By: tontan 


 on 10 April 2021 - 18:47
Tags:
on 10 April 2021 - 18:47
Tags:

เทคโนโลยีการรู้จำเสียง (Speech Recognition) เป็นเทคโนโลยีที่ช่วยให้เราสื่อสารหรือสั่งงานกับคอมพิวเตอร์ได้ง่ายขึ้น ซึ่งระบบดังกล่าวเป็นที่นิยมกันอย่างเผยแพร่ ตัวอย่างเช่น ใช้งานในระบบผู้ช่วยอัจฉริยะ, ใช้สร้างคำบรรยายในวิดีโอ และใช้พิมพ์ข้อความตามเสียง เป็นต้น อย่างไรก็ตามเทคโนโลยีการรู้จำเสียงทุกภาษาต้องการชุดข้อมูลเสียงขนาดใหญ่สำหรับมาทำเทคโนโลยีดังกล่าว ยิ่งมีข้อมูลมากเท่าไร ความแม่นยำยิ่งสูงขึ้น แต่ชุดข้อมูลเสียงขนาดใหญ่จำนวนมากที่ถูกสร้างโดยบริษัทใหญ่ ๆ เราไม่สามารถใช้งานได้ เนื่องจากราคาที่แพงหรือติดลิขสิทธิ์ จึงทำให้บริษัทเล็ก ๆ หรือนักพัฒนาไม่สามารถเข้าถึงชุดข้อมูลดังกล่าวได้
Mozilla ในฐานะองค์กรที่ไม่หวังผลกำไรจึงได้ทำโครงการ Common Voice ขึ้นมา เพื่อสร้างชุดข้อมูลเสียงสำหรับสร้างเทคโนโลยีการรู้จำเสียง ให้ทุกคนสามารถร่วมบริจาคเสียง ตรวจสอบเสียง และเพิ่มประโยคเข้าไปในระบบได้ โดยชุดข้อมูลเป็นสาธารณะประโยชน์ที่ทุกคนบนโลกสามารถใช้งานได้ นอกจากนั้น Mozilla ยังสร้างเครื่องมือสำหรับเทคโนโลยีการรู้จำเสียง ชื่อว่า Deep Speech
สำหรับภาษาไทย ทาง Mozilla ได้เปิดรับบริจาคเสียงตั้งแต่ปีที่ผ่านมา ปัจจุบันมีจำนวน 17 ชั่วโมง และชั่วโมงที่ตรวจสอบแล้ว 12 ชั่วโมง โดยเป้าหมายคือ 10,000 ชั่วโมง เพื่อให้ได้ชุดข้อมูลเสียงที่นำไปใช้งานกับเทคโนโลยีการรู้จำเสียงได้จริง
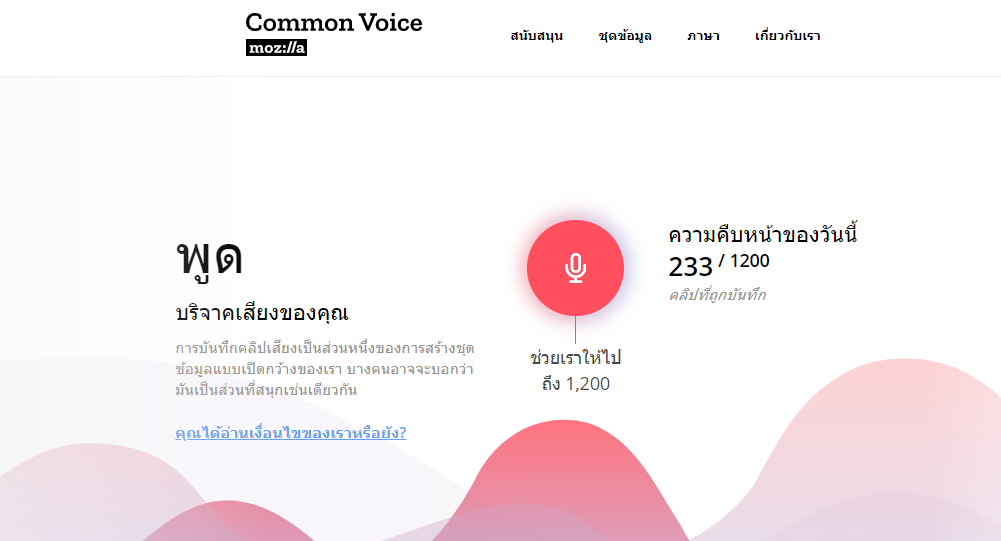
ร่วมบริจาค/ตรวจสอบเสียงภาษาไทยอย่างไร?
