By: littletail 

 on 3 July 2016 - 11:16
Tags:
on 3 July 2016 - 11:16
Tags:
Topics:

ช่วงหลังมานี้เราเริ่มจะได้ยินข่าวเกี่ยวกับคอมพิวเตอร์ควอนตัมกันมากขึ้น ทั้งเรื่องของการวิจัยพัฒนา จนไปถึงความพยายามสร้างเพื่อเอาไปใช้จริง หลายหน่วยงานในต่างประเทศก็เริ่มพูดถึง และให้การสนับสนุนงานวิจัยเหล่านี้กันมากขึ้นเรื่อยๆ (ขนาดนายกรัฐมนตรีแคนาดายังเคยพูดถึงเลย) หลายคนเชื่อกันว่านี่จะเป็นวิวัฒนาการของคอมพิวเตอร์แบบก้าวกระโดด
แต่ก็ยังมีอีกหลายคนที่ไม่รู้จัก หรือเพิ่งจะได้ยินชื่อนี้เป็นครั้งแรกเสียด้วยซ้ำ บทความนี้เขียนไว้เพื่อนำเสนอว่าคอมพิวเตอร์ควอนตัมคืออะไร แตกต่างจากคอมพิวเตอร์ที่เราใช้ๆ กันยังไง และเราจะได้ประโยชน์อะไรจากมัน
ยินดีต้อนรับสู่โลกฟิสิกส์ควอนตัม
กฎของมัวร์กล่าวไว้ว่าทรานซิสเตอร์ในวงจรไอซีจะมีจำนวนเพิ่มขึ้นเป็นเท่าตัวทุกๆ 2 ปี ในวงจรขนาดเท่าเดิม หากกฎข้อนี้ยังคงเป็นจริงไปเรื่อยๆ สักวันหนึ่งทรานซิสเตอร์ก็จะมีขนาดเล็กลงจนแทบจะเท่ากับอะตอม เมื่อถึงเวลานั้น ฟิสิกส์ในชีวิตประจำวันจะไม่สามารถอธิบายปรากฎการณ์ต่างๆ ที่เกิดขึ้นภายในวงจรได้อีกต่อไป ฟิสิกส์ควอนตัมจะเข้ามามีบทบาทแทน
แต่แทนที่จะเพิ่มแค่จำนวนทรานซิสเตอร์ขนาดเล็กเข้าไปเรื่อยๆ ก็มีนักวิทยาศาสตร์ปิ๊งไอเดีย ว่าทำไมไม่ลองเอาสมบัติบางประการในฟิสิกส์ควอนตัมมาใช้ในการคำนวณซะเลยล่ะ ไอเดียที่ว่านี้กลายร่างมาเป็นศาสตร์ใหม่ เรียกว่า “การประมวลผลควอนตัม” (quantum computing) ศาสตร์นี้เริ่มมีมาในช่วงต้นปี 1980 แล้ว แต่ยังไม่ได้รับความสนใจมากนัก จนกระทั่งปี 1994 ถึงจะเริ่มมาบูม เนื่องจากมีคนพัฒนาอัลกอริทึมหาตัวประกอบเฉพาะของจำนวนเต็มขนาดใหญ่ด้วยคอมพิวเตอร์ควอนตัมได้สำเร็จ อัลกอริทึมนี้ประมวลผลได้เร็วมากเสียจนสะเทือนวงการวิทยาการเข้ารหัสกันเลยทีเดียว
สรุปแล้ว คอมพิวเตอร์ควอนตัมก็คือคอมพิวเตอร์ที่เอาสมบัติของฟิสิกส์ควอนตัมมาใช้ในการประมวลผลนั่นเอง
 คอมพิวเตอร์ควอนตัมของศูนย์วิจัย QuTech แห่ง Delft University of Technology ประเทศเนเธอร์แลนด์ (ที่มาภาพ: TEDx Amsterdam)
คอมพิวเตอร์ควอนตัมของศูนย์วิจัย QuTech แห่ง Delft University of Technology ประเทศเนเธอร์แลนด์ (ที่มาภาพ: TEDx Amsterdam)
แล้วสมบัติของฟิสิกส์ควอนตัมอะไรบ้างหล่ะที่ถูกนำมาใช้ เพื่อตอบคำถามนี้ ผมจะพาไปแนะนำให้รู้จักกับ “คิวบิต” หน่วยข้อมูลที่เล็กที่สุดในคอมพิวเตอร์ควอนตัม
ศูนย์ หนึ่ง และทั้งสองอย่างในเวลาเดียวกัน
เป็นที่รู้กันว่าคอมพิวเตอร์คลาสสิกจะมีหน่วยแทนข้อมูลที่เล็กที่สุดคือบิต (bit) ในข้อมูล 1 บิต จะมีอยู่ด้วยกัน 2 สถานะ ได้แก่ 0 และ 1 (หลังจากนี้จะใชัคำว่า “คอมพิวเตอร์คลาสสิก” เรียกคอมพิวเตอร์ที่เราใช้งานกันอยู่ในปัจจุบัน)
ในคอมพิวเตอร์ควอนตัม ข้อมูลบิตจะมีสถานะพิเศษอีกอย่างหนึ่ง เรียกว่า superposition เป็นสถานะที่บิตเป็นทั้ง 0 และ 1 ในเวลาเดียวกัน เลียนแบบสถานะ quantum superposition ของอนุภาคขนาดเล็ก โดยบิตในคอมพิวเตอร์ควอนตัมนี้มีชื่อเรียกกันเล่นๆ ว่า “คิวบิต” (qubit มาจากคำว่า quantum bit)
วัสดุทางกายภาพที่จะใช้แทนข้อมูลคิวบิต ก็เลยเป็นอนุภาคขนาดเล็ก และสมบัติบางประการของมันมีสถานะ quantum superposition ตัวอย่างเช่น ขั้ว (polarization) ของอนุภาคโฟตอนของแสง หรือสปิน (spin) ของอนุภาค
อย่าเพิ่งเข้าใจผิดนะครับว่า superposition คือสถานะหมายเลข 2 ต่อจาก 0 และ 1 จริงๆ แล้วคิวบิตในสถานะ superposition นั้นยังไม่เป็นข้อมูลที่จะเอามาใช้จริงได้ แต่ต้องถูกนำไปวัดก่อน เรียกกระบวนการนี้ว่า “measurement” เมื่อคิวบิตถูกวัดแล้ว มันต้องตัดสินใจทันทีว่าจะเป็น 0 หรือ 1 โดยดูจากความน่าจะเป็นของการเปลี่ยนสถานะที่คิวบิตถูกตั้งเอาไว้
เราสามารถแก้ไขความน่าจะเป็นของการวัดคิวบิตเพื่อใช้คำนวณได้ เช่น อาจจะแก้สถานะ superposition ให้มีโอกาสถูกวัดได้สถานะ 1 สัก 70% หรือในกรณีของคิวบิต 2 ตัว เมื่อเข้าสถานะ superposition มันจะมีสถานะ 00, 01, 10, และ 11 พร้อมๆ กัน และเราก็สามารถปรับแก้ความน่าจะเป็นของการวัดให้สถานะ 00 มีโอกาสถูกวัดเจอได้สูงกว่าสถานะอื่นๆ
คลิปอธิบายสถานะ quantum superposition ของอนุภาค
รายละเอียดของคิวบิตข้างต้นนี้อาจจะยังไม่ถูกต้องร้อยเปอร์เซ็นต์ สถานะของคิวบิตแท้จริงแล้วไม่จำเป็นต้องเป็น 0 หรือ 1 เสมอไป ขึ้นอยู่กับตัว measurement แต่ในขั้นต้นให้เข้าใจกันแบบนี้ก็พอครับ
ทำทุกอย่างพร้อมกันในคราวเดียว
นักวิทยาศาสตร์คาดการณ์ไว้ว่าคุณสมบัติ superposition ของคิวบิตจะเป็นคุณสมบัติหนึ่งที่สามารถนำไปสร้างอัลกอริทึมสำหรับคอมพิวเตอร์ควอนตัม และจะช่วยให้ประมวลผลได้รวดเร็วขึ้นกว่าเดิม ลองดูสถานการณ์สมมติต่อไปนี้ประกอบ (หลังจากนี้จะใช้คำว่า “อัลกอริทึมควอนตัม” เรียกอัลกอริทึมสำหรับคอมพิวเตอร์ควอนตัม)
