By: lew 


 on 7 July 2018 - 03:52
Tags:
on 7 July 2018 - 03:52
Tags:
Topics:

ทีมวิจัยจาก MIT สร้างโมเดล deep learning ที่ชื่อว่า PixelPlayer ที่สามารถแยกเสียงเครื่องดนตรีในเพลงออกมาทีละชิ้น เปิดทางให้เราสามารถปรับปรุงคุณภาพเพลงเก่าๆ ที่มิกซ์เสียงมาแล้วได้
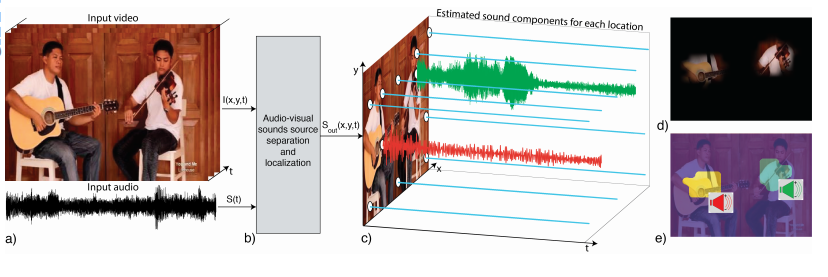
PixelPlayer เป็นโมเดลที่ฝึกด้วยวิดีโอดนตรีนาน 60 ชั่วโมง ความพิเศษของโมเดลนี้คือมันดูภาพของเครื่อดนตรีไปด้วย และเมื่อมองพื้นที่ในภาพก็สามารถแยกเสียงที่เกี่ยวข้องในพื้นที่ตรงนั้นออกมาได้ ชุดข้อมูลที่ใช้ฝึกนั้นเรียกว่าชุดข้อมูล MUSIC (Multimodal Sources of Instrument Combinations) เป็นวิดีโอการโคฟเวอร์เพลง 714 รายการ โดยใช้เครื่องดนตรีชิ้นเดียวหรือคู่ (duet) ปรับอัตรา sampling เหลือ 11 kHz แล้วแปลงเป็นภาพ Time-Frequency ขนาด 256 x 256 เพื่อใช้ป้อนเข้าโมเดล deep learning ส่วนภาพวิดีโอปรับขนาดเหลือ 224 x 224 เพื่อป้อนเข้าโมเดลที่ดัดแปลงจาก ResNet-18
กระบวนการฝึกอาศัยการจับคู่วิดีโออย่างสุ่ม รวมถึงจับคู่วิดีโอกับความเงียบ (ใช้ภาพธรรมชาติแทนภาพวิดีโอ) ทำให้ได้วิดีโอที่มีเสียงเครื่องดนตรี 0-4 ชิ้น แล้วฝึกการแยกเสียงออกมาให้ตรงกับวิดีโอต้นฉบับ
แนวทางการเปิดให้โมเดล deep learning สามารถมองเห็นภาพเครื่องดนตรีเพื่อช่วยให้การแยกเสียงทำได้ดีขึ้นอาจเป็นแนวทางสำหรับการพัฒนาคอมพิวเตอร์เรียนรู้ได้ในอนาคต ที่คอมพิวเตอร์ไม่ต้องจำกัดตัวเองกับอินพุตเฉพาะทางเช่นเดิมอีกต่อไป แต่สามารถเรียนรู้และทำนายผลจากอินพุตที่หลากหลาย ในอนาคตคอมพิวเตอร์เมื่อเห็นวิดีโอก็อาจจะเข้าใจได้ทันทีว่าเสียงใดมาจากรถหรือสัตว์ตัวใดในภาพ
งานวิจัย The Sound of Pixels เตรียมนำเสนอในงาน European Conference on Computer Vision (ECCV) เดือนกันยายนนี้
ที่มา - MIT

Get latest news from Blognone
Follow @twitterapi



Comments
เครื่อดนตรี => เครื่องดนตรี
ถ้าเอามันมาฟังเมทัลคอร์ มันจะแยกเสียงได้ไหม
ถือเป็นจุดเริ่มต้นที่ดีครับ สุดยอดไปเลย :)