เข้าไปที่ commonvoice.mozilla.org/th โดยไม่จำเป็นต้อง Login (แต่ Login ได้เพื่อให้ข้อมูลพวกอายุหรือเพศและจัดอันดับผู้บริจาค) จากนั้นคลิกที่รูปไมค์ เพื่อบริจาคเสียง โดยกดปุ่มไมค์เพื่อบริจาคเสียง แล้วกดหยุด จากนั้นคลิกส่ง ทำจนครบแล้วส่งเสียงได้ โดยพยายามพูดให้ครบตามที่ประโยคกำหนด ไม่ขาดหรือเกิน
หากพบประโยคที่มี "ๆ", ภาษาอังกฤษ หรือ ตัวเลข ปนมา อย่าลืมกดปุ่ม รายงาน
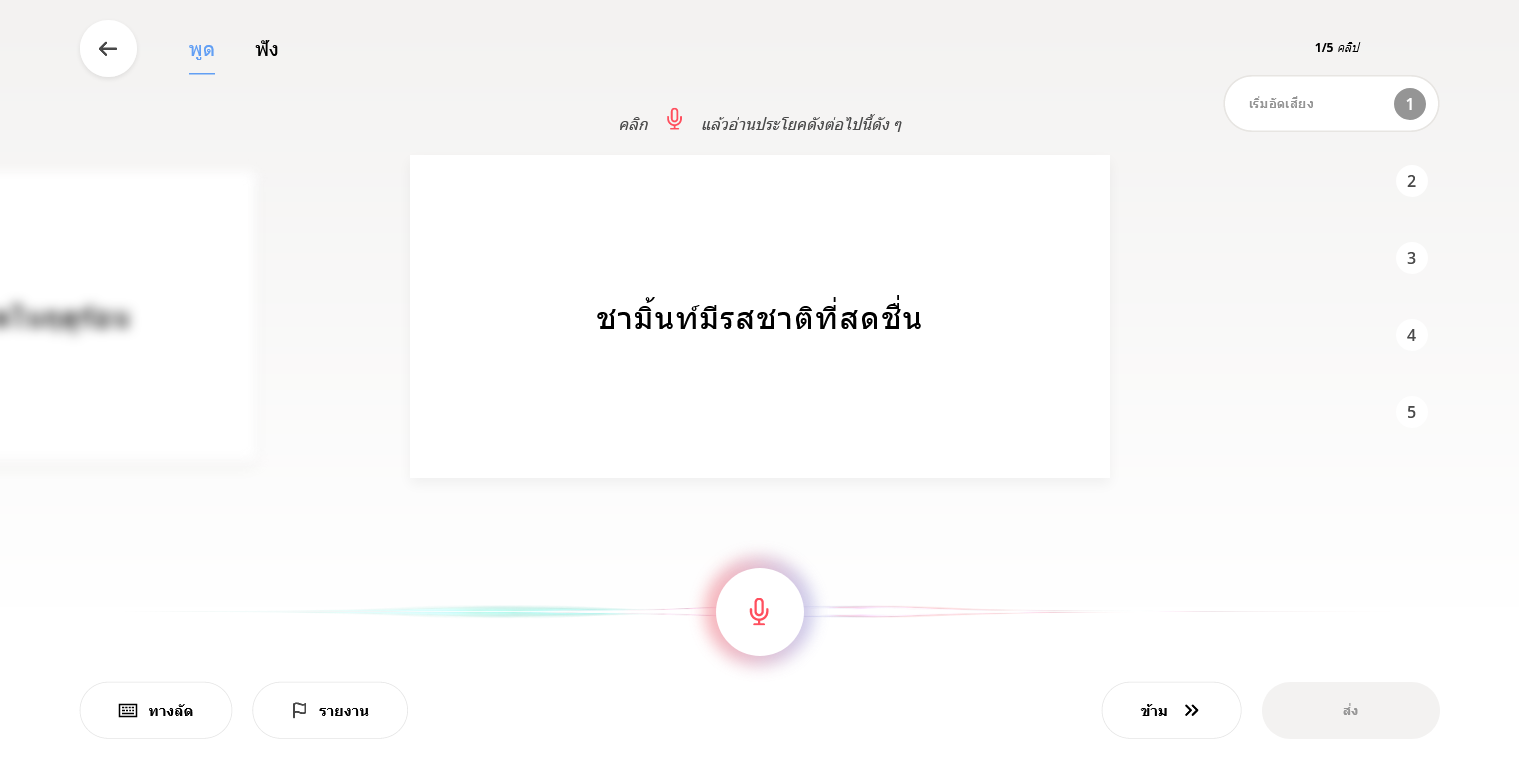
หรือ คลิกปุ่ม > เพื่อตรวจสอบเสียงโดยการฟัง จากนั้นกดปุ่ม > เพื่อฟัง ฟังจบแล้วกด ใช่ หรือ ไม่ ทำจนครบแล้วส่งได้เลย
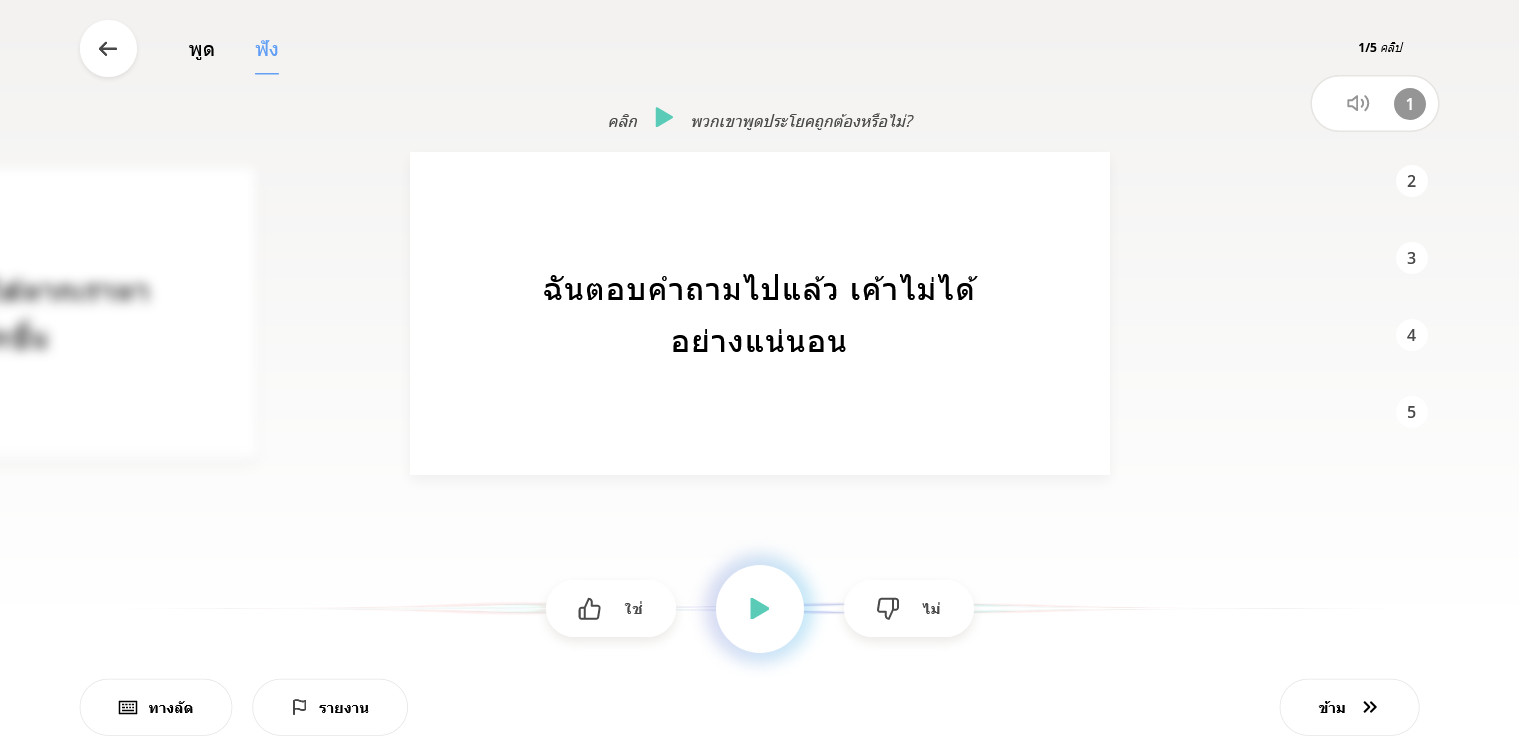
สำหรับเกณฑ์ในการฟัง ง่าย ๆ คือ เสียงพูดครบตามที่ประโยคกำหนด ฟังรู้เรื่อง
เพิ่ม/ตรวจสอบประโยคก่อนนำไปรับบริจาค
ต่อมาเป็นส่วนในการเพิ่ม/ตรวจสอบประโยคก่อนนำประโยคไปรับบริจาคเสียง โดยเข้าไปที่ commonvoice.mozilla.org/sentence-collector ให้ Login จากนั้นไป Profile เลือก Thai แล้วไปที่ REVIEW กด ?ถูกใจ สำหรับประโยคที่ถูกตามเกณฑ์ หรือ ?ไม่ถูกใจ สำหรับประโยคที่ไม่ถูกต้องตามเกณฑ์