 กระบวนการ quantum parallelism ของคอมพิวเตอร์ควอนตัม (บนขวา) เทียบกับ serial computing (บนซ้าย) และ parallel computing (ล่าง) ของคอมพิวเตอร์คลาสสิก (ที่มาภาพ: งานวิจัยตีพิมพ์ลง IEEE Access Journal)
กระบวนการ quantum parallelism ของคอมพิวเตอร์ควอนตัม (บนขวา) เทียบกับ serial computing (บนซ้าย) และ parallel computing (ล่าง) ของคอมพิวเตอร์คลาสสิก (ที่มาภาพ: งานวิจัยตีพิมพ์ลง IEEE Access Journal)
สมมติว่าเราจะไขล็อก (เปรียบเสมือนฟังก์ชัน) โดยมีกุญแจ (เปรียบเสมือนข้อมูล input) มาให้ 8 ดอก และให้การปลดล็อกสำเร็จหรือไม่สำเร็จเป็น output ของฟังก์ชัน ในบรรดากุญแจทั้ง 8 ดอกนี้จะมีเพียงดอกเดียวเท่านั้นที่สามารถปลดล็อกได้สำเร็จ และการปลดล็อกสำเร็จคือ output ที่เราต้องการ
ถ้าเป็นคอมพิวเตอร์คลาสสิก เราจะต้องหยิบกุญแจขึ้นมาไขทีละดอกจนกว่าจะเจอดอกที่สามารถปลดล็อกได้ หรือไม่งั้น เราอาจจะพิมพ์ล็อกขึ้นมาหลายๆ ชุด แล้วให้กุญแจแต่ละดอกไขของใครของมันพร้อมๆ กันได้ โดยแลกกับการใช้ทรัพยากรที่เพิ่มขึ้น
แต่สำหรับคอมพิวเตอร์ควอนตัมนั้น ตัวกุญแจสามารถสร้างสถานะ superposition เสมือนกับว่ามีอยู่ 8 ดอกพร้อมๆ กัน แล้วปลดล็อกพร้อมกันทีเดียวได้เลย กระบวนการในลักษณะนี้ถูกเรียกว่าการประมวลผลควอนตัมแบบขนาน (quantum parallelism)
กระบวนการ quantum parallelism เป็นจุดเริ่มต้นของกระบวนการในอัลกอริทึมควอนตัมหลายๆ ตัว แต่นั่นยังไม่ใช่หัวใจสำคัญของอัลกอริทึมควอนตัม เพราะถ้าเป้าหมายจริงๆ คือการหากุญแจดอกที่ปลดล็อกได้ กระบวนการนี้ก็ไม่ช่วยอะไร
อัลกอริทึมที่เร็วขึ้นจนต้องชายตามอง
Scott Aaronson ผู้ช่วยศาสตราจารย์ด้านวิทยาการคอมพิวเตอร์แห่ง MIT ผู้เขียนหนังสือ “Quantum Computing since Democritus” ให้สัมภาษณ์กับ The Washington Post ว่าแท้จริงแล้วหัวใจสำคัญของอัลกอริทึมควอนตัมคือการดัดแปลงสถานะ superposition ของคิวบิตเพื่อให้ได้คำตอบที่ต้องการ โดยอาจจะเพิ่มโอกาสของการวัดได้คำตอบที่ต้องการให้สูงขึ้น และลดโอกาสของการวัดได้คำตอบที่ผิดให้น้อยลง
เพื่อให้เห็นภาพมากขึ้น ผมจะขอพูดถึงอัลกอริทึมควอนตัม 2 ตัวด้วยกัน ได้แก่ Grover’s search algorithm และ Shor’s algorithm
Grover’s search algorithm: อัลกอริทึมค้นหาข้อมูลที่เร็วทะลุขีดจำกัด
อัลกอริทึมบนคอมพิวเตอร์คลาสสิกสำหรับค้นหาข้อมูลแบบ unstructured (ไม่มีระเบียบ ไม่มีการจัดเรียงหรือทำอะไรมาก่อน) ที่เร็วที่สุดแล้วคือ linear search คือไล่หาไปเรื่อยๆ จนกว่าจะเจอนั่นเอง ดังนั้น ถ้าข้อมูลดังกล่าวมีจำนวน 1,000,000 ชุด เหตุการณ์เลวร้ายที่สุดคือเราจะหาข้อมูลที่ต้องการเจอในรอบที่หนึ่งล้าน
แต่อัลกอริทึมควอนตัมของ Lov Grover นั้นสามารถค้นหาข้อมูลแบบ unstructured ได้ เลวร้ายสุดๆ ก็ใช้เวลาเพียงประมาณ 1,000 รอบเท่านั้น แล้วมันทำได้อย่างไร ขอให้สังเกตกราฟด้านล่างนี้ประกอบ
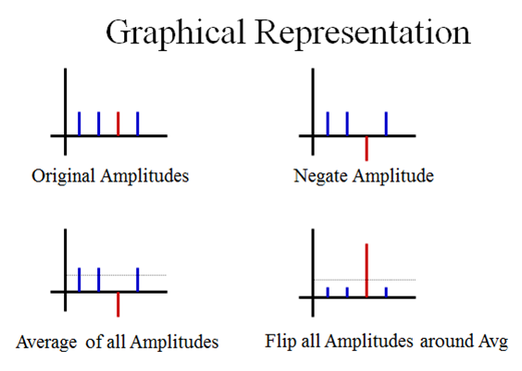
กราฟแสดงความน่าจะเป็นของการวัดข้อมูลคิวบิตแล้วได้ผลลัพธ์เป็นสถานะ 00, 01, 10, 11 ตามลำดับ ที่เปลี่ยนไปเมื่อผ่านอัลกอริทึมของ Grover (ที่มาภาพ: Vinayak Bhatt บน Quora)
สมมติว่ามีข้อมูลอยู่ 4 ชุด ได้แก่ ข้อมูลที่ตำแหน่ง 00, 01, 10, 11 ตามลำดับ โดยข้อมูลที่เราต้องการอยู่ที่ตำแหน่ง 10 ซึ่งกราฟแท่งจะถูกไฮไลต์ด้วยสีแดง เราจะต้องเตรียมคิวบิตไว้ทั้งหมด 4 สถานะ คือสถานะ 00, 01, 10, และ 11 ตามตำแหน่งของข้อมูล
อัลกอริทึมของ Grover จะมีกระบวนการดังนี้
- เตรียมสถานะ superposition ของคิวบิต ให้ความน่าจะเป็นของการวัดคิวบิตแล้วได้สถานะต่างๆ นั้นมีค่าเท่ากัน กราฟซ้ายบน จะเห็นได้ว่าคิวบิตมีความน่าจะเป็น (amplitude) ของการวัดแล้วได้สถานะต่างๆ เท่ากัน
- ทำการกลับเครื่องหมายความน่าจะเป็นของการวัดคิวบิตแล้วได้ตำแหน่งของข้อมูลที่ต้องการค้นหา จากบวกให้กลายเป็นลบ กราฟขวาบน จะเห็นได้ว่ากราฟแท่งสีแดงจะโตกลับข้างจากกราฟแท่งสีม่วง
- หาค่าเฉลี่ยของความน่าจะเป็นของการวัดคิวบิตแล้วได้สถานะต่างๆ ทุกสถานะ (สมมติให้เท่ากับ A) กราฟซ้ายล่าง เส้นประแสดงปริมาณค่าเฉลี่ยเทียบกับ amplitude ของแต่ละสถานะ
- คำนวณความน่าจะเป็นของสถานะข้อมูลทุกๆ สถานะเสียใหม่ ให้แต่ละสถานะมีค่าเท่ากับ 2A - ai (เมื่อ ai แทนค่าความน่าจะเป็นของการวัดคิวบิตแล้วได้สถานะ i) เนื่องจากความน่าจะเป็นของสถานะ 10 มีค่าเป็นลบ ดังนั้น สูตรการคำนวณดังกล่าวจะไปเพิ่มค่าความน่าจะเป็นให้สถานะ 10 มีโอกาสถูกวัดเจอได้มากขึ้น [2A - (-a10) = 2A + a10] ในขณะที่สถานะอื่นๆ จะมีโอกาสวัดเจอน้อยลง
- กลับเครื่องหมายความน่าจะเป็นของการวัดคิวบิตแล้วได้สถานะที่ต้องการค้นหา จากลบให้กลับมาเป็นบวก กราฟขวาล่าง แสดงความน่าจะเป็นของสถานะข้อมูลเมื่อผ่านขั้นตอนนี้
