By: lew 


 on 23 March 2019 - 10:50
Tags:
on 23 March 2019 - 10:50
Tags:

สองปีก่อนกูเกิลเคยเสนองานวิจัย AutoML ที่สามารถ "ออกแบบ" โมเดล deep learning สำหรับงานเฉพาะทางได้โดยไม่ต้องอาศัยนักวิจัยมานั่งปรับโมเดล แต่ระบบเหล่านี้มักใช้พลังประมวลผลสูงมาก จนคนทั่วไปไม่สามารถลงทุนได้ ล่าสุดทีมวิจัยจาก MIT เสนอแนวทางใหม่ที่สร้างระบบออกแบบโมเดลโดยใช้พลังประมวลผลระดับเดียวกับการฝึกโมเดล deep learning ไม่ได้ต่างกันเป็นร้อยเท่าพันเท่าเหมือนแต่ก่อน
ระบบ neural architecture search (NAS) ที่ใช้ระบบอัตโนมัติออกแบบสถาปัตยกรรม deep learning แต่ระบบนี้อาศัยการปรับปรุงโมเดลไปเรื่อยๆ และฝึกโมเดลใหม่ทุกครั้ง ทำให้กินระยะเวลาประมวลผลสูงมาก
ProxylessNAS งานวิจัยใหม่นี้อาศัยการฝึกโมเดลที่มีจำนวนพารามิเตอร์มากเกินไป จากนั้นจึงดูว่าส่วนไหนของโมเดลไม่จำเป็น และตัดออก (path-level pruning) ทำให้กระบวนการฝึกโมเดลทำได้จบในการฝึกโมเดลเดียว
งานวิจัยก่อนหน้านี้เช่น AutoML ต้องการเวลาจีพียูประมาณ 48,000 ชั่วโมงเพื่อสร้างโมเดลจำแนกหมวดหมู่ภาพตามชุดข้อมูล CIFAR-10 ขณะที่ ProxylessNAS ต้องการเวลาเพียง 200 ชั่วโมงเท่านั้น การสร้างเทคนิคที่ใช้พลังประมวลผลต่ำเช่นนี้ทำให้คนทั่วไปที่มีการ์ดกราฟิกเพียงไม่กี่ใบสามารถใช้ระบบอัตโนมัติในการออกแบบโมเดลได้
ที่มา - MIT News, Open Review
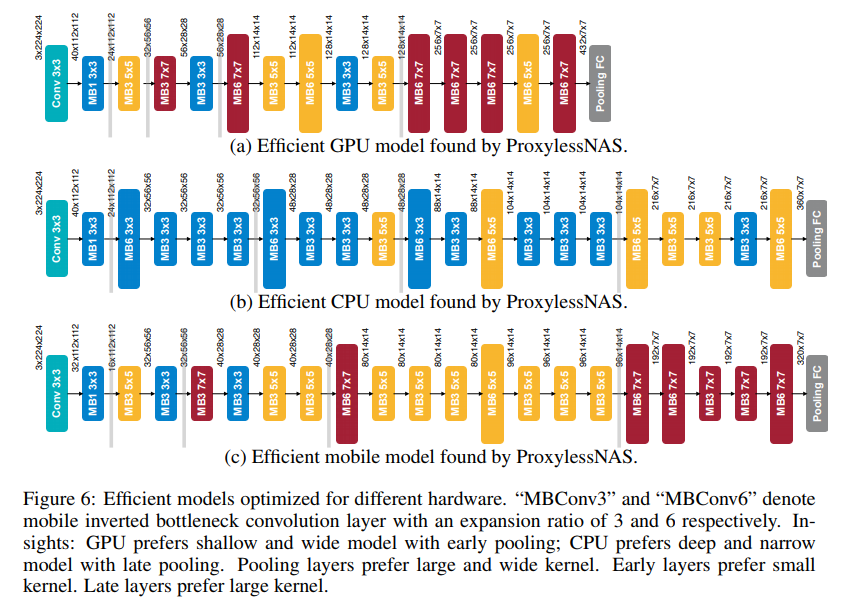
ภาพโมเดลการจำแนกภาพจากชุดข้อมูล CIFAR-10 โดย ProxylessNAS เมื่อให้ออกแบบโดยเน้นการใช้งานบนฮาร์ดแวร์ที่ต่างกันออกไป ก็จะได้ผลที่ต่างกันด้วย

