By: lew 


 on 26 June 2017 - 17:31
Tags:
on 26 June 2017 - 17:31
Tags:
Topics:
คุณรักพงษ์ กิตตินราดร และคุณกรกฎ เชาวะวณิช Data Scientist จาก True Corporation เปิดซอร์สโครงการ deepcut ระบบตัดคำแบบ deep learning โดยพัฒนาด้วย Keras
ข้อมูลที่ใช้เทรนเป็นชุดข้อมูล BEST ของ NECTEC โดยแบ่งข้อมูลสำหรับฝึก 90% และข้อมูลสำหรับทดสอบอีก 10% โมเดลพยายามระบุว่าแต่ละตัวอักษรเป็นจุดเริ่มต้นของคำหรือไม่ (ตามโค้ดคือค่ามากกว่า 0.5) โดยเมื่อทดสอบกับข้อมูลทดสอบได้ความแม่นยำ f1 score 98.8%, precision score 98.6%, และ recall score 99.1%
ผมทดสอบดูเทียบกับ libthai ที่ใช้งานกันในลินุกซ์ในภาพท้ายข่าว โดยใช้ประโยคตัวอย่าง "คุณบ็อตบอกว่าวันนี้พิมพ์ไม่ผิดแต่ตัดแบบนี้จะดีเหรอ คณะกรรมการการเลือกตั้งกรมวิทยาศาสตร์การแพทย์ เขานอนตากลมตากลมไปมา"
ที่มา - GitHub:rkcosmos/deepcut, Thailand Deep Learning
ผลจาก deepcut
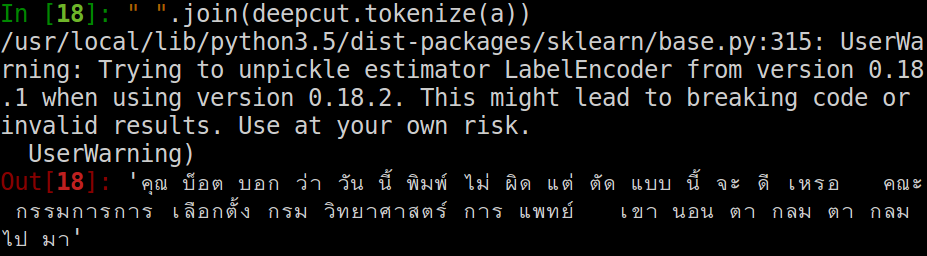
ผลจาก libthai


Get latest news from Blognone
Follow @twitterapi



Comments
นอนตากลม อันนี้ hardcode ได้ไหม ไม่ต้อง learn ฮาาาา
สงสัย
ตา กลม หรือ ตาก ลม
ภาษาอะไรฟระ ตัดคำยากอิ๊บอ๋ายยย
"เขานอนตากลมตากลมไปมา" ผมอ่านได้ว่า เขานอน ตา กลม ตาก ลม ไปมา นี่ถูกไหมครับ
ถูกครับ
lewcpe.com, @wasonliw
ผมว่า "เขา นอน ตา กลม ตาก ลม ไป มา" ก็ได้นะ 555
น่าจะพอร์ตกลับไปเป็น C นะครับ จะได้นำไปใช้ได้ง่ายขึ้น :)
ผมว่า libthai ก็ดีพอใช้งานนะครับ
lewcpe.com, @wasonliw
ก็แม่นระดับคนได้ละ ตา กลม กับ ตาก ลม คนยังงเลย แต่อยากได้พวกแชทบอท ML อะ
ทำยังไงให้ pythai ใช้กับ python3 ได้ครับ
-- edit ผมไปลองกับ PyICU ได้แบบนี้

ลองเทียบๆ กันดูครับ
ผมก็ใช้ไม่ได้ครับ คงต้องแพตช์แก้ก่อน
lewcpe.com, @wasonliw
'เกษตรกรอบกรอบ' จะตัดคำเป็นยังไง
คนอ่านยังตัดไม่ถูกเลยครับ 5555
เป็นเคสที่ฮามาก ผมคิดว่าเคสนี้ยากสำหรับคนแต่ไม่ได้ยากสำหรับคอมครับ ถ้ามี training data สอนหน่อยก็จับ pattern ได้เลย คำว่า เกษตร|กรอบ| คงไม่มีโผล่มา เคสที่ยากสำหรับคอมคือพวกที่เป็นไปได้มีใช้งานจริงทั้งสองแบบแล้วต้องดูบริบทประกอบด้วย
SPICYDOG's Blog
อันนี้อยากรู้ตัดว่าไงครับ?
