OS อยู่
เป็นการทวนความรู้ไปในตัวฮะ :D
รออ่านตอนหน้าครับ
ขอลึกๆ ในส่วน GITHUB ด้วยครับ
รูปเข้าใจง่ายดี
ใช้ SVN จนชินพอมาลองใช้ Git อย่างงงเลย อ่านบทความเข้าใจหลักมันขึ้นมาหน่อย ขอบคุณครับ
บางคำไม่ต้องแปลไทยหรอกครับ อ่านแล้วไม่ลื่น + งงกว่าเดิม
คำไหนไม่ชอบไม่ดีก็แนะนำกันมาได้ครับ ไม่ใช่มาบ่นลอยๆ ที่ไม่เกิดประโยชน์อะไร
ขออณุญาตยกคำตอบเดิมบางส่วนมานะครับ
อย่างไรก็ตาม หากคิดว่าคำแปลคำไหนที่แปลแล้วสะดุด/มีคำแปลอื่นที่ดีกว่านี้/มีเหตุผลที่ห้ามแปลเป็นไทย ก็เสนอเข้ามาได้ครับ
ไม่ลองทำเหมือนคุณป้า panurat2000 ของเราดูล่ะครับ (งานเนี๊ยบ ละเอียดอ่อนมากๆ เลย FC คุณป้าเบาๆ)
คำไหนว่าไม่เวิร์ก ไล่มาเลยครับ รออ่านด้วยเหมือนกัน
ขออภัยที่ไม่ได้ลงรายละเอียดครับ
และไม่ทราบว่าผู้แต่งต้องการใส่คำไทยให้มากที่สุด ตามที่สมาชิกด้านบนบอกไว้
ส่วนตัวผมมองว่า ถ้าแปลแล้วเข้าใจยากกว่าเดิม ก็ไม่ควรแปลครับ
เพราะคนส่วนใหญ่คุ้นกับศัพท์ภาษาอังกฤษอยู่แล้ว
พออ่านไป ก็ต้องแปลกลับเป็นอังกฤษอยู่ดี
เช่น
กิ่งก้าน, รวมศูนย์, กระจายศูนย์, ทดสอบขับ
ผมเคยเขียนหนังสือหลายเล่ม เข้าใจท่านผู้แต่งครับ
ว่าการหาความหมายของศัพท์ Computer นั้นมันยากขนาดไหน
สุดท้าย บ.ก. แนะนำว่า หากแปลไม่ได้จริงๆ ก็ทับศัพท์ไปเลย
เช่น
เปิดซอร์ส ก็ใช้เป็น โอเพ่นซอร์ส
เลขรุ่น ก็ใช้เป็น เวอร์ชัน
หวังว่าคงมีประโยชน์ไม่มากก็น้อยครับ
ความตั้งใจหนึ่งของผมคือ ให้บทความชุดนี้เป็นบทความช่วยสอนเขียนโปรแกรมสำหรับคนไทยครับ ผมขอตัดกรณีคนไทยที่อ่านภาษาอังกฤษคล่องออกไปก่อนเลยนะ (เพราะคงอ่านหนังสือภาษาอังกฤษกันแล้ว)
ทีนี้ คนไทยกลุ่มที่เหลือที่ยังต้องพึ่งพาบทความภาษาไทย ก็จะมีกลุ่มที่ทำงานสายเทคโนโลยีสารสนเทศมาระยะหนึ่งจนชินกับศัพท์เฉพาะทางพวกนี้แล้ว กับกลุ่มที่เริ่มต้นเขียนโปรแกรมไม่นาน (เช่น นักศึกษาในภาควิชาคอมพิวเตอร์) ที่อาจจะยังไม่คุ้นศัพท์พวกนี้
เมื่อพูดถึงนักศึกษาภาควิชาคอมพิวเตอร์ ก็จะมี 2 ภาควิชาหลักๆ ที่เรานึกออกกันในทันที คือ ภาควิชาวิศกรรมคอมพิวเตอร์ จากคณะวิศวกรรมศาสตร์ และภาควิชาวิทยาการคอมพิวเตอร์ จากคณะวิทยาศาสตร์