นักวิทยาศาสตร์พิสูจน์มาแล้วว่า หากนำคิวบิตวนเข้ากระบวนการข้างต้นตั้งแต่ข้อ 2–5 ซ้ำไปเรื่อยๆ ประมาณ sqrt(N) รอบ เมื่อ N แทนจำนวนชุดข้อมูล ก็จะทำให้มีโอกาสวัดคิวบิตแล้วได้ตำแหน่งของข้อมูลที่เราต้องการสูงสุด
*** ถ้ายังงงๆ อยู่ ผมเขียนอธิบายอัลกอริทึมแบบละเอียดไว้ในคอมเมนต์ครับ
Shor’s algorithm: อัลกอริทึมหาตัวประกอบเฉพาะของจำนวนเต็มขนาดใหญ่
ตัวประกอบเฉพาะของจำนวนเต็มขนาดใหญ่ (เช่น 3233 = 53 × 61 แต่ในความเป็นจริงใช้ตัวเลขใหญ่กว่านี้มาก) ต้องใช้เวลานานมาก อาจนานนับร้อยปีกว่าจะหาเจอ นั่นทำให้กระบวนการเข้ารหัสทั้งหลายที่นิยมใช้กันในปัจจุบัน เช่น กระบวนการเข้ารหัส RSA พึ่งความยากของปัญหานี้ในการเข้ารหัสข้อมูล แต่ในปี 1994 Peter Shor คิดอัลกอริทึมควอนตัมเพื่อแก้ปัญหานี้ได้สำเร็จโดยเทียบกันแล้วอาจใช้เวลาเพียงไม่กี่ปีเท่านั้น (สำหรับผู้เรียนวิทยาการคอมพิวเตอร์ ดูการเทียบ time complexity และ big O notation ของแต่ละอัลกอริทึมใน Wikipedia)

Peter Shor นักคณิตศาสตร์ประยุกต์ ศาสตราจารย์ประจำ MIT (ที่มาภาพ: Heidelberg Laureate Forum)
หลักการอัลกอริทึมของ Shor จะอาศัยการลดรูปปัญหา (problem reduction) โดยเอาวิธีการหาคาบของฟังก์ชัน f(x) = ax mod M (เมื่อ M แทนจำนวนเต็มบวกที่จะแยกตัวประกอบ และ a คือจำนวนเต็มบวกที่น้อยกว่า M) มาหาตัวประกอบเฉพาะของจำนวนเต็มแทน พูดง่ายๆ คือ ถ้าเราหาคาบของฟังก์ชันนี้ได้ เราก็จะสามารถหาตัวประกอบเฉพาะของจำนวนเต็มได้
ในการหาคาบของฟังก์ชันนั้นจะใช้คอมพิวเตอร์ควอนตัม แต่เนื่องจากกระบวนการมีความซับซ้อนมาก… (ก.ไก่ ล้านตัว) จึงขอบอกเพียงแค่ว่าในขั้นตอนหนึ่ง คิวบิตสถานะ superposition ที่ผ่านการคำนวณฟังก์ชันแล้ว จะถูกนำเข้าสู่กระบวนการ quantum Fourier transform ซึ่งจะทำให้มีโอกาสสูงที่วัดคิวบิตแล้ว จะได้ตัวเลขที่สามารถนำไปคำนวณต่อเพื่อหาคาบของฟังก์ชันต่อไป และพอได้คาบของฟังก์ชันแล้ว เราก็เอาตัวเลขนี้ไปคำนวณกลับให้ได้ตัวประกอบเฉพาะตัวหนึ่งของจำนวนเต็มนั่นเอง
อัลกอริทึมของ Shor สร้างผลกระทบต่อวิทยาการเข้ารหัสอย่างมหาศาล หากมีคนที่สามารถสร้างคอมพิวเตอร์ควอนตัมขนาดใหญ่ขึ้นมาได้แล้วละก็ ข้อมูลเข้ารหัสทั้งหมดจะตกอยู่ในความเสี่ยงทันที (แต่ไม่ต้องกังวลไปครับ นักวิทยาศาสตร์ได้เตรียมวิธีการเข้ารหัสแบบอื่นๆ เพื่อหลีกเลี่ยงปัญหานี้ไว้บ้างแล้ว แต่เราจะไม่พูดถึงในบทความนี้)
อัลกอริทึมทั้งสองตัวอย่างที่ยกมานั้น เป็นเพียงอัลกอริทึมในเชิงทฤษฎีที่ยังต้องมีการทดสอบรันบนคอมพิวเตอร์ควอนตัมจริงๆ อย่างเมื่อเดือนเมษายนที่ผ่านมา ก็มีคนทดสอบแยกตัวประกอบของ 200099 ด้วยอัลกอริทึมของ Shor โดยใช้คอมพิวเตอร์ควอนตัมได้แล้ว
อย่างไรก็ตาม การสร้างเครื่องคอมพิวเตอร์ควอนตัมให้ใช้งานได้จริงนั้นเป็นไปยากมาก เนื่องจากคอมพิวเตอร์จะต้องรักษาสถานะ superposition ของคิวบิตที่มีความเสถียรต่ำไว้ให้ได้
Superposition ก็มีวันสูญสลาย อุปสรรคสำคัญของการสร้างคอมพิวเตอร์ควอนตัม
เนื่องจากคิวบิตเป็นอนุภาคเล็ก และอยู่ท่ามกลางอนุภาคอื่นๆ รายล้อมนับพัน จึงมีโอกาสสูงมากที่จะถูกอนุภาคในสภาพแวดล้อมเข้าไปรบกวนจนสถานะเปลี่ยนแปลงไป ทำให้ข้อมูลในสถานะ superposition สูญเสียไปด้วย เหตุการณ์ทั้งหมดนี้เกิดขึ้นเพียงแค่เสี้ยววินาทีเท่านั้น นอกจากนี้ ในทฤษฎี no-cloning บอกอีกว่า เราไม่สามารถคัดลอกสถานะของคิวบิตที่ไม่ทราบสถานะตัวหนึ่งไปยังคิวบิตอีกตัวหนึ่งได้ ทำให้การคัดลอกคิวบิตเพื่อสำรองข้อมูลเป็นไปไม่ได้ด้วย
คอมพิวเตอร์ควอนตัมจึงต้องถูกออกแบบขึ้นโดยปกป้องคิวบิตไม่ให้ถูกสภาพแวดล้อมรบกวน เพื่อให้คิวบิตคงสถานะ superposition ให้ได้นานที่สุดจนกว่าการคำนวณจะเสร็จสิ้น สิ่งเหล่านี้ เป็นอุปสรรคที่ทำให้เครื่องคอมพิวเตอร์ควอนตัมขนาดใหญ่ไม่สามารถสร้างขึ้นมาได้โดยง่ายนัก นักวิทยาศาสตร์จึงต้องหาเทคนิคอื่นๆ เสริมเพื่อสร้างเครื่องคอมพิวเตอร์ควอนตัมที่สามารถใช้งานได้จริง
การสร้างคอมพิวเตอร์ควอนตัมที่คงทนต่อสภาพแวดล้อมภายนอก ถือเป็นหลักเกณฑ์สำคัญข้อหนึ่งในการสร้างคอมพิวเตอร์ควอนตัมซึ่งตั้งขึ้นโดยนักฟิสิกส์ทฤษฎีนาม David DiVincenzo เรียกว่า DiVincenzo’s criteria มีทั้งหมด 5 หัวข้อ ดังนี้
- สมบัติทางกายภาพที่แทนสถานะ 0, 1, และ superposition ของคิวบิต และการขยายระบบด้วยการเพิ่มจำนวนคิวบิต
- สถานะเริ่มต้นของคิวบิตก่อนใช้คำนวณ
- ระบบที่คงทนต่อสภาพแวดล้อมภายนอก และการรักษาสถานะของคิวบิตตลอดการคำนวณ
- เกตควอนตัมแบบ universal ในระบบ (เหมือนกับเกต NAND หรือเกต NOR บนคอมพิวเตอร์คลาสสิก)
- กระบวนการวัดคิวบิตภายหลังการคำนวณ
- สมบัติทางกายภาพคิวบิตที่ใช้สื่อสารระหว่างระบบ (flying qubits) ที่อาจจะแตกต่างจากคิวบิตในระบบ (stationary qubits) และการแปลงข้อมูลคิวบิตแต่ละชนิดระหว่างกัน