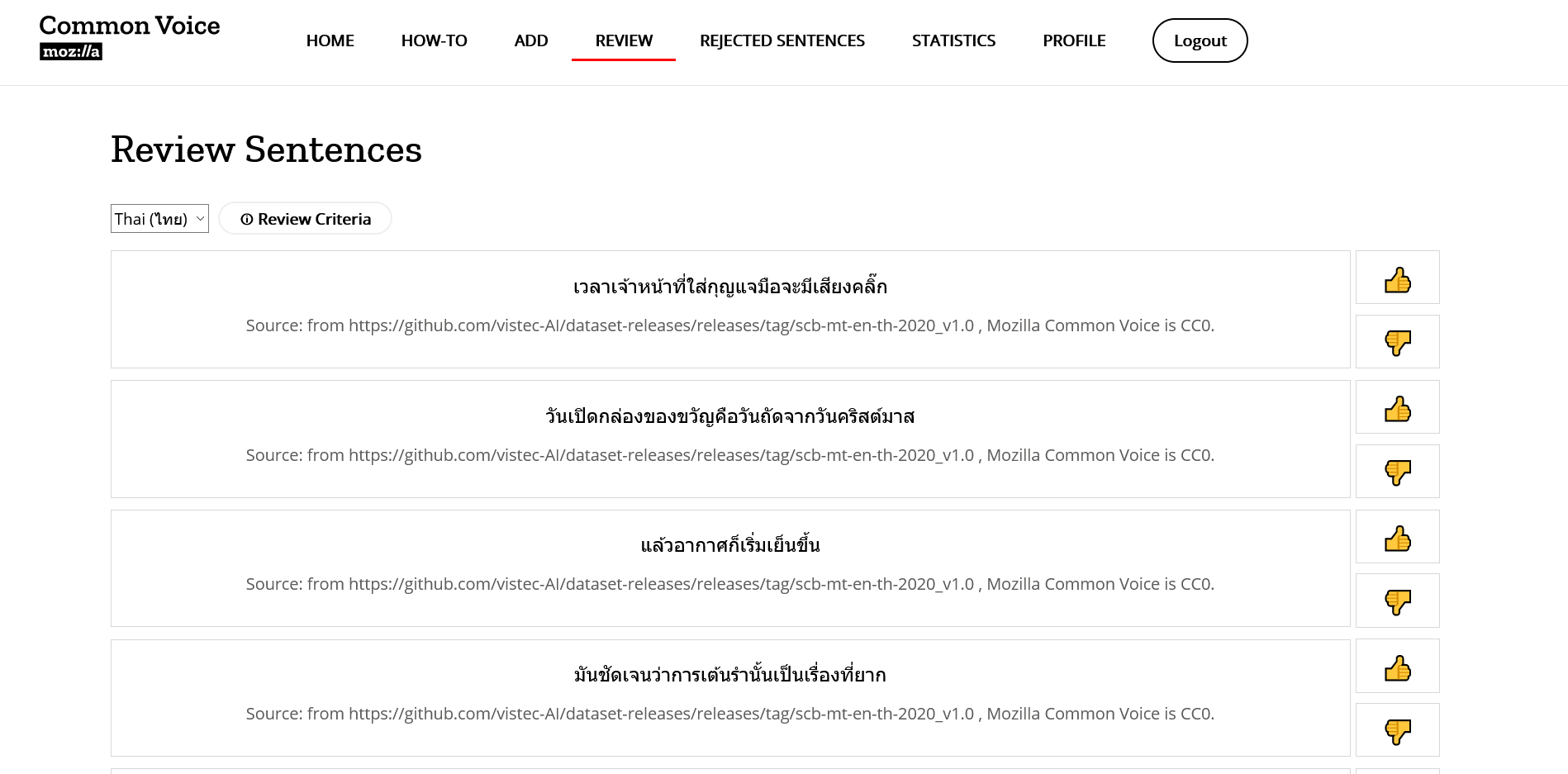
สำหรับเกณฑ์ประโยคมีดังนี้
- ไม่เอาประโยคที่มีการสะกดผิด
- ไม่เอาประโยคผิดไวยากรณ์ ประโยคขาด ไม่สมบูรณ์ มีคำขาด ๆ เกิน ๆ หรือคำแปลกที่คนไทยไม่พูดกัน อ่านแล้วงง
- ประโยคต้องอ่านได้ภายใน 10 วินาที (ประมาณ 100 ตัวอักษร)
- ไม่เอาตัวย่อ เช่น สศช. กทม.
- ไม่เอา ๆ / ฯลฯ/ ฯ / ()
- ตัวเลขต้องเป็นคำอ่านเท่านั้น เช่น สองพันห้าร้อยหกสิบสาม
- ไม่เอาประโยคที่มีภาษาอังกฤษ
ที่มา: งานที่พวกเรามาช่วยกันรีวิวประโยค Mozilla Common Voice
สำหรับการเพิ่มประโยค กดไปที่ ADD แล้วพิมพ์ประโยคเข้าไป โดยประโยคดังกล่าวต้องเป็นสาธารณะประโยชน์
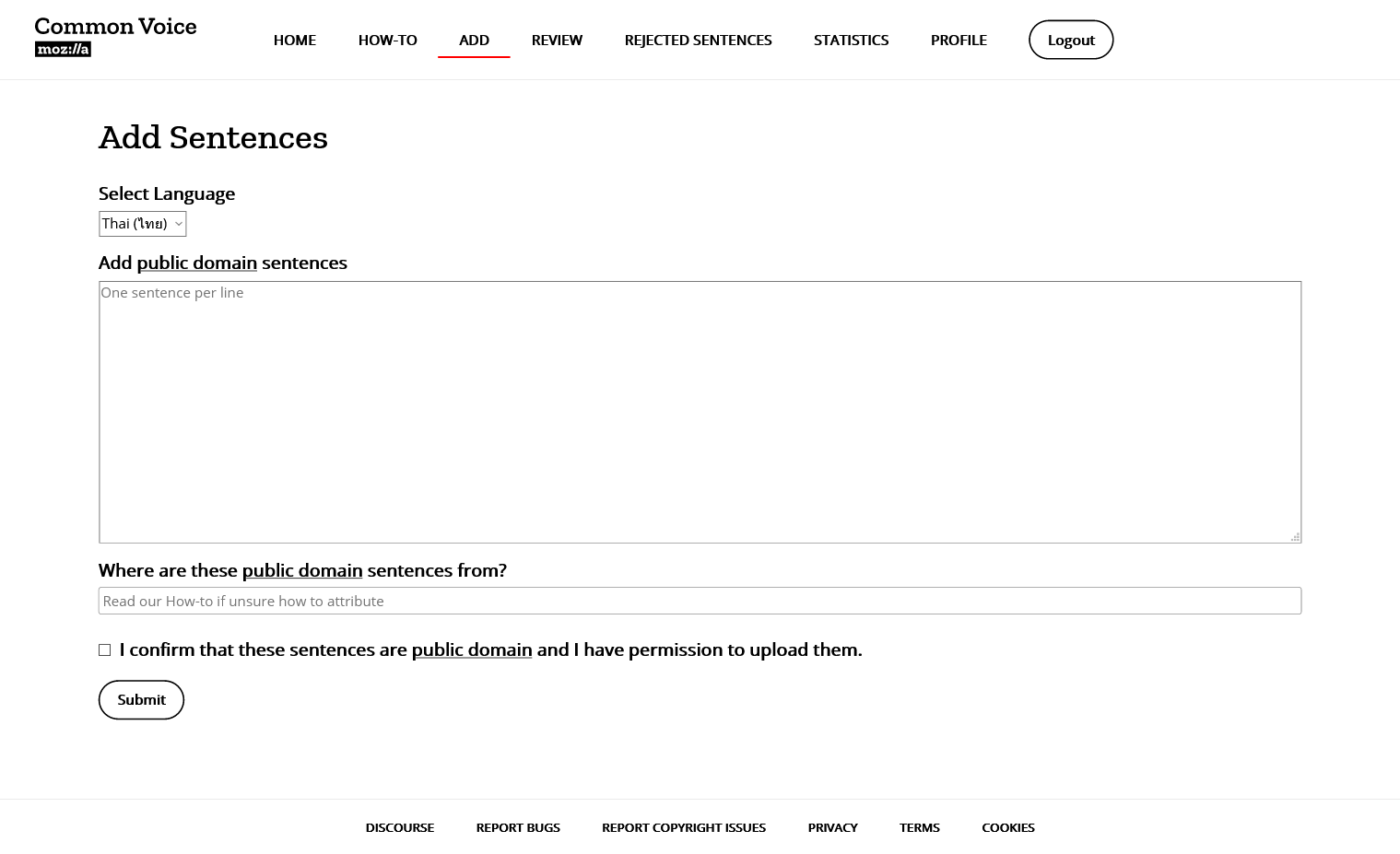
ผมขอเชิญชวนชาว Blognone มาร่วมกันบริจาคเสียงพูดภาษาไทยให้กับทาง Mozilla Common Voice กันครับ
หากมีข้อสงสัย สามารถเข้าไปอ่านได้ที่ commonvoice.mozilla.org/th/faq และสามารถเข้าไปอ่านเอกสาร ? ? Mozilla Voice Community Playbook V1.1 สำหรับข้อมูลเพิ่มเติม

Get latest news from Blognone
Follow @twitterapi



