By: mk 
 on 27 February 2016 - 10:57
Tags:
on 27 February 2016 - 10:57
Tags:

รอบปีมานี้เราเห็นบริษัทไอทีใหญ่ๆ หลายรายทยอยเปิดซอร์สซอฟต์แวร์ด้าน deep learning ของตัวเอง เช่น TensorFlow ของกูเกิล หรือ CNTK ของไมโครซอฟท์
บริษัทที่หลายคนอาจลืมไปแล้วอย่าง Yahoo ก็ร่วมขบวนนี้ด้วยเหมือนกัน ซอฟต์แวร์ตัวนี้เรียกว่า CaffeOnSpark เอาไว้เทรน AI สำหรับงาน deep learning บนคลัสเตอร์ Hadoop/Spark ที่รันงาน big data อยู่แล้ว
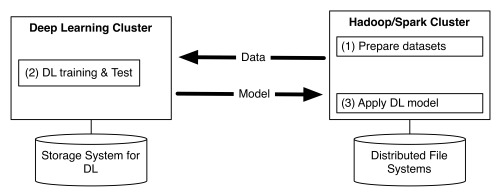
โดยทั่วไปแล้ว ระบบคลัสเตอร์สำหรับเก็บข้อมูล big data มักแยกจากคลัสเตอร์ deep learning (ทั้งที่เป็นข้อมูลชุดเดียวกัน) ส่งผลให้ระบบซับซ้อน เพราะต้องโอนถ่ายข้อมูลไปมาระหว่างคลัสเตอร์สองระบบ ไอเดียของทีม Yahoo จึงเป็นการรันโมเดล deep learning บนคลัสเตอร์ Spark โดยตรงแทน ช่วยให้มีคลัสเตอร์เพียงชุดเดียวสำหรับงานทั้งสองแบบ
สถาปัตยกรรมคลัสเตอร์แบบเดิม
สถาปัตยกรรมคลัสเตอร์แบบใหม่
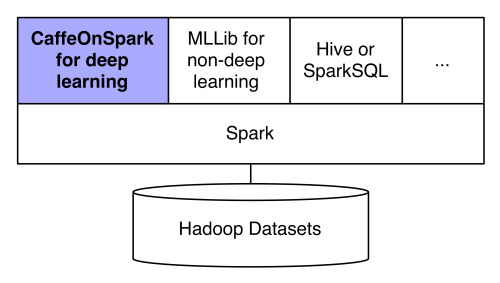
CaffeOnSpark ถูกใช้งานภายใน Yahoo มาได้สักพักแล้ว (ทีม Flickr ก็นำไปใช้งานประมวลผลรูปภาพ) ตอนนี้มันถูกเปิดซอร์สให้คนอื่นใช้แล้ว ภายใต้สัญญาอนุญาตแบบ Apache 2.0 ตัวโค้ดอยู่บน github
ที่มา - Yahoo Tumblr

Get latest news from Blognone
Follow @twitterapi


Comments
CafeeOnSpark => CaffeOnSpark