- การส่งผ่าน (transmit) คิวบิตระหว่างระบบในระยะไกล
กรณีที่จะสร้างคอมพิวเตอร์ควอนตัมสำหรับการสื่อสาร จะมีหลักเกณฑ์เพิ่มอีก 2 หัวข้อ คือ
 David DiVincenzo นักฟิสิกส์ทฤษฎี ผู้อำนวยการสถาบันนาโนอิเล็กทรอนิกส์ทฤษฎีแห่งสถาบัน Peter Grünberg ใน Jülich ประเทศเยอรมัน และศาสตราจารย์ประจำสถาบันสารสนเทศควอนตัมแห่งมหาวิทยาลัย RWTH Aachen ประเทศเยอรมัน (ที่มาภาพ: ศูนย์วิจัย Forschungszentrum Jülich)
David DiVincenzo นักฟิสิกส์ทฤษฎี ผู้อำนวยการสถาบันนาโนอิเล็กทรอนิกส์ทฤษฎีแห่งสถาบัน Peter Grünberg ใน Jülich ประเทศเยอรมัน และศาสตราจารย์ประจำสถาบันสารสนเทศควอนตัมแห่งมหาวิทยาลัย RWTH Aachen ประเทศเยอรมัน (ที่มาภาพ: ศูนย์วิจัย Forschungszentrum Jülich)
เราไปถึงไหนกันแล้ว
ปัจจุบัน หลายๆ สถาบันทั่วโลกทั้งภาครัฐ ภาคเอกชน และมหาวิทยาลัย ต่างก็เร่งมือให้การสนับสนุนและผลิตงานวิจัยด้านการประมวลผลควอนตัมกันมากขึ้นเรื่อยๆ จนเรียกได้ว่าเป็นยุคทองของการวิจัยด้านนี้ โดยส่วนใหญ่แล้วจะมุ่งสร้างคอมพิวเตอร์ควอนตัมให้รองรับคิวบิตจำนวนมาก เพราะยิ่งมีคิวบิตในระบบมาก นักวิจัยก็จะสามารถใช้ทดลองรันอัลกอริทึมที่ซับซ้อน หรือรันด้วย input ขนาดใหญ่เพื่อทดสอบประสิทธิภาพของมันได้
เป้าหมายสูงสุดของการวิจัยอย่างหนึ่ง คือการสร้างคอมพิวเตอร์ที่สามารถรันอัลกอริทึมใดๆ ก็ได้ นักวิทยาศาสตร์เรียกคอมพิวเตอร์ควอนตัมประเภทนี้ว่าเป็น universal ซึ่ง IBM คาดการณ์ไว้ว่าอาจจะต้องใช้คิวบิตมากกว่าหนึ่งแสนตัวเลยทีเดียว การสร้างคอมพิวเตอร์สเกลใหญ่และมีความซับซ้อนแบบนี้อาจต้องรอกันอีกนาน เพราะเรายังต้องหาองค์ความรู้ที่เกี่ยวข้องกับการจัดการคิวบิตในปริมาณมากๆ ทั้งกระบวนการตรวจสอบและแก้ไขข้อผิดพลาด วัสดุทางกายภาพอื่นๆ ที่ใช้แทนคิวบิต จนไปถึงสถาปัตยกรรมต่างๆ ของคอมพิวเตอร์ควอนตัม
อย่างไรก็ตาม วิทยาการต่างๆ ที่วิจัยกันออกมานั้นก็ทำให้การสร้างคอมพิวเตอร์ควอนตัมสเกลใหญ่เข้าใกล้ความจริงมากขึ้นเรื่อยๆ บทความนี้จะพูดถึงงานวิจัยจากสองสถาบัน ได้แก่ IBM และกูเกิล
IBM: เจ้าพ่อแห่งวงการคอมพิวเตอร์ควอนตัม
IBM มีประวัติในด้านการสนับสนุนงานวิจัยด้านคอมพิวเตอร์ควอนตัมมาตั้งแต่ช่วงถือกำเนิดของศาสตร์นี้แล้ว ที่มา - IBM Quantum Computing
ปี 1981 IBM ร่วมกับ MIT จัดงานประชุมทางวิชาการ (conference) ครั้งแรก ในหัวข้อ “The Physics of Computation” ปรากฏว่าในงานนี้ Richard Feynman นักฟิสิกส์ทฤษฎี ได้ไปเสนอไอเดียเกี่ยวกับการสร้างเครื่องคอมพิวเตอร์ควอนตัมเพื่อจำลองระบบควอนตัมไว้ (quantum simulation) ถือว่าเป็นการบุกเบิกศาสตร์การประมวลผลควอนตัมครั้งแรกๆ ในประวัติศาสตร์
ปี 1984 Charles Bennett นักวิทยาศาสตร์จาก IBM Research และ Gilles Brassard นักวิจัยจาก Université de Montréal ประเทศแคนาดา เสนอไอเดียการเข้ารหัสข้อมูลด้วยหลักการฟิสิกส์ควอนตัมในนาม “โปรโตคอล BB84” ถือเป็นโปรโตคอลการเข้ารหัสข้อมูลควอนตัมตัวแรกของโลก และในปี 1993 Bennett, Brassard และคณะก็เป็นกลุ่มแรกที่นำเสนอกระบวนการ quantum teleportation ซึ่งเป็นการส่งข้อมูลคิวบิตระยะไกลโดยใช้หลักการของ quantum entanglement
ปี 1996 David DiVincenzo ซึ่งทำงานที่ IBM ในสมัยนั้น นำเสนอหลักเกณฑ์ของการสร้างคอมพิวเตอร์ควอนตัม 7 ข้อ ในนาม DiVincenzo’s criteria หลักเกณฑ์นี้ก็ถูกนำไปใช้ในการสร้างเครื่องคอมพิวเตอร์ควอนตัมในช่วงเวลาต่อมา
ปี 2001 IBM ประสบความสำเร็จในการแยกตัวประกอบเฉพาะของ 15 (= 3 × 5) ด้วยการรันอัลกอริทึมของ Shor บนคอมพิวเตอร์ควอนตัมประเภท NMR (nuclear magnetic resonance)
ปี 2012 IBM พบเทคนิคการสร้างคิวบิตที่สามารถรักษาสถานะ superposition ของคิวบิตไว้ได้นานถึง 100 ไมโครวินาที มากขึ้นเป็น 2–4 เท่าจากเดิม
ปี 2015 IBM พัฒนาเทคนิคการตรวจจับและแก้ไขความผิดพลาดของข้อมูลคิวบิต ทั้งความผิดพลาดแบบ bit-flip และความผิดพลาดแบบ phase-flip และพัฒนาเทคนิคการตรวจสอบความผิดพลาดของคิวบิตระหว่างกันด้วยการเรียงคิวบิตเป็นสี่เหลี่ยมจัตุรัส ข่าวเก่า - IBM ประกาศความสำเร็จด้านการวิจัยควอนตัมคอมพิวเตอร์
และเมื่อเดือนพฤษภาคมที่ผ่านมา IBM เปิดตัวคลาวด์ประมวลผลควอนตัมชื่อว่า IBM Quantum Experience โดยเปิดโอกาสให้นักวิจัย นักศึกษา และบุคคลทั่วไป สามารถเข้าไปทดลองใช้คอมพิวเตอร์ควอนตัมแบบ universal จำนวน 5 คิวบิต IBM กล่าวเพิ่มเติมว่าในทศวรรษหน้าจะสร้างคอมพิวเตอร์ควอนตัมแบบ universal ที่มีจำนวนคิวบิต 50–100 ตัว ข่าวเก่า - IBM เปิดตัวคลาวด์ทดลองใช้งานคอมพิวเตอร์ควอนตัมสำหรับนักวิจัย
คลิปนำเสนอ IBM Quantum Experience
กูเกิล: คอมพิวเตอร์ควอนตัมสำหรับงานด้าน AI