Cloudnone
- AWS มาไทย ย้ายเลยดีไหม อะไรยังมาไม่ครบบ้าง? | Cloudnone Ep. 23
- NVIDIA จะไปหยุดที่ตรงไหน ทำไมครองโลกดาต้าเซ็นเตอร์ | Cloudnone EP.22
- ถึงคลาวด์เคราะห์: ทำอย่างไรเมื่อบริการคลาวด์ที่ใช้ถูกยกเลิก | Cloudnone EP. 21
- รู้จักอาชีพ Site Reliability Engineer สำคัญยังไง? | Cloudnone EP. 20
- อธิบาย CrowdStrike ทางเทคนิค ทำไมถึงทำพีซีจอฟ้าเป็นล้านๆ เครื่อง | Cloudnone EP.19
Comments
น่าสนใจ เด่วว่างๆ คงเข้าไปร่วมด้วยช่วยกันครับ :)
มือใหม่!! ใหม่จริงๆนะ
เข้าไปดูประโยคที่ให้ตรวจแล้ว เกินเก้าสิบเปอร์เซ็นต์ผิด
+1
เข้าไปช่วยมาแล้วครับ
มีสปีคเกอร์ผู้หญิงคนนึงเสียงมีสเน่ห์มาก และอ่านประโยคที่เหมือนมาจากนิยายต่าง ๆได้อย่างมีอรรถรส
ถ้าเป็นคนพูดหนังสือเสียง นิยายในภาษาไทยจะต้องน่าฟังมากขึ้นเยอะเลย
ตกหลุมรักเสียงเข้าแล้วล่ะ
จริง เจอบางคนเหมือนกัน เสียงหวานมาก เขินนเลย
ใช้ firefox ฟรีมาตั้งนาน ได้เวลาตอบแทนแล้วสินะ
ไม่ใช้ firefox แต่จะเข้าไปช่วยครับ
หากพบประโยคที่มี "ๆ", ภาษาอังกฤษ หรือ ตัวเลข ปนมา อย่าลืมกดปุ่ม รายงาน
