By: lew 


 on 24 June 2022 - 12:17
Tags:
on 24 June 2022 - 12:17
Tags:

Alibaba Cloud เปิดศูนย์ข้อมูลในประเทศไทยไปเมื่อเดือนพฤษภาคมที่ผ่านมาทำให้ตอนนี้น่าจะเป็นผู้ให้บริการคลาวด์รายใหญ่ระดับโลกที่เป็นตัวเลือกของคนที่ต้องการใช้บริการที่ศูนย์ข้อมูลอยู่ในประเทศไทยเอง โดยตัวคลาวด์นั้นโดยทั่วไปแล้วเราก็มักจะนึกถึงบริการเซิร์ฟเวอร์และสตอเรจเป็นพื้นฐาน แต่หลังจากนั้นบริการต่อมาที่มีโอกาสใช้กันบ่อยๆ ก็คงเป็นบริการฐานข้อมูลที่ช่วงหลังๆ การใช้ระบบฐานข้อมูลแบบผู้ให้บริการคลาวด์จัดการให้ (managed database)
ทาง Alibaba Cloud ได้เปิดโอกาสให้ผมได้คุยกับดร. Feifei Li ที่ดำรงตำแหน่งรองประธาน Alibaba Group, ผู้อำนวยการของธุรกิจฐานข้อมูลใน Alibaba Cloud, และเป็น Chief Database Scientist ของ DAMO Academy หน่วยวิจัยของ Alibaba ในแง่วิชาการเขาเป็นนักวิชาการที่มีผลงานวิจัยด้านฐานข้อมูลจำนวนมาก และเป็นนักวิจัยระดับ ACM Fellow และ IEEE Fellow

Alibaba Cloud มีฐานข้อมูลแบบ managed database ให้บริการเช่นเดียวกับคลาวด์ชั้นนำทั่วไป และยังมีเอนจินฐานข้อมูลของตัวเอง คือ PolarDB ที่เป็นระบบฐานข้อมูลโอเพนซอร์ส
ทำไมผู้ให้บริการคลาวด์ต้องมีระบบฐานข้อมูลของตัวเอง และ PolarDB ต่างจากฐานข้อมูลของคลาวด์รายอื่นอย่างไร