ปี 2013 กูเกิลจัดตั้ง Quantum Artificial Intelligence Lab (QuAIL) โดยได้รับความร่วมมือจากศูนย์วิจัย NASA Ames และ USRA (Universities Space Research Association) โดยซื้อเครื่องคอมพิวเตอร์ควอนตัมจากบริษัท D-Wave Systems แม้ว่าคอมพิวเตอร์ D-Wave Two ที่ซื้อมาในสมัยนั้นจะมีคิวบิตมากถึง 512 ตัว แต่ก็ไม่ได้เป็นคอมพิวเตอร์แบบ universal
วัตถุประสงค์หลักในการจัดตั้งแล็บของกูเกิล คือเพื่อศึกษาความเป็นไปได้ในการนำคอมพิวเตอร์ควอนตัมมาใช้ในงานด้าน machine learning โดยโฟกัสไปที่ปัญหาประเภท optimization นั่นคือปัญหาการเลือกสิ่งที่ดีที่สุดภายใต้เงื่อนไขและทรัพยากรจำกัด ที่มา - Google Research Blog
ปี 2014 กูเกิลขยายไปทำวิจัยด้านโปรเซสเซอร์สำหรับคอมพิวเตอร์ควอนตัมเพิ่มเติม โดยได้ทีมวิจัย Martinis Group จากมหาวิทยาลัย UC Santa Barbara มาช่วยเสริมทัพอีกแรง ที่มา - Google Research Blog
ปี 2015 กูเกิลเผยผลการวิจัยคอมพิวเตอร์ควอนตัม D-Wave ว่าสามารถแก้โจทย์ปัญหาได้เร็วกว่าอัลกอริทึมแบบเดิม ทั้ง simulated annealing และ quantum Monte Carlo มากถึง 108 เท่าเลยทีเดียว หลังจากที่ผ่านมา คอมพิวเตอร์ D-Wave เคยถูกตั้งข้อครหาถึงประสิทธิภาพของมัน ข่าวเก่า - กูเกิลเผยผลการวิจัยควอนตัมคอมพิวเตอร์ D-Wave แก้ปัญหาได้เร็วขึ้น 10^8 เท่า
และเมื่อเดือนมิถุนายนที่ผ่านมา กูเกิลก็เผยความสำเร็จในการสร้างชิพคอมพิวเตอร์ควอนตัมขนาด 9 คิวบิต สามารถทำงานแบบ universal ได้ และมีระบบตรวจสอบและแก้ไขความผิดพลาดของคิวบิต (quantum error correction) ทำให้ในอนาคต นักวิจัยจะสามารถสร้างชิพที่มีจำนวนคิวบิตมากขึ้นเพื่อนำไปสร้างเป็นคอมพิวเตอร์ควอนตัมขนาดใหญ่ได้ ข่าวเก่า - นักวิจัยกูเกิลสร้างคอมพิวเตอร์ควอนตัมแบบ “ลูกผสม” เข้าใกล้สู่การสร้างเพื่อใช้งานทั่วไป
คลิปเปิดตัว Quantum Artificial Intelligence Lab ของกูเกิล
บทสรุป
บทความนี้อาจจะข้ามเนื้อหาบางส่วนเกี่ยวกับคอมพิวเตอร์ควอนตัมไปบ้าง (เช่น quantum entanglement, quantum simulation) แต่ก็เป็นการนำเสนอข้อมูลเกี่ยวกับคอมพิวเตอร์ควอนตัมในเบื้องต้น ซึ่งผมคิดว่าเพียงพอที่จะทำให้เห็นภาพได้ว่ามันคืออะไร มีดีกว่าคอมพิวเตอร์ที่เราใช้กันอยู่อย่างไร จะขอสรุปเพื่อเก็บประเด็นต่างๆ อีกสักรอบ
- คอมพิวเตอร์ควอนตัมคือคอมพิวเตอร์ที่ประมวลผลด้วยหลักการของฟิสิกส์ควอนตัม
- ด้วยความพิเศษของสถานะ superposition บนคิวบิต ทำให้มีการคิดค้นอัลกอริทึมควอนตัมบางตัวที่เร็วกว่าอัลกอริทึมบนคอมพิวเตอร์ทั่วๆ ไป เช่น อัลกอริทึมของ Grover ช่วยค้นหาข้อมูลได้เร็วขึ้น อัลกอริทึมของ Shor สามารถแยกตัวประกอบได้เร็วขึ้น
- หากสร้างคอมพิวเตอร์ควอนตัมขึ้นมาสำเร็จ ระบบการเข้ารหัสข้อมูลทั่วโลกจะตกอยู่ในความเสี่ยงทันที แต่นักวิทยาศาสตร์ได้เตรียมหาทางหนีทีไล่ไว้แล้ว
- คอมพิวเตอร์ควอนตัมไม่ได้สร้างกันได้ง่ายๆ เพราะสถานะทางควอนตัมของคิวบิตนั้นเปราะบางต่อสภาพแวดล้อมมาก
- ปัจจุบัน ทั่วโลกกำลังวิจัยเพื่อสร้างคอมพิวเตอร์ควอนตัม และค้นหาขีดความสามารถของมันต่อไป
เราอาจจะไม่ได้เห็นคอมพิวเตอร์ควอนตัมในอนาคตอันใกล้นี้ และอาจจะยังไม่ทราบได้แน่ชัดว่ามันจะมีประโยชน์ต่อมวลมนุษยชาติมากน้อยแค่ไหน แต่การสนับสนุนงานวิจัยก็จะช่วยทำให้เราเดินทางเข้าสู่ยุคต่อไปของคอมพิวเตอร์ได้เร็วขึ้น หรืออย่างน้อย แม้จะมีคนพบว่าคอมพิวเตอร์ควอนตัมไม่คุ้มที่จะสร้าง เราก็ได้เก็บเกี่ยวองค์ความรู้ในระหว่างทางไว้ เผื่อว่าจะใช้กรุยทางให้เกิดประโยชน์ในศาสตร์ด้านอื่นๆ ต่อไปได้
ยินดีต้อนรับสู่ยุคทองของการวิจัยคอมพิวเตอร์ควอนตัมครับ :)
แหล่งข้อมูลอ้างอิง
- Quantum Computing: A Gentle Introduction โดย Eleanor Rieffel และ Wolfgang Polak ผมใช้หนังสือเล่มนี้เป็นแหล่งอ้างอิงหลัก อันที่จริงผมอ่านแล้วมันไม่ค่อย gentle เท่าไหร่แฮะ
- A Brief History of Quantum Computing โดย Simon Bone และ Matias Castro
- A tale of two qubits: how quantum computers work โดย Joseph B. Altepeter ผ่านทาง Ars Technica
- Grover’s Quantum Search Algorithm โดย Craig Gidney อธิบายอัลกอริทึมของ Grover ด้วยภาพกราฟฟิกของสถานะคิวบิต
- Shor, I’ll do it โดย Scott Aaronson อธิบายอัลกอริทึมของ Shor โดยไม่พูดถึงคณิตศาสตร์ระดับสูงแต่อย่างใด
- Quantum Algorithm Zoo โดย Stephen Jordan แหล่งรวบรวมข้อมูลเกี่ยวกับอัลกอริทึมควอนตัม

แก้ไขครั้งที่ 1: เพิ่มคำอธิบายเกี่ยวกับอัลกอริทึม Grover ไว้ในคอมเมนต์ใต้บทความ
แก้ไขครั้งที่ 2: เพิ่มคลิปอธิบายสถานะ quantum superposition ของอนุภาค

Get latest news from Blognone
Follow @twitterapi



Comments
บทความก็เข้าใจยากแล้ว เจอมุกมันฝรั่งเข้าไปยิ่งไม่เข้าใจไปกันใหญ่
ตรงนี้เป็นมุมของคนงงมุข มันฝรั่งใช่ไหมครับ ขอยืนด้วยคน
เข้ามาแสดงจุดยืนว่างงด้วยคน
I need healing.