ผมเปิดข้อมูลจำนวนนักศึกษาในปี 2557 จากกระทรวงศึกษาธิการ พบว่าจำนวนนักศึกษาปริญาตรีที่กำลังศึกษาอยู่ในคณะวิทยาศาสตร์และวิศวกรรมศาสตร์ มีรวมกันแล้วประมาณสามแสนห้าหมื่นคน (หน้า 70 ในไฟล์สรุป pdf) น่าเสียดายที่ข้อมูลข้างต้นไม่ได้ให้รายละเอียดแยกย่อยตามภาควิชา (และผมก็เหนื่อยเกินกว่าที่จะไล่ตามอ่านสรุปจำนวนนักศึกษาแต่ละมหาวิทยาลัยในประเทศไทยแล้ว) ดังนั้นผมขอคำนวณคร่าวๆ ว่า ให้คณะวิทยาศาสตร์/วิศวกรรมศาสตร์มีภาควิชาย่อยอยู่ 20 ภาควิชา แต่ละภาควิชารับนักศึกษาเท่าๆ กัน เมื่อภาควิชาที่เราสนใจเป็นหนึ่งในภาควิชาของคณะเหล่านั้น ก็จับเอาสามแสนห้าหารยี่สิบ ได้คำตอบออกมาประมาณหมื่นเจ็ด
หนึ่งหมื่นเจ็ดพันคนกำลังศึกษาคอมพิวเตอร์เป็นวิชาหลักอยู่ในมหาวิทยาลัย นี่ยังไม่นับรวมนักศึกษาภาควิชาอื่นๆ ที่เลือกเรียนวิชาคอมพิวเตอร์เป็นวิชาเสริม นักเรียนในระดับมัฐยม/ประถมที่สนใจการเขียนโปรแกรม และบุคคลทั่วไปที่ต้องการย้ายสายงานหรือเพิ่มทักษะการใช้งานคอมพิวเตอร์
ด้วยปริมาณขนาดนี้ ผมไม่คิดว่าสันนิษฐานดังกล่าวจะฟังขึ้นเท่าไหร่นะครับ
อนึ่ง ถ้าผมเลือกที่จะไม่แปลศัพท์พวกนี้เลย กลุ่มที่ได้รับผลประโยชน์คือกลุ่มคนที่ชินกับศัพท์อังกฤษ เวลาอ่านก็ไหลลื่นไม่มีสะดุดครับ ส่วนกลุ่มที่เสียผลประโยชน์ก็แน่นอนว่าเป็นกลุ่มคนที่ไม่รู้จักกับศัพท์อังกฤษ อ่านๆ ไปก็อาจจะท้อ เนื้อหายากยังไม่พอยังมาเจอภาษาอังกฤษที่ไม่คุ้นเคยอีก ก็ตัดใจกลางคันได้
แต่ถ้าผมเลือกแปลศัพท์พวกนี้หละ กลุ่มที่ไม่รู้จักศัพท์อังกฤษก็ยังจะอ่านได้ ลดความยุ่งยากด้านคำศัพท์ลงไปหนึ่ง (ไปต่อสู้กับความยากของเนื้อหาแทน) ส่วนกลุ่มที่รู้จักศัพท์อยู่แล้วเวลาอ่านก็อาจรู้สึกไม่สบายลูกตาไปบ้าง แต่ก็ยังจับใจความเนื้อหาได้เหมือนเดิม
จะเห็นว่า การเลือกแปลศัพท์ให้ผลลัพท์ด้านปริมาณคนอ่านรู้เรื่องเยอะกว่าการไม่แปลครับ (แม้จะทำให้คนที่เชี่ยวคำศัพท์ขัดใจขณะอ่านไปบ้าง)
สุดท้ายแต่ไม่ท้ายสุด ผมคิดว่าการแปลศัพท์เหล่านี้ก็เป็นการกำหนดทิศทาง (trend) อย่างหนึ่งต่อภาษาในอนาคตครับ แน่นอนว่าในช่วงที่เรายังไม่ชินเราก็อาจจะต่อต้านมันไปบ้าง (และก็ต้องยอมรับว่า เราอาจไม่มีวันชินกับมันได้หรอก) แต่ถ้าศัพท์เหล่านี้มันใช้งานได้ดีพอจนทนทานต่อกาลเวลา เด็กๆ รุ่นถัดไปก็น่าจะใช้ศัพท์พวกนี้กันได้อย่างไม่เคอะเขินแล้วครับ
ต่อไปเป็นการอภิปรายการเลือกแปลศัพท์เป็นรายคำ
ขอบคุณครับ
ขอแจม.. นิดเดียวจริงๆ
"โอเพนซอร์ส" ผมชอบคำไทยว่า "เปิดรหัสต้นฉบับ" มากกว่า หรือจะยาวอีกนิดแต่ชัดเจนในความหมายมากกว่าไปเลยว่า "เปิดเผยรหัสต้นฉบับ"