ฐานข้อมูลเป็นบริการที่สำคัญที่สุดตัวหนึ่งของผู้ให้บริการคลาวด์ทุกราย จึงเป็นเรื่องปกติที่ผู้ให้บริการคลาวด์จะลงทุนวิจัยระบบฐานข้อมูลอย่างหนัก ทาง Alibaba เองก็เริ่มพัฒนามาประมาณ 5 ปีแล้ว
เหตุผลหนึ่งที่เอนจินฐานข้อมูลของผู้ให้บริการคลาวด์ต้องพัฒนาเพิ่มเติมคือ คลาวด์มักแยกระบบสตอเรจออกจากระบบประมวลผล ขณะที่เซิร์ฟเวอร์ฐานข้อมูลที่ใช้งานกันตัวสตอเรจจะอยู่ในเซิร์ฟเวอร์ประมวลผลเป็นเนื้อเดียวกัน
โดยทั่วไปคิวรีที่เข้าไปยังบริการฐานข้อมูลจะถูกดักไว้ด้วย proxy คั่น แล้วดูว่าเป็นคิวรีสำหรับการอ่านอย่างเดียว หรืออ่านและเขียนด้วย หากมีการเขียนด้วยก็จะส่งไปให้เครื่องหลัก (primary)
สำหรับเอนจินอื่นๆ เช่น Aurora นั้นอาศัยการส่ง binlog จากเครื่อง primary ไปยัง secondary เพื่อแก้ไขข้อมูลให้เหมือนกับเครื่อง primary แนวทางนี้กระจายโหลดได้ แต่หากคิวรีมีการเขียนจำนวนมากๆ (write intensive) ก็จะเกิดปัญหาเพราะเครื่อง secondary จะโหลดหนักเนื่องจากต้องรัน binlog ใหม่
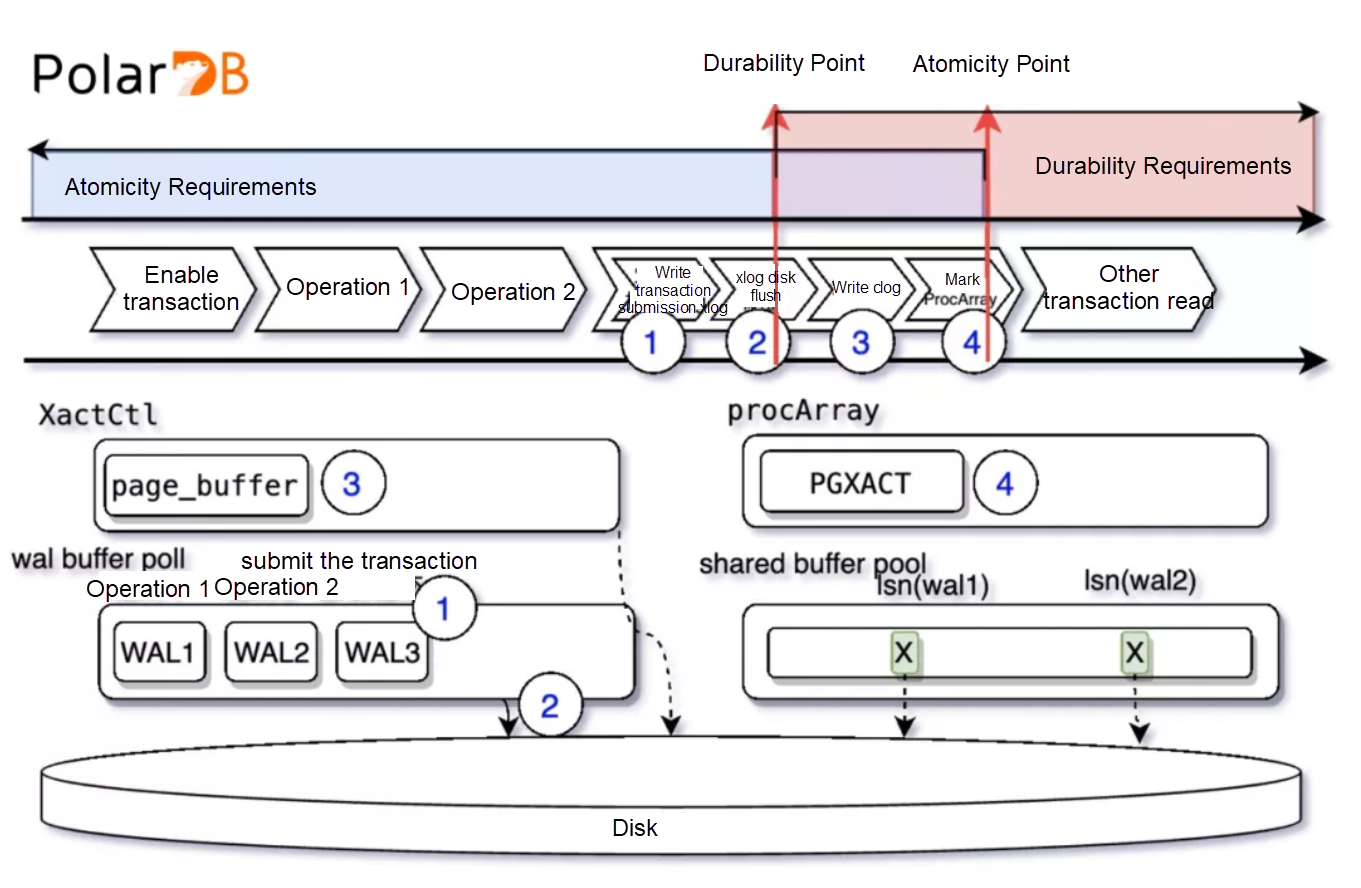
ใน PolarDB ทาง Alibaba อาศัยการซิงก์สตอเรจด้านล่าง หลังจากที่เขียนข้อมูลสำเร็จแล้ว พร้อมๆ กับการส่ง binlog ไปด้วย การซิงก์สตอเรจโดยตรงทำให้มีการส่งข้อมูลผ่านเน็ตเวิร์คปริมาณสูงขึ้น แต่ก็ลดโหลดซีพียูในเครื่อง secondary ลง ในกรณีที่มีการเขียนหนักๆ ระยะเวลาที่ใช้ซิงก์ไปยังเครื่อง secondary นั้นดีกว่าการส่ง binlog เสียอีก