มีเยอะมาก น่าจะเกือบ 40% สะกดผิดก็มี ทำไปทำมา กลายเป็นภาษาอังกฤษล้วนก็มีครับ
ใช่ครับ ส่วนตัวผม มองว่ากรณีตัว ๆ ที่หลุดไปในชุดข้อมูลแล้วก่อนหน้ายังสามารถทำความสะอาดได้อยู่ครับ เพราะ "ๆ" เป็นการพูดซ้ำคำก่อนหน้าครับ
บล็อก: wannaphong.com และ Python 3
เครื่องหมายที่ไม่จำเป็นต้องอ่าน เช่น ? ! , ถือว่าผ่านไหมครับ
ผ่านครับ
บล็อก: wannaphong.com และ Python 3
เดี๋ยวจะเข้าไปช่วยเช็คครับผม
..: เรื่อยไป
สนุกดีแฮะ กะเข้าไปทำขำ ๆ ทำไปทำมาล่อไปเกือบสองร้อยอัน ๕๕๕๕
เทคโนโลยีไม่ผิด คนใช้มันในทางที่ผิดนั่นแหละที่ผิด!?!
ถามได้ไหมครับ ทำไมห้ามมีตัว ๆ นี้ครับ
เจอบ่อยมาก
เพราะเวลาเอาไปใช้งาน train asr ต้องทำความสะอาดข้อความให้มีข้อความตามเสียงทั้งหมดครับ รวมถึงต้องเปลี่ยนจาก ๆ เป็นการซ้ำคำข้างหน้า ซึ่งอาจจะสร้างความลำบากให้คนทำโมเดลและคนต่างชาติที่อาจจะไม่เข้าใจภาษาไทย แต่ต้องเอาชุดข้อมูลไปใช้งานครับ
บล็อก: wannaphong.com และ Python 3
อ่อ แบบนี้นี่เอง รับทราบครับ ผมเผลอกดถูกใจไปหลายประโยคเลย
เดียวแก้ตัวใหม่