อยากใช้ "โอเพนซอร์ส->เปิดรหัสต้นฉบับ" เช่นกันครับ ซึ่งถ้าแก้ตามนี้ ผมก็ควรจะต้องไล่แก้ทั้งเอกสารที่ใช้คำว่า "ซอร์ซ->รหัสต้นฉบับ" ทั้งหมดด้วย เช่น "ระบบจัดการซอร์ส->ระบบจัดการรหัสต้นฉบับ" ผมยังไม่แน่ใจว่าถ้าเปลี่ยนแบบนี้แล้วจะทำให้คำที่เหลือนั้นยาวเกินไป/สื่อความหมายยากขึ้นมั้ย หรือว่าถ้าตัดทอนลงเหลือแค่ "ระบบจัดการต้นฉบับ" จะสูญเสียความหมายไปหรือไม่
รับไว้พิจารณาครับ
เอกสารโปรเจคจบ คำไหนเป็นอังกฤษ ให้แปลไทยให้หมด แล้วใส่วงเล็บคำอังกฤษไว้
GIT ถ้าไม่มีโปรเจคก็ไม่จบง่ายๆนะเนี้ย แก้ไปแก้มา
check-out ผมนึกถึงคำอย่าง "เบิกใช้" หรือ "เบิกสำเนา" อะไรทำนองนี้มากกว่านะครับ
opensource มีสอง sense นะครับ ถ้าเป็นกริยา ใช้ "เปิดซอร์ส" หรือ "เปิดต้นฉบับ" ถ้าเป็นวิเศษณ์ ใช้ "ซอร์สเปิด" หรือ "ต้นฉบับเปิด"
โอ้ นึกไม่ถึงคำว่า "เบิก" เลยครับ ไว้จะลองปรับแก้ดูนะครับ
ขอบคุณสำหรับคำแนะนำเรื่องคำกริยา/วิเศษณ์ด้วยครับ
หากใครจะลงลึก มี ebook ฟรี เป็น open source อยู่ที่นี่ครับ progit.org อธิบายละเอียดมาก
พอจะมี GITHUB ฉบับภาษาไทยแบบละเอียดๆ บ้างไหมครับ
อยากลองใช้ดูบ้าง อ่านในเวปไม่ค่อยละเอียดเท่าไร เห็นโปรเจ็คดีๆ
หลายตัวแต่ยังไม่ถูกใจ อยากจะเอามาปรับแก้ใช้ตามที่ต้องการ
เช่น Book Catalogue บน Android มีอยู่บน GITHUB
ภาษาไทยผมว่าของคุณ AorJor ละเอียดดีนะครับ
อธิบายดี เข้าใจง่าย ภาพประกอบสวยงามมากครับ
คนที่ไม่ได้อยู่ในสายงานนี้อย่างผมอ่านแล้วเก็ตทุกประการ
ขอบคุณครับ
@iannnnn
ถึงแม้ Git จะออกแบบมาสำหรับเก็บโค้ดโปรแกรมเป็นหลัก แต่หากจะเอามันไปใช้จัดการไฟล์รูปภาพกราฟิกต่างๆ ก็ไม่มีปัญหานะครับ :D
editทิ้ง ตอนแรกอ่านลวกๆไปหน่อย 555
ขอบคุณครับ ตั้งตารอตอนต่อไป อยากรู้มากๆ ว่ามันรวมเนื้อหายังไง เคยลองใช้ github อยู่นิดหน่อย ก็งงๆ ไม่เข้าใจการรวมไฟล์เลยไม่กล้าใช้มาก กลัวไฟล์เละ(งงตรงการแตกกิ่งด้วย แต่คิดว่าไม่ใช่เรื่องใหญ่ถ้าใช้ไปเรื่อยๆ คงชินเอง)
เขียนได้อย่างยอดเยี่ยมมากครับ
ขอบคุณมาก เขียนได้ดีมาก
เอผมว่าการแตก branch มันมีตั้งแต่สมัย cvs (หรืออาจจะก่อนนั้น) แล้วนะครับ แต่จากบทความจะอ่านแล้วรู้สึกว่าเหมือนพึ่งจะมีใน git
ถ้าผมเขียนเพิ่มตรงย่อหน้าที่ 2 ของหัวข้อ "การกระจายศูนย์ การแตกกิ่งก้าน และการรวมเนื้อหาที่ทรงพลัง" ว่า
พอโอเคมั้ยครับ?