แนวทางของ PolarDB ยังมีข้อดีคือการทำ multi-master ให้สามารถเขียนพร้อมกันได้หลายเครื่องนั้นทำได้ง่ายกว่ามาก ช่วยรองรับโหลดงานที่ต้องเขียนหนักๆ โดยยังรองรับ ACID ได้ครบถ้วน
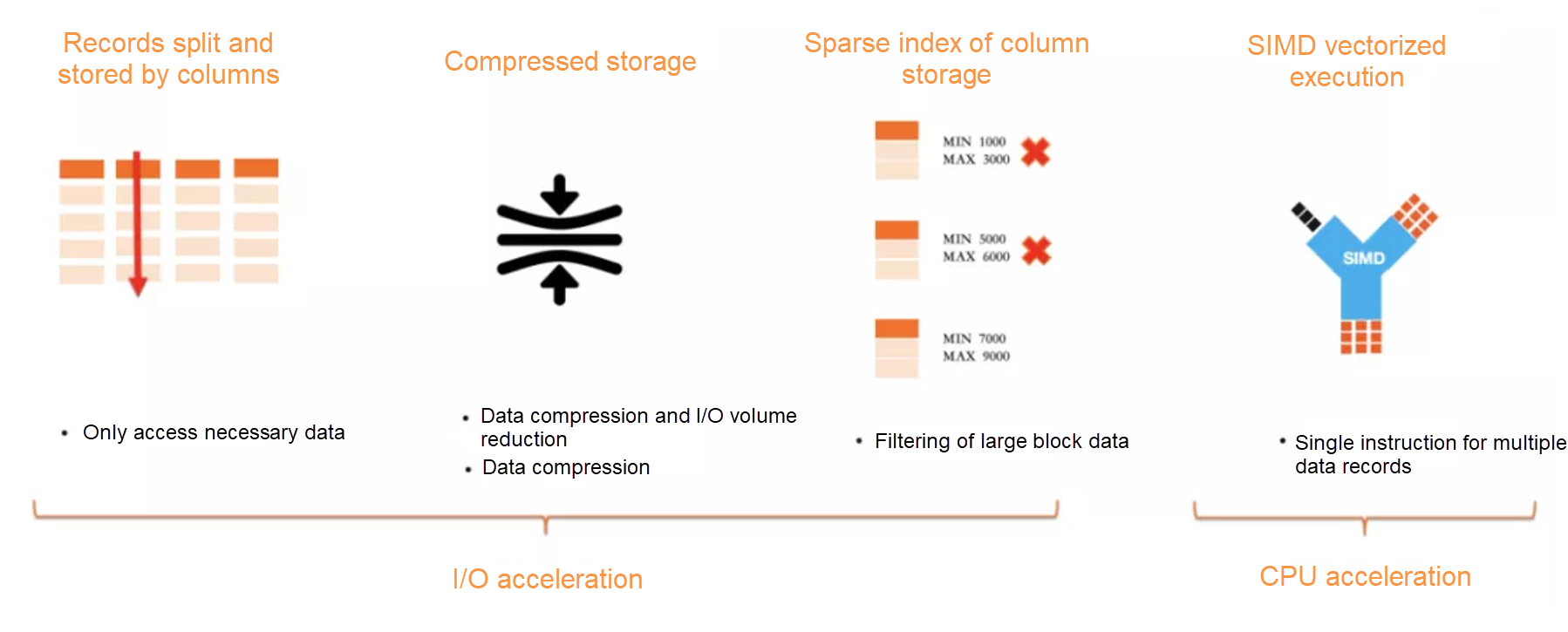
ฟีเจอร์สำคัญของ PolarDB คือการรองรับ Hybrid transactional/analytical processing (HTAP) ในตัว ซึ่งโดยทั่วไประบบฐานข้อมูลมักเพิ่มโหนดอีกส่วนหนึ่งสำหรับการเก็บฐานข้อมูลแบบ analytics เรียกว่า learner แปลงฐานข้อมูลจาก row-store เป็น column-store แต่แนวทางนี้มีข้อเสียสำคัญคือข้อมูลในระบบ analytics จะมีดีเลย์ไปพอสมควร
PolarDB พยายามรองรับ HTAP ด้วยการแชร์หน่วยความจำระหว่างโหนดเข้าด้วยกัน ทำให้หน่วยความจำระหว่างเครื่องกลายเป็น memory pool แล้วสร้าง in-memory column-index เพื่อรองรับโหลด HTAP โดยเฉพาะ เมื่อพบคิวรีที่เป็นงาน analytics ก็จะคิวรีจาก column-index ทำให้ประสิทธิภาพการคิวรีแบบ analytics สูงขึ้นมาก ตอนนี้ฟีเจอร์ HTAP เริ่มเปิดให้ใช้งานแล้วในจีน และกำลังจะขยายออกมาภูมิภาคอื่นต่อไป
การออกแบบของ Alibaba Cloud ดูจะไม่กลัวที่จะส่งข้อมูลผ่านเน็ตเวิร์คปริมาณมากๆ นัก ทำไมจึงเลือกออกแบบเช่นนั้น
การออกแบบระบบกระจายตัวแบบนี้ก็เป็นการแลกเปลี่ยนกัน (trade off) จุดที่เรากังวลที่สุดของการส่งข้อมูลผ่านเน็ตเวิร์คที่สุดคือความหน่วง (latency) แต่เน็ตเวิร์คในยุคคลาวด์ทุกวันนี้ก็เป็นของที่หาได้ไม่ยากแล้ว เน็ตเวิร์คประสิทธิภาพสูงอย่าง RDMA นั้นมีให้ใช้งานในระบบคลาวด์โดยทั่วไป การเชื่อมต่อเน็ตเวิร์คระดับ 100Gbps หรืออย่างต่ำก็ 25Gbps ก็ไม่ใช่ของแพงเกินไปสำหรับผู้ให้บริการ public cloud