เกษตรกร อบกรอบ
เกษ ตร กรอบ กรอบ
เกษตร กรอบกรอบ
กะ เสด ตะ กอน อบ กอบ
ผมว่ามันกำกวมครับ ตัดได้ทั้งสองแบบ
เกษตรกร-อบ-กรอบ คือเกษตรกร(อาชีพ)ไม่ใช่ของที่เอาไปอบกรอบได้จริงๆ แล้วก็ไม่ค่อยเห็นสำนวน <อาชีพ>อบกรอบ แต่จะพอให้อ่านว่า เกษตร-กรอบ-กรอบ มันก็ไม่เป็นจริงได้พอๆกับ เกษตรกร-อบ-กรอบ
เกษตรกร จากราชบัณฑิต(ถึงแม้ช่วงนี้จะดราม่าเรื่องความน่าเชื่อถือบ่อย) หมายถึง ผู้ทำงานในที่ดินหรือที่นา
แต่วลีนี้ผมไม่ได้คิดเองครับ เอามาจากขายหัวเราะหรือมหาสนุก มีตอนที่นางยักษ์ผีเสื้อสมุทรเอาเกษตรกรไปอบกรอบเพราะนึกว่าเป็นการทำผลิตภัณฑ์ OTOP ที่ถูกต้อง
กรอบกรอบ แปลประมาณว่าจนกรอบก็ได้ครับ
ตอบแบบนี้ครับ
ผมลองของ spicydog ได้
คุณ|บ็อต|บอก|ว่า|วันนี้|พิมพ์|ไม่|ผิด|แต่|ตัด|แบบ|นี้|จะ|ดี|เหรอ| |คณะกรรมการ|การ|เลือกตั้ง|กรมวิทยาศาสตร์การแพทย์| |เขา|นอน|ตาก|ลม|ตาก|ลม|ไปมา
ดูแล้วสาย M/C learning คงต้องมีฐานข้อมูลเยอะพอตัวถึงจะตัดคำได้เป๊ะๆ
บล็อกส่วนตัวที่อัพเดตตามอารมณ์และความขยัน :P
M/C learning ก็เหมือนคนครับ ต้องใช้เวลาในการเรียนรู้ แต่สามารถเรียนต่อไปเรื่อยๆ ได้ ก็เก่งขึ้นเรื่อยๆ ได้
M/C learning ไม่เหมือนคนครับ ทำสำเนาได้ จากรุ่นสู่รุ่นไม่ต้องมาเริ่มต้นเรียนใหม่ ถ่ายทอดกันได้แปบบเป๊ะๆ
ผมมองว่า deep learning น่าจะเพิ่มความยืดหยุ่นได้มากกว่าการทำแบบ statistics ทั่วไปครับ ดังนั้นถ้ามีกฎการตัดคำที่ตายตัว + สามารถเข้าไปร่วมกันสร้าง corpus ที่ดีได้ + ประกอบคำที่ไม่รู้จักจากไวยากรณ์ได้บ้าง ถึงจุดนั้นเราก็คงมีตัวตัดคำรุ่น ultimate ให้ใช้กัน ผมว่ามันใกล้เข้ามาละ เป็นกำลังใจให้ทุกทีม :)
SPICYDOG's Blog
แต่ผลอันนี้ดีมากนะครับ ดีกว่า libthai ใน Ubuntu 16.04 ที่ผมใช้
lewcpe.com, @wasonliw
เมืองไทยก็ยังอยู่กับตัดคำไทย 555
แค่ตัดคำได้ทุกต้องทุกพยางค์ในภาษาไทยคุณก็อาจได้โนเบิลแล้วนะครับ เพราะหมายความว่า ML ุณเข้าใจความหมายของคำแล้วสามารถเข้าในบรบทของทำทุกอย่าง คุยภาษาคนรู้เรื่องได้เลยแหละ
ขอแนะนำให้อ่านความยากลำบากจากโพสของคุณปรัชญาครับ NLP ไทย ไม่ไปไหนจริงหรือ?