อธิบายฉันที งง มุข ด้วยคน 555
มือใหม่!! ใหม่จริงๆนะ
potato เป็น meme หมายความว่าห่วย
ผมไม่แน่ใจว่าต้นกำเนิดมาจากไหน แต่ผมเจอมุกนี้บ่อยมากใน www.9gag.com เวลามีคนโพสบทความยาว ๆ แล้วมักจะปิดท้ายด้วยรูปมันฝรั่งและประโยค "Sorry for the long post, here's a potato." เสมอ แต่ถ้าบทความยาว ๆ อันไหนไม่มีรูปมันฝรั่งปิดท้าย ผู้คนก็จะแห่เข้าไป comment ใต้บทความนั้นว่า "Where is my f**king potato?" จนกลายเป็นธรรมเนียมไปแล้ว
(อ้างจาก https://www.quora.com/What-does-Sorry-for-the-long-post-heres-a-potato-mean-in-9GAG) มีคนบอกว่าต้นกำเนิดมาจากมุกในเกม Portal 2 นะครับ แล้วเกมนี้ก็ดังมาก ๆ ใน 9gag คนก็เลยถือเป็นธรรมเนียมปฏิบัติไปมั้ง ส่วนตัวผมเล่น Portal 1+2 จบแล้ว แต่มุกในเกมมันเป็นมุกฝืด ๆ (ตั้งใจให้ฝืด) ผมเลยไม่ค่อยอินเท่าไร
What does "Sorry for the long post, here's a potato" mean in 9GAG?
potato = im so random xd
เอามาจากมุกใน 9gag ตามที่คุณ Manta ว่านั่นแหละครับ
เป็นมุขจากเกม Portal 2 ครับ (ซึ่งชาว Geek เองไม่น่าพลาด)
โดยในเนื้อเรื่อง คอมพิวเตอร์ที่ชื่อ GLaDos ซึ่งเป็นคู่ปรับเราในภาคแรกต้องมาช่วยเราในภาค 2 แต่ดันเกิดอุบัติเหตุมาระเบิดเสียก่อน นางเอกในเนื้อเรื่องจึงจับนางใส่มันฝรั่งแล้วให้อาศัยพลังงานไฟฟ้าจากมันฝรั่งชวยนางเอกจนจบเกม ประเด็นที่ชาวเกมเมอร์ให้ข้อสังเกตคือ เกมยาวมากก และนางก็ใช้ไฟฟ้าจากมันฝรั่งทั้งเกมจนจบจริงๆ เลยกลายเป็นมุขที่มาของการที่ทำอะไรแล้วมึนๆ แก้ปัญหาไม่ออก ก็เอามันฝรั่งไปซะ (นัยว่า เอาไปเป็นพลังงาน) นั่นแหล่ะ
เอ ที่ผมเล่นนี่ไม่อุบัติเหตุนะครับ ซัดกันโต้งๆ เลย
แห่ะๆเขียนจากความทรงจำอันลางเลือนครับ ยอมรับว่ามีผิดไปจากนี้บ้าง
อ่อ ผมนึกว่ามันมีหลายทาง 555 รับทราบครับ
สรุปก็คือ เอามันฝรั่งไปเป็นพลังงานนี่เอง เพราะโพสยาวมาก ฮาล่ะทีนี้ ฮ่าๆ
เก็บไว้อ่านทวน
อ่านแล้วงงแต่ก็ตั้งใจอ่าน
เหมือนรู้คำตอบอยู่แล้ว(เข้าใจว่าคือคำตอบที่ต้องการ)แต่จะทำยังไงให้ได้คำตอบนั้นซื่งการใช้ Quantum computer ช่วยให้มันได้เร็วขึ้นเหมือนที่ในบทความ ต้องการ 10 แต่จะทำยังไงให้หา 10 ได้เร็วที่สุดถ้ามีคำตอบ 1,000,000 คำตอบถ้าเป็นปรกติ จะต้องลองไป 1 ใน 1,000,000 แต่ Quantum computer มีวิธีการที่ทำให้ได้คำตอบนั้นจากการวัดค่า Superposition แทน
อันนี้จากความเข้าใจผมทั้งสิ้นครับ
สงสัยผมจะแก่เกินเรียนอะไรใหม่ ๆ แล้ว อ่านไป งงไป ไม่ได้ทำให้สถานะตัวเองเปลี่ยนจาก "ไม่รู้" เป็น "รู้" ได้เลย หรือว่าเรามีสถานะเป็น "รู้ว่าไม่รู้" หว่า...
อาจจะเป็นสถานะ Superposition ครับ #มุขQuantum
555 อารมณ์เดียวกันเลย
อ่านแล้วเข้าใจน้อยมาก น่าจะเกิดจากไม่มีพื้นฐานเลยในเรื่องนี้
แล้วก็คิดเลยไปว่าอนาคตเด็กรุ่นใหม่ ๆ จะต้องเขียนโปรแกรมเพื่อไปรันบน Quantum Computer ให้ได้ก็ยิ่งรู้สึกสงสารเด็กรุ่นใหม่ ๆ - -
สงสารทำไม ตื่นเต้นดีออก
งง ตรง graphical representation ว่ามันรู้ได้ไงว่า แท่งสีแดงอยู่ตรงนั้น ถ้ามันรู้ตั้งแต่แรกจะต้องมา weight หาทำไมอีกอะครับ
อ้อ! จริงๆ ในอัลกอริทึมเค้าจะกำหนดฟังก์ชัน f มาให้เป็นตัว evaluate ข้อมูลอีกทีครับ โดยใส่ criteria ไปก่อนว่าข้อมูลที่เราต้องการมีหน้าตายังไง
สมมติให้ input ของฟังก์ชันคือข้อมูลตำแหน่ง x จะได้ว่า f(x) = 0 เมื่อข้อมูลนั้นไม่ใช่สิ่งที่เราต้องการ และ f(x) = 1 เมื่อข้อมูลนั้นเป็นสิ่งที่เราต้องการ
โดยปกติ ถ้าจะเช็คข้อมูลว่าอยู่ตำแหน่งไหน ในคอมพิวเตอร์คลาสสิกจะต้องยัด input x เข้าไปทีละตัว เพื่อดูว่าตัวไหนให้คำตอบเป็น 1 แต่สำหรับคอมพิวเตอร์ควอนตัมก็ยัด x เข้าสถานะ superposition (ขั้นตอนที่ 1) แล้วเข้าฟังก์ชัน f มันก็จะให้คำตอบมาทีเดียวเลยว่าข้อมูลที่ต้องการอยู่ตรงไหน
ปัญหาต่อมาคือ เราจะ extract ข้อมูลที่ว่านี้ออกมายังไง (อย่าลืมว่าคิวบิตในสถานะ superposition เรายังเอาไปใช้ประโยชน์อะไรไม่ได้จนกว่าจะวัด) Grover ก็เลยคิดอัลกอริทึมที่ว่าขึ้นมาครับ โดยอาจจะกำหนดฟังก์ชันเพิ่มเติมว่า ถ้า f(x) = 1 เราต้องเปลี่ยนความน่าจะเป็นของการวัดข้อมูลได้ตำแหน่งนั้นให้ติดลบนะ แต่ถ้า f(x) = 0 ก็ไม่ต้องเปลี่ยนค่าอะไรครับ
ขอบคุณครับ เห็นโพสข้างล่าง
ผมคงโง่เกิน = ="
ขออธิบายเรื่องอัลกอริทึมของ Grover แบบละเอียดอีกรอบ เผื่อจะยังงงๆ กันอยู่ว่ามันทำได้ยังไง
