By: lew 


 on 28 January 2015 - 16:35
Tags:
on 28 January 2015 - 16:35
Tags:
Topics:

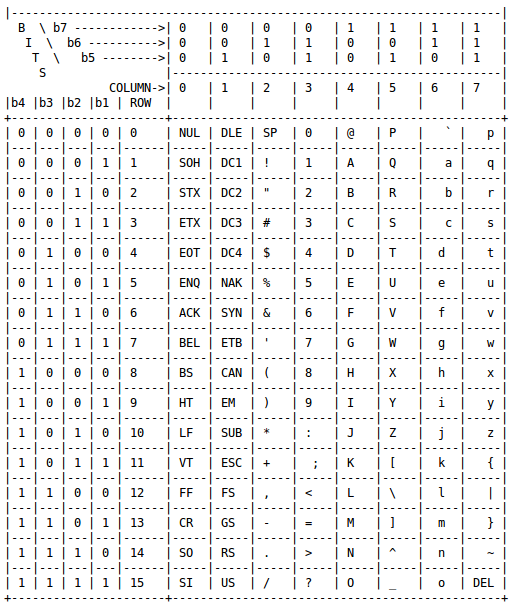
มาตรฐาน ASCII ที่เราใช้พิมพ์ภาษาอังกฤษในคอมพิวเตอร์ทุกวันนี้ นับตั้งแต่ตัวอักษร, เครื่องหมาย, คำสั่ง เช่น ลบหรือขึ้นบรรทัดใหม่ ล้วนถูกกำหนดไว้ในตาราง ASCII ที่เขียนกำหนดไว้ใน RFC20 โดย Vint Cerf มาตั้งแต่ปี 1969 ผ่านมา 46 ปีตอนนี้ RFC20 ได้รับสถานะ "มาตรฐานอินเทอร์เน็ต" เต็มรูปแบบจาก IETF แล้ว
เหตุที่ RFC20 เพิ่งได้รับสถานะมาตรฐานอินเทอร์เน็ตเพราะมันถูกเขียนมาก่อนจะมีกระบวนการรับรองมาตรฐานอินเทอร์เน็ต ทำให้เอกสารอยู่ในสภาพไร้สถานะใน IETF มาโดยตลอด
ทาง IETF อนุมัติการประกาศมาตรฐานนี้ตั้งแต่วันที่ 12 ที่ผ่านมา และปรับสถานะในตัวเอกสารในวันนี้
ถึงตอนนี้ก็เขียน ASCII กันได้สบายใจไม่ต้องดราม่าว่าไม่ใช่มาตรฐานเปิดครับ
ที่มา - +Lauren Weinstein

Get latest news from Blognone
Follow @twitterapi



Comments
สมกับเป็นตาราง ASCII วาดด้วยอักขระ ASCII ทั้งหมด
--
มาตรเช็คอายุเลยตัวนี้ - :D
ทำไมตารางมีแค่ 7 บิตอะครับ แล้วตั้งแต่ 0x80 ถึง 0xFF หายไปไหน
ยินดีด้วยครับ ถามแบบนี้แสดงว่ายังไม่แก่จริง :P
lewcpe.com, @wasonliw
เหอะๆ เจอแบบนี้ ขอเงียบดีกว่า
ตอบงี้เล่นเอาจุกเลย
Ton-Or
เจอแบบนี้เข้าไป ไม่กล้าตอบเลย
ในตารางมันน่าเป็น ASCII 63 รึเปล่าครับ ดั้งเดิม มันเลยมีแค่ 128 ตัว 7 บิต
แล้วบิตที่ 8 เพิ่มมาทีหลัง ให้ตัวหนังสือภาษาอื่น
ปล. เดานะ เดา ผมเดาล้วนๆ เลย
บิตที่เหลือใช้เป็น parity bit ครับ (บิตสำหรับตรวจสอบความถูกต้อง) แต่ถ้าเอา ASCII มาใช้กับภาษาไทย parity bit จะถูกเอามาใช้เป็นบิตข้อมูลแทนครับ
ปล. ผมไม่แก่นะ
ไม่รู้แหะ เกิดมาก็ UTF-16 แล้ว :P
bit7 ที่เป็น msb ภายหลังถูกเอามาทำเป็น codepage ครับ เช่น windows-874 หรือ tis-620 นั่นแหละครับ
มันก็ 8bit ไม่ใช่เหรอครับ แต่มันนับ 0 ถึง 7 คอมพิวเตอร์เลขเริ่มต้นที่มันนับคือ 0 นิครับไม่ใช่ 1 ไอ้ที่ว่า 0x80 ถึง 0xFF ผมไม่รู้เรื่องฮ่าๆๆ มันฐาน 16 แล้วไม่ใช่เหรอนั่น จำนวนบิตเขาไว้เรียกใน ฐาน 2 นี่นา หรือผมเมา
เรียนมาก็ลืมจะหมดแล้ว มันไปถึงในกันแล้วเนี่ย sign bit เอย priority bit เอย ตีกันมั่วไปหมดแระ
อ๋าผมไปละลึกชาติมาแล้ว ถ้าใครเคยเล่น ภาษา C ใน Turbo c จะรู้ ว่าโค๊ต ASCII มันเอามาใช้เล้นกันสนุกเลยโดยเฉพาะตีตาราง แล้วก็โค๊ต ASCII มันมีแค่ 8 bit เท่านั้น ที่เป็นไปได้คือ 00 ถึง FF (แต่จะมีหรือเปล่านั้นอีกเรื่อง ก็ลอง run 0 ถึง 127 เป็น %C ดูครับ)แต่ ระบบอื่นผมไม่ได้เรียนเลยอ่ะ
ในตารางใช้ b1 ถึง b7 ครับ
Russia is just nazi who accuse the others for being nazi.