ระบบ Git เป็นระบบ Version Control ที่ดีของจริง เพราะทำให้เกิด GitHub ได้ครับ
report.docx
report.v2.docx
report.v5.docx
report.final.docx
report.final.latest.docx
report.final.final.docx
report.final.final.final.docx
...
....
.....
พอเห๊อะ จะแก้กันเยอะไปไหน ทำไมไม่บอกกันมาทีเดียวแว้!
เทคโนโลยีไม่ผิด คนใช้มันในทางที่ผิดนั่นแหละที่ผิด!?!
555 เคยเจอเหมือนกัน งงมาก สุดท้ายตัวไหนตัวสุดท้าย
final.docx
final of final.docx
lastest.docx
อันนี้ผมเอง 555+
project final final final 2.psd
เอกสาร
เอกสาร ใหม่
เอกสาร ใหม่ ล่าสุด
เอกสาร ใหม่ ล่าสุด 2-5-59
แล้วพอใช้วันที่ ก็จะเพิ่มความงงเข้าไปอีก 1 ระดับเช่น
เอกสาร ใหม่ ล่าสุด 2-5-59
เอกสาร ใหม่ ล่าสุด ใช้อันนี้
ต้องใช้ไฟล์ไหนกันแน่ บางกรณี modified date ของอันที่ลงวันที่ดันใหม่กว่า "ใช้อันนี้" XD
ใช้ตัวเลขระบุวันเดือนปีเหมือนกันครับ แต่เคยซวยเจอแก้สามรอบในวันเดียวมั้ยครับ?
เทคโนโลยีไม่ผิด คนใช้มันในทางที่ผิดนั่นแหละที่ผิด!?!
เคยเจอครับ แต่ไม่มีปัญหาครับ 555
วันที่พยายามเขียนปี เดือน วัน นะครับ เวลาเรียงตามชื่อแล้วจะได้ลำดับความสดใหม่มาเอง เว้นแต่จะเชื่อในการเรียงตามความใหม่ ;)
อ้อ ผมใช้ ปี-เดือน-วัน แหละครับ แต่ไม่เคยใส่เวลาไปด้วยแบบนี้ซักที อะไรจะขนาดนั้น = =a
เทคโนโลยีไม่ผิด คนใช้มันในทางที่ผิดนั่นแหละที่ผิด!?!
