

OpenAI ประกาศฟีเจอร์ฝั่งนักพัฒนาชุดใหญ่ โดยฟีเจอร์สำคัญคือการเปิด API รับข้อมูลเสียงโดยตรงเปิดทางสร้างแอปพลิเคชั่นคุยแบบธรรมชาติใน Advanced Voice Mode จากเดิมที่นักพัฒนานอก OpenAI ไม่สามารถทำแอปเหมือนกันได้
การรับเสียงจะสามารถใช้งานได้ทาง Realtime API ที่เชื่อมต่อกับเซิร์ฟเวอร์ผ่าน WebSocket แทน HTTP แบบเดิม แม้จะออกแบบมาเพื่อคุยเสียงเป็นหลักแต่ที่จริงก็ใช้คุยแชตข้อความปกติได้ พร้อมกันนี้ Chat API เดิมก็จะรองรับข้อมูลเสียงและโมเดล GPT-4o สามารถตอบกลับเป็นเสียงได้เหมือนกัน แม้จะไม่ตอบกลับทันทีเหมือน Realtime API
โมเดลที่รองรับเสียง คือ gpt-4o-realtime-preview และ gpt-4o-audio-preview ค่าใช้งานเสียงประมาณ 0.06 ดอลลาร์ต่อนาทีสำหรับอินพุตและ 0.24 ดอลลาร์ต่อนาทีสำหรับเอาท์พุต
การปรับแต่งโมเดล (fine tuning) รองรับการฝึกด้วยรูปภาพเพื่อใช้งานเฉพาะทางบางอย่าง เช่น การอ่านป้ายจราจร, การทำระบบคลิกหน้าจออัตโนมัติ, หรือการสร้างเว็บโดยมองภาพหน้าจอ ทาง Coframe นำ GPT-4o ไปฝึกเพิ่มเติมเพื่อสร้างเว็บให้ตรงสไตล์จากภาพต้นฉบับ ทำได้ดีขึ้น 26% เทียบกับโมเดลเดิมๆ
การฝึกต้องใช้โมเดล gpt-4o-2024-08-06 ค่าฝึก 25 ดอลลาร์ต่อล้านโทเค็น ค่าใช้งาน 3.75 ดอลลาร์ต่ออินพุตล้านโทเค็น และ 15 ดอลลาร์ต่อเอาท์พุตล้านโทเค็น
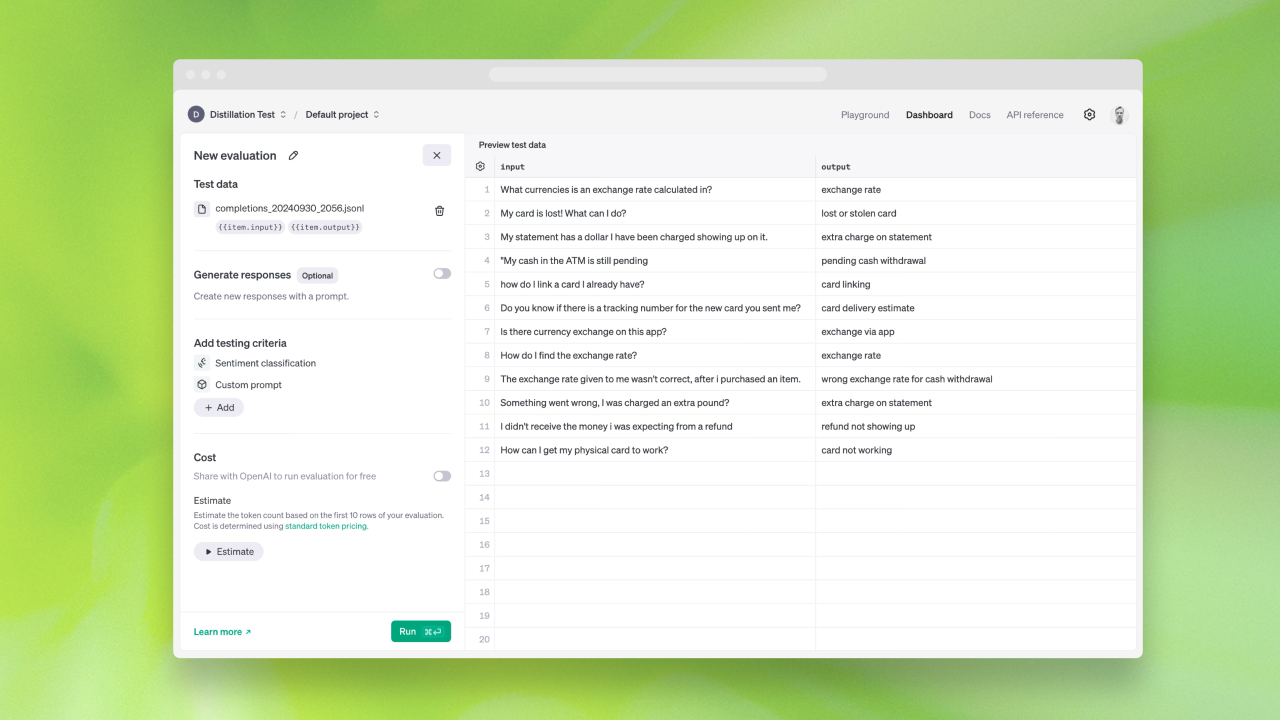
ฟีเจอร์ฝึกความสามารถจากโมเดลรุ่นใหญ่ (Model Distillation) นำผลจาก GPT-4o หรือ o1-preview ไปฝึก GPT-4o-mini ให้ความสามารถเฉพาะเรื่องขึ้นมาใกล้เคียงกัน ฟีเจอร์ส่วนนี้ที่จริงผู้ใช้สามารถทำเองได้อยู่แล้ว แต่ OpenAI ทำบริการเสริมช่วยเก็บผลลัพธ์จากโมเดลขนาดใหญ่ไว้ให้ พร้อมระบบวัดผล ทำให้สามารถใช้งานได้สะดวกขึ้นมาก
สุดท้ายคือระบบ Prompt Caching ที่ช่วยลดค่าใช้จ่ายหากสั่งด้วยพรอมพ์ที่ขึ้นต้นด้วยรูปแบบที่ซ้ำๆ กัน โดยต้องซ้ำกันอย่างน้อย 1,024 โทเค็นจึงเริ่มใช้งานแคชได้ จากนั้นจะใช้แคชทีละ 128 โทเค็นไปเรื่อยๆ หากเจอแคชก็จะลดค่าใช้งานลงครึ่งหนึ่ง แคชจะแชร์ในองค์กรเดียวกันเท่านั้น และจะเก็บแคชไม่เกินหนึ่งชั่วโมงหากไม่ได้ใช้งานจะลบออกภายใน 5-10 นาที