วันนี้ว่างจัด เลยนั่งบริจาคเสียง เกือบ 200 กว่าประโยค จนรู้สึกว่า เจ็บคอนิด ๆ
ฮ่าๆ
ๆ เป็นเพราะคนอาจอ่านไม่เหมือนกันครับ
ไฟไหม้ๆ
- ไฟไหม้ไหม้
- ไฟไหม้ไฟไหม้
ฯ กับตัวย่อ เพราะไม่รู้ว่าคนจะอ่านแค่ที่ย่อมา หรือจะอ่านคำเต็ม (หรือจะรู้คำเต็มไหม)
กรุงเทพฯ
- กรุงเทพ
- กรุงเทพหานคร
กต.
- กอตอ
- กอตอจุด
- กด
- กระทรวงการต่างประเทศ
- กระทรวงต่างประเทศ
( ) เพราะแต่ละวิธีอ่านไม่เหมือนนกันเช่นกัน
จำกัด (มหาชน)
- จำกัด มหาชน
- จำกัด ในวงเล็บ มหาชน
- จำกัด วงเล็บเปิด มหาชน วงเล็บปิด
ตัวเลข
404
- สี่ศูนย์สี่
- สี่ร้อยสี่
อะไรก็ตามที่กำกวมหรือมีโอกาสอ่านแตกต่างกัน จะเอาออกให้หมดครับ เพื่อกันความสับสน
มีเกณฑ์อยู่ตามนี้ครับ https://commonvoice.mozilla.org/sentence-collector/#/how-to
พวกไม้ยมก วงเล็บ กับภาษาอังกฤษ ในตอนหลังมีสคริปต์ที่กรองข้อมูลออกไปให้แล้ว ที่พบอยู่ตอนนี้เป็นข้อมูลในช่วงแรกๆ ที่ยังค้างอยู่ในระบบ อาจจะรบกวนช่วยกันเอาออกไปก่อนครับ ทั้งใน Sentence Collector [กด no] และในตอนที่ พูด และ ฟัง [กด รายงาน] หรือถ้าไม่แน่ใจ กดข้าม/skip ได้ด้วยครับ
