

Mistral AI บริษัทปัญญาประดิษฐ์จากฝรั่งเศสเปิดตัวโมเดลรุ่นใหม่ในชื่อ Mixtral 8x7B เป็นโมเดลที่อาศัยสถาปัตยกรรม mixture-of-experts (MoE) ผสมเอาท์พุตระหว่างโมเดลย่อยๆ ภายใน
ขนาดโมเดลรวม 46.7 พันล้านพารามิเตอร์ แต่ระหว่างรันจริง โมเดลจะเรียกใช้โมเดลที่เหมาะสมเพียง 2 ตัวจาก 8 ตัว จากนั้นจะเลือกเอาท์พุตแต่ละโทเค็นจากสอง 2 ตัวนั้นมาใช้งาน ทำให้เวลารันจริงจะใช้พลังประมวลผลเครื่องเท่ากับโมเดลขนาด 12.9 พันล้านพารามิเตอร์เท่านั้น
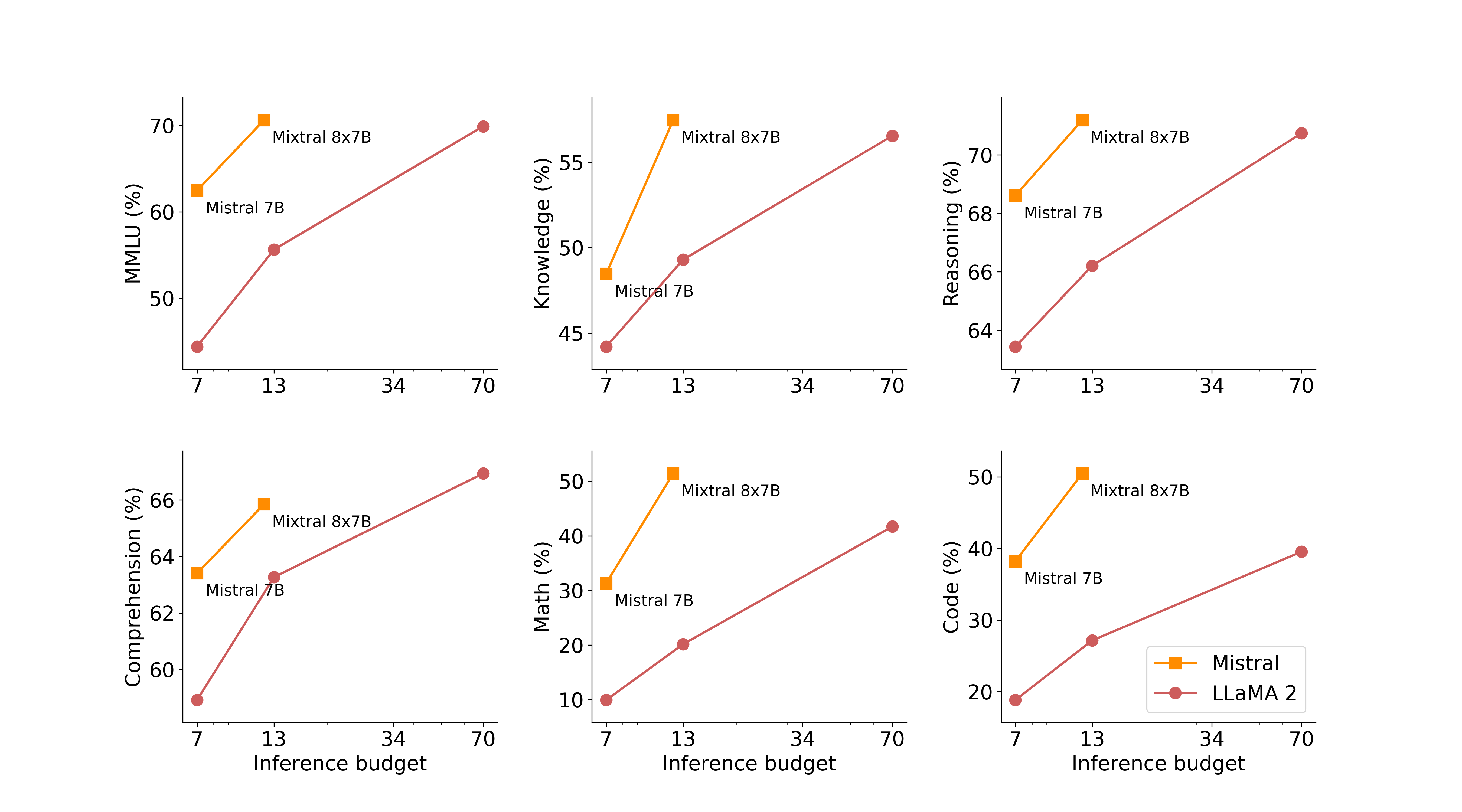
แนวทาง MoE ทำให้ Mixtral มีคะแนนทดสอบชุดทดสอบต่างๆ ใกล้เคียง GPT-3.5 แม้ขนาดโมเดลและพลังประมวลผลที่ใช้รันจะน้อยกว่ามาก คะแนนทดสอบหลายชุดดีกว่า LLaMA 2 มากแม้จะเทียบกับโมเดลขนาด 70B ก็ตาม
แม้ว่าโมเดลจะเปิดเป็นโอเพนซอร์ส แต่ทาง Mistral AI ก็เตรียมเปิดบริการ API จ่ายเงินใช้งาน โดยตอนนี้เปิดให้ลงชื่อเข้าคิวใช้ API อยู่
ที่มา - Mistral AI

Get latest news from Blognone
Follow @twitterapi