PolarDB มีเวอร์ชั่นออราเคิลด้วย ทาง Alibaba สร้างฐานข้อมูลที่ทำงานร่วมกับแอปพลิเคชั่นที่ออกแบบมาเพื่อออราเคิลได้อย่างไร
ออราเคิลเป็นฐานข้อมูลที่ดีที่สุดตัวหนึ่งสำหรับการใช้งานบนโครงสร้าง on-premise แต่ลูกค้าจำนวนหนึ่งก็ต้องการหันมาใช้ระบบฐานข้อมูลบนคลาวด์เช่น PolarDB เราพัฒนา PolarDB for Oracle ขึ้นมาจาก PostgreSQL ที่เข้ากันได้กับออราเคิลอยู่แล้วในระดับหนึ่ง แล้วพัฒนาเลเยอร์เสริมเพื่อให้รองรับฟีเจอร์บางอย่างของออราเคิลเพิ่มเติม เช่น stored-procedure, operator, PL/SQL เพื่อให้ลูกค้าสามารถย้ายแอปพลิเคชั่นขึ้นมารันบน PolarDB ได้สะดวกขึ้น
แต่ทั้งหมดก็ไม่ได้ทำให้ PolarDB for Oracle เข้ากันได้กับออราเคิลเต็มร้อย ลูกค้ายังต้องปรับแก้แอปพลิเคชั่นอยู่บ้าง
นอกจากนี้ยังมีฟีเจอร์ระดับองค์กรที่ลูกค้าใช้งานอยู่ เช่น query result cache, materialized view ที่ระบบฐานข้อมูลบนคลาวด์ยังไม่มีฟีเจอร์เหล่านี้ แต่เราก็กำลังพัฒนาเพื่อไล่ตามอย่างต่อเนื่อง

Get latest news from Blognone
Follow @twitterapi



Comments
โอ้วว คาดหวังให้ genshin ทำเซิฟเวอร์ที่ไทยได้ไหมนะ
The Last Wizard Of Century.
ACM Fellow และ IEEE Fellow สวดยอด