เข้าไปตรวจประโยคที่จะเอามาใช้ เจอแต่ประโยคที่แปลอัตโนมัติจากภาษาอังกฤษ บางคำก็สะกดผิดแปลกๆ
ถ้าพิจารณาจากมุมองของตัวเราซึ่งเจ้าของภาษาแล้วเห็นว่าแปลกเกินไป ตะหงิดๆ สามารถกด reject ได้เลยครับ (เรื่องนี้ก็พูดลำบาก เพราะแต่ละคนอาจจะรู้สึกแตกต่างกันไป แต่ไอเดียของ crowdsource แบบนี้ก็เพื่อให้มีคนมาช่วยกันทบทวนหลายคนครับ)
ส่วนที่สะกดผิด คำตก คำขาด กด reject ได้โลดครับ
เห็นด้วยกับความเห็นก่อนหน้าว่ามันแปลกๆ เยอะอยู่เหมือนกัน ส่วนหนึ่งอาจจะมาจากข้อจำกัดเรื่องจำนวนแหล่งข้อมูลสาธารณะที่ดึงมาได้ด้วยครับ ซึ่งถ้ามีแหล่งข้อมูลที่ปล่อยออกมาเป็น public domain มากขึ้น ก็สามารถที่จะดึงข้อมูลมาได้หลากหลายขึ้นครับ https://commonvoice.mozilla.org/sentence-collector/#/how-to
มีข้อสงสัยครับ เห็นบางท่านพยายามอ่านแยกคำ คล้ายๆ กับที่ Siri โต้ตอบ ณ ตอนนี้ที่ยังมีความเป็นหุ่นยนต์อยู่ค่อนข้างมาก แบบนี้ไม่ควรให้ผ่านใช่มั้ยครับ ควรพูดให้เป็นธรรมชาติจะดีที่สุดใช่มั้ยครับ
โดยหลักการถ้าพูดปกติให้เป็นธรรมชาติได้ ก็จะดีที่สุดครับ