สมมติว่ามีข้อมูลอยู่ 4 ชุด ได้แก่ ข้อมูล S, T, U, V อยู่ที่ตำแหน่ง 00, 01, 10, 11 ตามลำดับ และข้อมูลที่เราต้องการคือข้อมูล U (ซึ่งมันอยู่ในตำแหน่งที่ 10 ที่กราฟแท่งไฮไลต์เป็นสีแดงนั่นแหละ แต่สมมติว่าเรายังไม่รู้ว่ามันอยู่ตำแหน่งไหน) เป้าหมายของอัลกอริทึม Grover คือหาให้หน่อยว่า U อยู่ที่ตำแหน่งไหน
เริ่มต้น เราจะสร้างฟังก์ชัน f เพื่อเปรียบเทียบข้อมูลเสียก่อน โดยให้ input ของฟังก์ชันคือ x แทนตำแหน่งของข้อมูล ฟังก์ชันนี้จะดึงข้อมูลในตำแหน่ง x ออกมาแล้วเอามาเปรียบเทียบว่าเท่ากับ U หรือไม่ ถ้าเท่ากับ U ให้ตอบ 1 แต่ถ้าไม่เท่ากับ U ให้ตอบ 0
กรณีของคอมพิวเตอร์คลาสสิก เราจะต้องไล่เช็คข้อมูลไปทีละตำแหน่งต่อไปเรื่อยๆ จนกว่าจะเจอ เช่น เริ่มที่บิต x = 00 เนื่องจาก S ไม่เท่ากับ U จึงทำให้ f(00) = 0 ไล่ไปเรื่อยจนเจอว่าข้อมูลอยู่ที่ตำแหน่ง x = 10 [เนื่องจาก f(10) = 1]
แต่กรณีของคอมพิวเตอร์ควอนตัม เราสามารถเอาคิวบิตไปเข้าสถานะ superposition แล้วเอาไปเข้าฟังก์ชัน f ได้เลย คิวบิตก็จะมีสถานะ x = 00, 01, 10, 11 พร้อมกัน ทำให้เมื่อเอาคิวบิตเข้าฟังก์ชันแล้วจะได้ค่า f(x) = 0, 0, 1, 0 พร้อมกัน
ปัญหาคือ เราไม่สามารถดึงข้อมูลในสถานะ superposition มาใช้งานได้จนกว่าจะทำการวัด ประเด็นสำคัญอยู่ตรงนี้ครับ เมื่อเราทำการวัดคิวบิตในสถานะ superposition ออกมาแล้ว คิวบิตจะต้องเลือกทันทีว่าจะกลายเป็นสถานะใด (00, 01, 10, หรือ 11)
ถ้าเราเอาคิวบิตข้างต้นเข้าฟังก์ชัน f แล้ว พอวัดคิวบิตออกมาจะได้คำตอบอยู่สองแบบคือ 0 กับ 1 อย่างใดอย่างหนึ่งเท่านั้น ข้อมูลที่ได้นี้ไม่ได้ทำให้เรารู้มากขึ้นเลยว่าข้อมูล U อยู่ที่ไหน (เทียบกับกรณีของคอมพิวเตอร์คลาสสิก คือเรายัดตำแหน่ง x เข้าฟังก์ชัน f ทีละตัว เราเลยรู้ได้ว่าข้อมูลตำแหน่ง x เป็นข้อมูลที่ต้องการหรือไม่ จากการดูคำตอบของฟังก์ชัน f เท่านั้น)
Grover จึงคิดอัลกอริทึมควอนตัมสำหรับค้นหาข้อมูลขึ้นมาใหม่ หลักการสำคัญคือ ทำยังไงก็ได้ให้เวลาเราวัดคิวบิตออกมาแล้วจะต้องได้ตำแหน่งของข้อมูลที่ต้องการออกมาให้ได้นั่นเองครับ (คำตอบต้องเป็นสถานะ 10)
ข้อกำหนดอย่างหนึ่งของอัลกอริทึมของ Grover คือ เราจะต้องสร้างฟังก์ชันเปรียบเทียบข้อมูลขึ้นมาก่อน เหมือนๆ กับฟังก์ชัน f นั่นแหละครับ แต่จะต้องเปลี่ยนแปลง output เสียใหม่ จากเดิมที่ output เป็น 0 หรือ 1 ก็เปลี่ยนเป็นให้กลับเครื่องหมายของความน่าจะเป็นของการวัดคิวบิตในตำแหน่งนั้นแทน
กำหนดให้ฟังก์ชัน F เป็นฟังก์ชันเปรียบเทียบข้อมูลที่ว่า โดยให้ input ของฟังก์ชันคือ x แทนตำแหน่งของข้อมูล ฟังก์ชันนี้จะดึงข้อมูลในตำแหน่ง x ออกมาแล้วเอามาเปรียบเทียบว่าเท่ากับ U หรือไม่ ถ้าเท่ากับ U ให้กลับเครื่องหมายความน่าจะเป็นของการวัดคิวบิตซะ (จากบวกกลายเป็นลบ) แต่ถ้าไม่เท่ากับ U ก็ไม่ต้องทำอะไร
อัลกอริทึมของ Grover จะมีกระบวนการดังที่บอกไว้ในบทความครับ ขอยกเอามาเขียนอีกสักรอบ
ไม่รู้ว่าจะช่วยทำให้เข้าใจได้มากขึ้นหรืองงกว่าเดิม เอาเป็นว่าสงสัยตรงไหนเพิ่มเติมถามได้นะฮะ
ขอบคุณครับ
ขอบคุณมากครับ
สงสัยว่า ถ้าค่า input ไส่ไม่ได้(เพราะเป็นทุกค่า) และจะรู้ input ก็ต่อเมื่อวัด แสดงว่าการวัดแต่ละครั้งก็คือการสุ่มดีๆนี่เองจนกว่าจะเจอค่าที่ไช่ แสดงว่าอาจจะเจอผลของสถาณะ 00 ซักร้อยครั้งก็เป็นได้ไช่รึเปล่า แล้ว ขั้น 3 ที่คำนวนแล้ว ขั้น 4 นี่มันเอาค่าที่คำนวนไปทำยังไง กับ input ที่เป็นทุกๆค่า ถึงสามารถเพิ่มความน่าจะเป็นของผลลัพได้ จาก 00 01 10 11 เป็นค่าอะไรหรือ ช่วยไขข้อกระจ่างที
ข้อแรก: ใช่ครับ เป็นไปได้เหมือนกันที่วัดแล้วจะไม่ได้ผลตามต้องการ หลักการสำคัญที่สุดของอัลกอริทึมคือทำยังไงก็ได้ให้มีโอกาสวัดคิวบิตแล้วได้คำตอบที่ต้องการมากที่สุด
ข้อที่สอง: ใช้ linear algebra ครับ คิวบิตในทางคณิตศาสตร์จะเขียนด้วยเมตริกซ์หรือเวกเตอร์ โดยเอาค่ารากที่สองของความน่าจะเป็นแต่ละอันมาเขียน (จริงๆ ค่า ai ที่เป็น amplitude ของสถานะมันคือค่ารากที่สองของความน่าจะเป็นอีกทีครับ แต่ผมคิดว่าถ้าเขียนให้เป๊ะคนจะงงกว่าเดิม) เวลาคิวบิตผ่านขั้นตอนที่ 3 กับ 4 มันคือเอาเมตริกซ์ที่เซตขึ้นในขั้นตอนนั้นมาคูณกับเมตริกซ์ของคิวบิตครับ
ถ้ามันใช้งานได้สมบูรณ์ มันจะแก้ปัญหา p-np problem ได้ด้วยป่าวเนี่ย
ทุกวันนี้ทำงานกับ np complete .....นั่งลุ้นทุกวันว่ามันจะรันเสร็จไหม