#ชูป้ายไฟ
ตอนแรกจะเข้ามาเถียงเรื่อง Vi แต่ไปอ่าน doc ดูแล้วมัน undo ได้ one level จริงๆ ด้วยแฮะ อยากได้มากกว่านั้นต้องใช้ Vim + set undofile เพื่อเก็บ persistent history เอาไว้ undo ได้แม่ปิดเปิดไฟล์ใหม่
ถ้าใช้ Vim จนคล่องแล้วเปิดมันใน Ubuntu ที่เพิ่งติดตั้งเสร็จจะบ่นอุบเลยครับ เพราะว่าจะได้ Vim รุ่นที่เข้ากันได้กับ vi มาใช้แทน ซึ่งก็คือกดย้อนได้แค่ครั้งเดียว สั่งไฮไลท์สีคำสั่งก็ไม่ได้ ตอนอยู่โหมด insert จะกด backspace ลบตัวอักษรมากกว่าที่พิมพ์ไปก็ไม่ได้ TwT
จริงๆ ก็กะว่าจะมีคนสับสนตรงนี้อยู่เหมือนกันครับ โปรแกรมอื่นที่มีคนรู้จักกันเยอะหน่อยแล้วสามารถย้อนกลับได้แบบ swap ก็นึกออกแค่ Notepad แต่เนื่องจากผมยกตัวอย่าง Paint ไปแล้วอะครับ เลยไม่อยากยกตัวอย่างโปรแกรมจากค่ายเดิมซ้ำอีกรอบ หวยเลยมาตกที่ vi
ถ้าโปรเจคที่ทำงานอยู่ มีคนในทีมไม่เกิน 5 คน แต่ละคนทำงานคนละไฟล์กัน มีไฟล์ที่ใช้ร่วมกันไม่เกิน 3 ไฟล์ อยากทราบว่าควรใช้ GIT ดีมั้ย หรือใช้ Version Control ตัวอื่นดีกว่า
ผมทำคนเดียวหรือบางครรั้งมีทีมแต่แค่ 2 คนยังใช้เลยครับ
ใช้เพราะมันสามารถ Offline Commit ได้ใช่มั้ยครับ หรือมีข้อดีอย่างอื่นอีก
ผมทำงานคนเดียวก็ใช้ครับ
ไม่เกี่ยวกับจำนวนคนในทีม เพราะประโยชน์มันคือการ Control Version วันไหนเบลอๆ หรือเผลอทำไรผิดไป ก็เอากลับมาได้ครับ
ส่วนจะเลือก Version Control ตัวไหน จริงๆ มันก็เหมือนกันหมดครับ SVN, CVS, GIT มันทำ Version Control ได้หมด ยกตัวอย่างกรณีผมนะ
ผมไม่ต้องการให้คนในทีมแก้ไขไฟล์เดียวกันได้พร้อมกัน เหตุผลก็เพราะ หากแก้พร้อมกันมันต้อง Merge และส่วนใหญ่ การ Merge มักเกิดหลังจากทำเสร็จแล้ว ทำให้เกิด Bug หลัง Merge จากข้อนี้ CVS ตกไป เลือกใช้ SVN เพราะทำ Lock-Modified-Unlock ได้
IDE ที่ใช้ เนื่องจากผมใช้ Eclipse (Java) & Visual Studio (.NET) ผมเลือก SVN เพราะมี Plugin บน IDE ทั้งสองตัว SVN Kit + Visual SVN
ตามคุณ level255 ครับ เป้าหมายหลักคือการทำ Control Version
ผมทำโปรเจคคนเดียว แต่ผมใช้ TortoiseHg แล้วฝากโค้ดไว้ที่ bitbucket
ผมว่ามันสะดวกดีนะ เผื่อวันหนึ่งอยากไล่ย้อนไปดูว่า เอ๊ะ เราแก้ไขอะไรไปบ้างน้า หรือบางทีไล่ไปดูโค้ดเก่าที่เราเคยแก้ไขก็ยังได้
แต่ Github พยายามเล่นอยู่ เล่นไม่เป็นซักที
ขอบคุณมากครับ ไม่เคยเข้าใจ GIT สักที
ว่างๆมีสมาธินั่งอ่านคงจะเข้าใจและใช้เป็นมากขึ้น
ขอบคุณมากครับ ผมยังไม่เคยใช้งานมันเลย เป็น Developer หางแถวมากๆ คงต้องลองศึกษาบ้างแล้วล่ะ (พอดีตัวที่ใช้ทำงานหลักมันจัดการเวอร์ชั่นของตัว source code ได้ดีระดับนึง)
..: เรื่อยไป
ขอบคุณมากครับ อ่านแล้วเข้าใจการทำงานขึ้นเยอะเลย
คิดว่าปัญหาหลักของ CVS ที่ SVN เข้ามาแก้ คือเรื่อง revision ของทั้ง tree มากกว่านะครับ เพราะ CVS จะเก็บประวัติแยกเป็นไดเรกทอรี แต่ในทางปฏิบัติ แพตช์บางแพตช์มันแก้หลายไดเรกทอรี การ checkout รุ่นเก่าแบบทั้ง tree ด้วย CVS จึงยุ่งยากมาก ส่วนเรื่องการ merge โดยหลักการแล้ว SVN ก็ไม่ได้ต่างจาก CVS มากนัก (หรือเปล่า? หรือผมพลาดประเด็นไหนไป?)