แต่ถ้าฟังแล้วไม่ได้ถึงกับหุ่นยนต์มาก แค่เพียงพยายามอ่านทีละคำช้าๆ ไม่รวบคำ เพื่อให้ฟังง่าย ก็น่าจะยังโอเคอยู่ครับ (คล้ายเวลาพูดกับเด็กเล็ก หรืออ่านวลีที่ออกเสียงผิดง่าย) อันนี้ก็แล้วแต่ทางผู้ฟังซึ่งเป็นเจ้าของภาษาจะพิจารณาเองด้วยครับ ว่ามันยังพอได้อยู่ไหม
ขอบคุณครับ ข้อสงสัยอีกอย่างคือควรอ่านด้วยน้ำเสียงหรือสำเนียงแบบไหนดีครับ เพราะบางคนก็มาแนวอ่านนิทาน นิยาย บางคนหุ่นยนต์(ตามที่ยกไปก่อนหน้า) หรือบางคนก็แนวเรียบๆ ส่วนตัวคิดว่าควรจะใช้ประมาณผู้ประกาศข่าว น่าจะดีที่สุดมั้ยครับ
บางคนเหมือนจงใจอ่านผิด ตั้งใจเอาไว้เป็นตัวหลอกหรือเปล่าครับ
หรือว่ามีคนที่ไม่ได้ใช้ภาษาไทยเป็นภาษาแม่มาร่วมให้เสียงด้วย
แล้วก็ไปลองส่องดูในไฟล์มีบางเสียงอ่านควบกล้ำผิด แต่ได้รับ upvote 3 ซะงั้นแน่ะ
อย่าบอกนะว่า เริ่มมีสแปมกดโหวตแล้ว
-*-
โหลดไฟล์มาลองฟังดูได้ครับ พูดผิดเป็น ค่อน-ขล้าง-คล้าย แต่คะแนน upvote 3-0
common_voice_th_23655023.mp3
เพลินๆ อยู่นะ
สถิติผู้พูดเมื่อวาน ยัง 870 กว่า (ถ้าจำไม่ผิดนะ)
มาวันนี้ 4,247 คน
ป๊าดด คนสนใจเยอะมาก