someone once said : ผมก็ด่าของผมอยู่นะ :)
ผมละลึกชาติได้แระ มันใช้ทั้งหมด 8 bit ครับ 7bit ในการแทนตัวสัญลักษณ์ต่างๆ ส่วน bit แรกสุด เขาใช้เป็น sign bit หรือก็คือ + กับ - เท่าที่ผมเคยเรียนมาหน่ะนะ เพราะฉะนั้น ถ้าเขียนโปรแกรมใน Turbo C ก็สั่งให้มัน Run เลข ฐาน 10 จาก 0 ถึง 127 แล้วสั่งแสดงผลเป็น Char (%C) ก็จะได้ตาราง ASCII ครับ เคยทำสูงกว่านั้นอยู่ แต่ผมจำไม่ได้ว่าผลเป็นยังไง คลับคล้ายคลับคราว่าเจอตัวอักษรประเทศอื่นๆด้วย
ปล. กำลังพิมพ์แก้เพิ่มเลย เจอมีคนตอบก่อน ฮ่าๆๆ เลยต้องตั้งใหม่
7bit ASCII(as char) ถูกใช้ในยุคแรกๆครับ อันนี้ผมไม่เท้าความมากนะครับ แต่ขอบอกคร่าวๆว่าเมื่อก่อน computer ไม่ได้ใช้ระบบ 8bit-based(8,16,32,64) หน่ะครับ
ส่วน sign bit(as number types) ไม่เกี่ยวข้องกับกรณีนี่นะครับ
Russia is just nazi who accuse the others for being nazi.
someone once said : ผมก็ด่าของผมอยู่นะ :)
ใช่ครับไม่เกี่ยวข้อง มันเลยเป็น 0 อยู่อย่างงั้น(เห็นมีคนถามว่า bit ที่เหลือไว้ทำอะไรหน่ะครับ ส่วนตัวผมมองว่าเขาเขียนให้ครบ 8 bit เผื่อในกรณี จะเขียนในรูปฐาน 16 ได้มากกว่าครับ สั้นดีด้วย) เพราะตัวกำหนดไม่ได้อยู่ที่ชุดตัวเลข 8 bit พวกนี้ แต่เป็นคำสั่งในการแสดงผลว่าจะให้แสดงในรูปแบบใหนมากกว่านี่ครับ เขาเลยสร้างรูปแบบรหัสใหม่ขึ้นมาเพื่อรองรับอักขระ ให้มากขึ้น จริงๆมันก็ 127 ตัวแรกก็เป็นรหัสชุดเดิม แต่บวกอักขระ ต่างๆเพิ่มเข้าไปต่อจาก ASCII เลย ระยะห่างผมจำไม่ได้ แต่มีช่องว่างระหว่างกันเยอะอยู่กว่าจะขึ้นอักขระชุดใหม่
ส่วนที่ว่า "computer ไม่ได้ใช้ระบบ 8bit-based(8,16,32,64)" อันนี้ผู้สอนผมเขาไม่ได้เล่าเลยอ่ะครับ(แต่พูดสะผมสนใจ จนอยากไปคุ้ยข้อมูลกันเลยทีเดียว) เหอๆ ขอบคุณสำหรับความรู้ครับ
อ่า... ไปอ่านมาได้ข้อความสรุปมาว่า
รหัสแอสกีมีใช้ในระบบคอมพิวเตอร์ และเครื่องมือสื่อสารแบบดิจิทัลต่างๆ พัฒนาขึ้นโดยคณะกรรมการ X3 ซึ่งอยู่ภายใต้การดูแลของสมาคมมาตรฐานอเมริกา (American Standards Association) ภายหลังกลายเป็น สถาบันมาตรฐานแห่งชาติอเมริกา (American National Standard Institute : ANSI) ในปี ค.ศ. 1969 โดยเริ่มต้นใช้ครั้งแรกในปี ค.