Get latest news from Blognone
Follow @twitterapi



Comments
ยังไม่ทันได้เริ่มงาน ก็ตกงานซะแล้วเรา
“ProxylessNAS เมื่อให้ออกแบบโดยเน้นการใช้งานบนฮาร์ดแวร์ที่ต่างกันออกไป ก็จะได้ผลที่ต่างกันด้วย”
ก็เป็นวรีตกงานไปก่อนละกันนะ 55+
มือใหม่!! ใหม่จริงๆนะ
โมเด => โมเดล
เร็วขึ้นเยอะเลย
วงการนี้โหดขึ้นทุกวัน ?
ผมว่าเดี๋ยวคงมีประมวลผลภาพ แล้วสร้างโมเดลเพื่อหาผลลัพธ์ได้เองโดยไม่ต้องใช้นักวิจัย หรือไม่ก็เชื่อมกับโมเดลอื่นอัตโนมัติเมื่อเจอ Knowledge ที่ตรงกับที่ต้องการ แล้วเชื่อมกับโมเดลที่มีอยู่แล่วเพื่อสร้าง Knowledge ใหม่ จากต่างผู้ผลิตได้
ผมว่าสายงาน AI/ML และ Big Data ยังไปได้อีกไกลนะครับ
เราสามารถสร้างโมเดลปัญญาประดิษฐ์ที่ออกแบบโมเดลและจูนพารามิเตอร์ด้วยตัวเองได้ แต่อย่าลืมว่า มันไม่เข้าใจปัญหาจริงๆนะครับ กว่าจะสร้างโมเดลขึ้นมาได้ตัวนึง ต้องนั่งวิเคราะห์ว่าปัญหาแบบนี้ต้องใช้ข้อมูลอะไรบ้าง ประสานงานเพื่อเก็บข้อมูล ออกแบบระบบเก็บข้อมูล (Hadoop HDFS, MongoDB, PostgreSQL, บลาๆๆ) แล้วทำความสะอาดข้อมูล จัดการข้อมูลเสียๆ และทำเรื่อง features engineering เช่น one hot encoding, dummy encoding, เอาข้อมูลคอลัมน์นี้มาผสานกับคอลัมน์นี้เพื่อเตรียมเข้าโมเดล, บลาๆๆ จากนั้นก็มานั่งเลือกอัลกอริทึมที่เหมาะกับงานพร้อมจูนพารามิเตอร์ แล้วก็ทดสอบอัลกอริทึมอื่นๆว่าอันไหนได้ผลลัพธ์ดีที่สุด ถ้าผลลัพธ์ยังไม่น่าพอใจ ก็กลับไปเริ่มใหม่ว่าจะใช้ข้อมูลอะไรอีกบ้าง พอได้โมเดลที่สมบูรณ์ก็ต้องไปอธิบายกับฝั่ง Business ว่าโมเดลมันทำงานยังไงอีก
ในความรู้สึกของผมคือ มันมาช่วยเราทำงานมากกว่านะครับ เพราะเรื่องการออกแบบโมเดลและจูนพารามิเตอร์เป็นแค่งานส่วนหนึ่งเท่านั้นเอง...
นอกเหนือจากการออกแบบโมเดลและจูนพารามิเตอร์ เรายังต้องการคนที่เข้าใจปัญหาและรู้ว่าต้องใช้ข้อมูลอะไรบ้าง เก็บข้อมูลยังไงไม่ให้ระบบช้า แปลงข้อมูลก่อนเข้าโมเดลยังไง ประเมิณผลลัพท์ว่าแก้ปัญหาได้ตรงจุดหรือเปล่า (ROC, Precision, Recall, FalsePositiveRate นู่นนี่นั่น) เพราะข้อมูลสำหรับการเทรนโมเดลสำคัญมากๆ เหมือน Garbage in Garbage out อย่างงั้นอ่ะครับ
และเราต้องการคนที่ออกแบบระบบสำหรับ Big Data ให้เก็บข้อมูลทั้งแบบ Semi-Structured/Unstructured Data และสามารถทำ Data Analysis / Data Processing แล้วไม่กระทบกับ Performance ของแอพพลิเคชั่นหลักด้วยหรือเปล่าครับ
แล้วระบบที่รองรับ Big Data จะต้องรองรับการข้อมูลที่ผ่านเข้าแอพพลิเคชั่นจำนวนมหาศาล เรายังต้องการคนที่เปลี่ยนระบบ Legacy เก่าๆให้เป็น Microservices เช่นพวก Kubernetes หรือเปล่าครับ
จริงๆมันมีรายละเอียดมากเลยนะครับ น่าจะทำให้เกิดการจ้างงานสูงขึ้นด้วยซ้ำนะเนี่ย
ถูกผิดยังไงขออภัยล่วงหน้าครับผม
บริษัทผมเพิ่งผ่านงบประมาณ ยังไม่ได้เริ่มทำเลย จะตกงานแล้วเหรอเนี่ย
ตอนนี้มี apply กับ model / product / service ตัวไหน , อยู่บ้างนะ