Get latest news from Blognone
Follow @twitterapi



Comments
น่าสนใจฟีเจอร์ Prompt Caching อยากได้เลย ทาง Gemini น่าจะมีบ้างนะ เพราะถ้าทำให้ระบบสื่อสารกันด้วยเสียงโดยตรง สำหรับงานเฉพาะทาง มันจะมีคำซ้ำในปริมาณมากเพราะงานพวกนี้คำสั่งก็จะวนไปมาในรูปแบบเดิมๆ เปลี่ยนแค่ parameter มันจะช่วยให้ลดค่าใช้จ่ายสำหรับงานฝั่ง enterprise และผลักดันให้มีการใช้งานจริงจังมากขึ้น เนื่องจากค่าใช้จ่ายที่ถูกลง
ที่ผมคิดนะ คือ ใช้ model ในเครื่องสำหรับการแปลงเสียงเป็นตัวอักษร (ซึ่งมีความสามารถน้อยกว่า Gemini แต่ก็แทนที่มาด้วยค่าใช้จ่ายที่ต่ำกว่า มีโอกาสแปลงเสียงเป็นคำผิดมากกว่า แต่แก้ไขด้วยการส่งไปที่ Server เพื่อตรวจสอบ และพยากรณ์อีกทีว่าจริงๆ แล้ว user พูดว่าอะไรกันแน่ เพราะคำที่ผิดส่วนใหญ่มันก็พอจะหารากคำได้ หากมีฐานข้อมูลคำสั่งเก็บไว้) แล้วใช้ gemini บน server ช่วยคาดเดาคำสั่งที่คิดว่าผู้ใช้เรียกใช้งาน และแยก parameter ส่งกลับมา โดย train เป็น model เฉพาะสำหรับเรียนรู้คำสั่งเพื่อควบคุมงานเฉพาะทาง รวมถึง parameter ที่คาดว่าจะมีในการใช้งาน ซึ่งถ้าแบบนี้จะช่วยลดค่าใช้จ่ายหากมี Prompt Caching
Gemini มี Context Caching ก่อนแล้วครับ แต่เหมือนจะต้องลบออกเอง
lewcpe.com, @wasonliw