ศ. 1967 ซึ่งมีอักขระทั้งหมด 128 ตัว (7 บิต) โดยจะมี 33 ตัวที่ไม่แสดงผล (unprintable/control character) ซึ่งใช้สำหรับควบคุมการทำงานของคอมพิวเตอร์บางประการ เช่น การขึ้นย่อหน้าใหม่สำหรับการพิมพ์ (CR & LF - carriage return and line feed) การสิ้นสุดการประมวลผลข้อมูลตัวอักษร (ETX - end of text) เป็นต้น และ อีก 95 ตัวที่แสดงผลได้ (printable character)
รหัสแอสกีได้รับการปรับปรุงล่าสุดเมื่อ ค.ศ. 1986 ให้มีอักขระทั้งหมด 256 ตัว (8 บิต) และเรียกใหม่ว่าแอสกีแบบขยาย อักขระที่เพิ่มมา 128 ตัวใช้สำหรับแสดงอักขระเพิ่มเติมในภาษาของแต่ละท้องถิ่นที่ใช้ เช่น ภาษาเยอรมัน ภาษารัสเซีย ฯลฯ โดยจะมีผังอักขระที่แตกต่างกันไปในแต่ละภาษาซึ่งเรียกว่า โคดเพจ (codepage) โดยอักขระ 128 ตัวแรกส่วนใหญ่จะยังคงเหมือนกันแทบทุกโคดเพจ มีส่วนน้อยที่เปลี่ยนแค่บางอักขระ
ที่มา : http://th.wikipedia.org/wiki/แอสกี
สรุปผมเข้าใจผิดเองแหล่ะ
พอกันก่อนเดี๋ยวโควต้าหมด
คุณยังไม่เข้าใจครับว่าทำไมถึงเป็น 7bit แต่ไม่ใช่ 8bit และยังอิงกับค่า 0/1 ใน bit ที่ 8 อยู่ เพราะว่าคุณยังอิงกับระบบ 8bit อยู่ครับ
ต้นกำเนิดของ ASCII อยู่ที่ ASCII-7bit ครับหรือพูดง่ายๆว่าไม่มีบิตที่ 8 โดยระบบ 8bit นี่มาทีหลัง
Edit:อ่าวเกือบเร็วเกินไป - -"
Russia is just nazi who accuse the others for being nazi.
someone once said : ผมก็ด่าของผมอยู่นะ :)
คาดว่าโคต้าตอบอันนี้คงหมดพอดี หุหุ
ใช่ครับผมโดนสอนมาแตั้งแต่มาเรียนสายนี้ตอนมหาวิทยาลัยว่า 8bits เป็น 1byte เลยหน่ะ แต่ถึงจะใช้น้อยกว่านั้นคอมพิวเตอร์ก็เอาไปแปลงเป็น 8 อยู่ดีเพื่อให้มันเท่ากับขนาดหน่วยของหน่วยความจำหลักถึงไม่ใส่มันก็จะเติม 0 ให้เต็ม 8 bit ให้เอง ก็อย่างว่านะเมื่อก่อนมันใช้แค่อเมริกาจะเอาอะไรเยอะแยะ เพราะยังไม่ได้ทำอะไรที่ซับซ้อนมาก แล้วก็ตอนที่ผมเล่นตอนนั้นก็เพราะเป็นแอสกีแบบขยายแล้วซะด้วย ถ้าไม่มีบทความบอกความเป็นมา 7bit ยุคเก่าก็จะถูกลืมไปเลย
การที่ท่านมาตอบกับผมก็ช่วยปรับความเข้าใจผมได้เยอะขึ้นหน่ะนะครับ
แล้วก็ไอ้จำนวนหน่วยพวกนี้แหล่ะที่ทำให้คนสับสนได้เช่นว่า Mb กับ MB มันต่างกัน ถ้าไม่ดูให้ดีๆอาจโดนหลอกได้ โดยเฉพาะ ความเร็ว Intermet\
แต่ในที่สุดท่าน arth ก็ได้คำตอบแล้วหล่ะ เหอๆ