สำหรับคอมพิวเตอร์ควอนตัม เค้ามีคลาส BQP ครับ ครอบคลุมคลาส P ทั้งหมด และคาดกันว่าจะครอบคลุมคลาส NP และ PSPACE บางส่วน แต่ไม่ครอบคลุม NP-complete
ตัวอย่างปัญหาที่เป็น BQP และคาดกันว่าจะไม่เป็น P ก็เช่น integer factorization หรือก็คือปัญหาแยกตัวประกอบนั่นแหละครับ
เรื่องของเรื่องคือ ตอนนี้นักวิทยาศาสตร์ยังไม่รู้ความสัมพันธ์ระหว่างคลาส BQP กับ NP แต่อันนึงที่เค้าเล็งๆ กันไว้คือปัญหา integer factorization (ตอนนี้ยังเก็งกันอยู่ว่าเป็น NP-intermediate คืออยู่ในคลาส NP แต่ไม่อยู่ในคลาส P และ NP-complete) ถ้ามีคนพิสูจน์ได้ว่าเป็นคลาส P คอมพิวเตอร์ควอนตัมก็มีแววจบเห่เลย แต่ถ้าเป็น NP-complete คอมพิวเตอร์ควอนตัมก็จะยิ่งเนื้อหอมมากขึ้นครับ
ใช่ครับ อ่านในบทความ แล้วลองมานั่งคิดเรื่องงานที่ทำอยู่
quantum comp เข้ามาช่วยให้สิ่งที่ทำอยู่ตอนนี้ลดเวลาได้ได้เยอะแน่นอน
อย่างน้อยๆก็น่าจะลดเวลาจากที่เคย run program ทิ้งไว้ข้ามคือเหลือไม่กี่นาทีได้แน่นอน
คงมี สาขาวิทยาการควอนตัมคอมพิวเตอร์ แน่ๆ
ชอบบทความนี้ครับ อ่านสนุกดี
อ่านได้ลื่นดีครับ
เป็นบทความที่น่าสนใจมาก แม้สำหรับตัวผมยังไม่เข้าใจทุกอย่างในตอนนี้ อย่างน้อยก็รู้มากขึ้นแล้วครับ
ขอบคุณครับ น่าสนใจมาก โปรดเขียนอีกๆ
GGWW
จะมีโอกาศมาได้ใช้ตามบ้านเปล่านะ เห็นต้องหล่อเย็นซะขนาดนั้น
กว่าจะถึงวันนั้นคง on cloud กันหมดแล้วมั้งครับ
ถ้าเรายังลด Latency ที่ส่งข้อมูลไปมาในระยะไกลๆ ไม่ได้ ผมทุกอย่างคงไม่อยู่บน Cloud อะครับ บางอย่างก็ต้องการที่ตอบสนองเร็วๆ
ฟิสิกส์ควอนตัม เอามาสำหรับหาคำตอบ เดียวกับ Atom ที่มีรูปแบบผิดธรรมชาติของอ Atom ที่สามารถทำหลายๆอย่างได้เหนือธรรมชาติ ถ้าเราเข้าใจ โลกของ Atom และรู้วิธีการเกิดขึ้นสัก 50% มนุษย์ก็จะพัฒนาไปไกลกว่านี้เป็น 100เท่า quantum computing ตอนนี้ผมว่ายังอยู่ในช่วงคล่ำผิดคล่ำถูกอยู่เพราะมนุษย์ยังอธิบายพื้นฐานของ Atom ได้ไม่ถึง 10% ทำให้การนำ superposition ของคิวบิต มาใช้ยังอยู่ในระดับขาดคะเนและมีโอกาศ lost ตลอดเวลา ซึ่งไม่ใช้อัตราที่แม่นยำระดับ100% แต่ด้วยความเร็วในการทำงานทำให้ผลลัพธ์ในค่า lost อยู่ในระดับที่ต่ำ
10% นี่เทียบกับอะไรครับ
ความเข้าใจที่มีต่อ atom ครับ เทียบกับอาการต่างๆที่ยังไม่สามารถอธิบายได้ในตัว Atom ครับ ผมดูจาก discovry มาอีกทีนึกเกี่ยวกับเรื่อง ฟิสิกส์ควอนตัม โดยเฉพาะนะครับ
ไม่แน่ใจคนแปลเข้าใจหรือเปล่า แต่บทความอ่านยากมาก มีส่วนที่ไม่จัดเจนเยอะมากครับ
If you can't explain it simply, you don't understand it well enough.
เขียนบทความที่ดีกว่าเข้ามาได้เลยครับ ที่นี่อยากได้ต้องทำเองครับ
ผมยอมรับนะว่ายังไม่จัดเจน คือผมไม่เก่งเรื่องฟิสิกส์ควอนตัม (ตอนเขียนพยายามเลี่ยงเนื้อหาฟิสิกส์ให้มากที่สุด) ส่วนคอมพิวเตอร์ควอนตัมก็อาศัยว่าเคยเรียนคลาสนึงกับอาจารย์ บวกกับศึกษาเพิ่มเติมตามความสนใจฮะ (กำลังหาทางเรียนต่ออยู่)
ส่วนบทความนี้ ผมคิดว่าอธิบายให้ง่ายสุดได้แค่นี้แล้วหล่ะ เลยเอามาลงเพื่อดูฟีดแบคเพิ่มเติม และเผื่อมีคนอธิบายได้ดีกว่าก็เอามาแชร์ในคอมเมนต์ หรือจะเขียนเป็นบทความก็ได้ไม่ซีเรียสอะไร (จะได้ดูแนวทางการเขียนของคนนั้นเพิ่มด้วย)
น้อมรับคำติชมครับ
https://www.youtube.com/watch?v=62bKrvQBOwA
https://www.youtube.com/watch?v=CBrsWPCp_rs
Quantum Theory กับ Quantum Physics ถ้าเราเข้าใจทั้งหมด โลกจะพัฒนามากกว่าคำว่า Quantum Comuter
โอ๊ะ ขอบคุณครับ
ชอบๆสนุกดี เหมือนจะสนุกกว่าดูหนังแนวนี้อีก
เช้าใจว่าแบบนี้ คอมทั่วไปที่ใช้ๆกันอยู่ใช้ 0 กับ 1 คือ ไฟติด ไฟดับ
แต่ควอนต้ม มี 0 กับ 1 เหมือนกันและออกมาพร้อมกันด้วย
ไม่ได้หมายความว่า 00 11 01 10 จะแยกออกเป็นไฟติดไฟดับได้
คือบอกไม่ได้ว่า มันเป็นสถานนะไหน ต้องผ่าน measurement ถึงจะบอกได้ว่า เป็นไฟติด หรือ ไฟดับ
มากกว่านี้ งงละ ...
จากที่ผมอ่านคร่าวๆ (ยังไม่ได้อ่านจริงจัง จะอ่านแบบอ่านหมดโดยไม่มีเวลาก็รู้สึกไม่ใช่) ผมเข้าใจว่าวิธีทำงานของมันคือการทำให้ค่าไหลไปหาค่าที่ถูกต้องให้ได้ก่อนที่จะวัดค่าออกมาใช่ไหมครับ?
ใช่ครับ
ขอบคุณมากครับ ผมสงสัยมานานมากแล้ว ถามใครใครก็บอกแค่ว่าคิวบิตมันเป็น 0 กับ 1 ได้พร้อมกัน มันเลยทำงานได้เร็ว ผมก็ไม่เข้าใจสักทีว่าแล้วมันยังไงต่อ
ขอบคุณมากๆ ครับ
อ่านจนจบ แล้วเข้าสู่สถานะ Superposition ทันที
ซ้ำครับ
เพิ่งอ่านได้หนึ่งบรรทัดค่ะ