เรื่อง cvs เก็บ version ของแต่ละไฟล์แยกกันอิสระ แต่ svn จะมองเป็น change set ด้วยรึเปล่าครับ?
onedd.net
ผมไม่ทันใช้ CVS ครับ ตัวแรกที่ใช้ก็ SVN แล้ว (ราวๆ ปี 2012 -- ก็น่าจะเป็น SVN รุ่น 1.7) และก็รู้สึกว่าการ merge ไม่ได้ยุ่งยากหรือติดขัดเท่าไหร่ แต่พอได้ดูวิดีโอ Linus ที่อ้างอิงถึง CVS (นาทีที่ 15:35-16:25) แล้วทุกคนบอกเป็นเสียงเดียวกันว่า การ merge ใน CVS นั้นไม่สนุกเอาเสียเลย ผมเปิดเอกสาร CVS อ่านคร่าวๆ ตรงเรื่อง merge ก็เห็นว่ายุ่งยากจริง (เช่น เมื่อต้องการ merge จาก branch ที่เคย merge ไปแล้วแต่พัฒนาเพิ่ม ต้องระบุรุ่นสุดท้ายที่เคยโดน merge ไปก่อนด้วย) เลยตั้งข้อสรุปไปแบบนั้น
แต่ตอนที่ผมอ่านเรื่องอื่นอยู่นั้น ก็พบว่า SVN เพิ่งปรับปรุงให้การ merge ให้ง่ายขึ้นมาที่รุ่น 1.5 (ปี 2008) นี่เองครับ ก่อนหน้านั้น SVN อาจจะ merge ยุ่งยากเหมือน CVS ก็ได้ และทำให้ข้อสรุปผมไม่ถูกต้องเสียทีเดียว ไว้จะลองอ่านรายละเอียดเพิ่มแล้วปรับแก้นะครับ
เหมือนพระมาโปรด กำลังต้องใช้อยู่พอดี
หาอ่านหนังสือภาษาไทยไม่มี TAT
ขอบคุณที่เขียนยทความนี้ครับ
ผมขอหาเวลาว่างมาอ่านเพื่อทำความเข้าใจก่อน เพราะเป็นเรื่องใหม่ที่น่าสนใจสำหรับผม
เพิ่มเติม 9 มี.ค. 2559 หาเวลาอ่านจบแล้ว ขอบคุณที่อธิบายแนวคิดของ Git ให้เข้าใจง่ายครับ
ที่เคยใช้มาก็ Microsoft Visual SourceSafe แล้วก็มาใช้ SCM In house สองตัวนี้ก็ดีตรงที่ต่างคนต่างทำ check out คนละไฟล์หมดปัญหาเรื่อง merge ไปแต่ถ้าแก้ไฟล์เดียวกันเมื่อไรก็จะกลายเป็นคอขวดทันที จากนั้นก็ได้ใช้พวก TortoiseSVN ถ้ามีคนที่ยังใหม่เรื่อง SVN มาร่วมทีมก็จะมีปัญหาปวดหัวเรือง code หายมั้ง conflict มั่งกันได้ทุกเช้าเลย สุดท้ายก็มาจบที่ git ยิ่งใช้ร่วมกับ github desktop ใช้กันยาวๆ สบายๆ
สงสัยว่าสมัยนี้ยังมีอะไรที่ใช้ง่ายกว่า git อีกหรือ? ตอนนี้ถ้าจะทำ version control ก็แค่ cd project_dir; git init จบ
คงเป็น Filesystem แล้วล่ะครับ สร้างปุ๊บรัน Version control ให้เลย
บล็อกส่วนตัวที่อัพเดตตามอารมณ์และความขยัน :P
บทความดีมากเลยครับ
เนื้อหาและภาพประกอบอ่านแล้วเข้าใจง่าย ชื่นชมครับ
ขอบคุณครับ บทความนี้ทำให้ผมสนใจเรื่องการเขียนโปรแกรมมากขึ้น