SPICYDOG's Blog
เพราะภาษาไทยต้องรู้โครงสร้างประโยคก่อนจึงตัดได้ครับ
ภาษาอังกฤษเองทุกวันนี้เรื่องโครงสร้างประโยคเขายังทำ 100% ไม่ได้เลย
ในแง่ของการ "ไปไหน" ทุกวันนี้ตัดถูกเกิน 95% นี่เรื่องปกติแล้ว ก็ถือว่าไกลพอสมควรแล้วนะครับ ถ้านับพวกท้ายบรรทัดนี่จะตัดผิดอาจจะต้องมองหลายๆ หน้าเจอทีนึง
lewcpe.com, @wasonliw
เป็นไปได้หรือเปล่า ที่เราจะพัฒนาภาษาไทยให้เข้ากับยุค (เหมือนที่จีนแผ่นดินใหญ่ ปรับภาษาจีนดั้งเดิมเป็นตัวย่อเพื่อให้พัฒนาในด้านต่างๆได้ง่าย) เช่น เขียนคำเว้นวรรคแบบประโยคภาษาอังกฤษ(หรือที่เคยเรียนในสมัย มานี ชูใจ) "วันนี้ ฉัน กิน ข้าว กับ คุณตา" เป็นต้นครับ มันน่าจะง่ายขึ้นสำหรับชาวต่างชาติที่จะเรียนรู้ และการพัฒนาโปรแกรม ถ้าจำไม่ผิดภาษาอังกฤษก็เคยเขียนติดกันมาก่อนก่อนจะพัฒนาเป็นแยกแบบนี้
ก็ไม่เห็นจำเป็นจะต้องเว้นวรรคแบบนี้เลยครับ จีน ญี่ปุ่นยังไม่เว้นเลย
ภาษาไทยมีรูปสระเป็นตัวแยกคำอยู่แล้ว ถ้าไม่นับกรณีสระลดรูป หนึ่งคำหนึ่งรูปสระอยู่แล้ว ดังนั้นไม่จำเป็นต้องเขียนเว้นก็ได้ครับ แต่ในกรณีภาษาอังกฤษใช้ตัวอักษรมาเป็นสระด้วยจึงต้องเว้นคำ ตัวอย่างเช่น "จีนแผ่นดินใหญ่" คุณไม่สามารถแยกเป็น (จี นแ ผ่ดิ นใ หญ่)ได้ เป็นต้น
ผมเคยพัฒนาไว้ สามารถกรองประโยค คำหยาบ หรือคำวิบัติได้ และแยกแยะประโยค ว่าเป็น ปฏิเสธ บอกเล่า คำถาม หรืออื่นๆ เป็น php ทำเมื่อสองปีก่อน เดี๋ยวว่างๆ ผมจะนั่งทำเล่นๆต่อยอดจากของเดิม จะได้พัฒนาระบบของคนไทยให้มันดีขึ้น
อันนี้อีกอัน
cutkum https://github.com/pucktada/cutkum
ความแม่นยำต่ำกว่านิดหน่อย RNN บน tensorflow
น่าจะส่งเข้าไปเป็นส่วนนึงของระบบตัดคำบน browser นะครับ ตัดคำกันเหนื่อยใจมากๆ
ได้ข่าวว่ามีคนเคยขอข้อมูลพจนานุกรมจากเว็บราชบัณฑิตย์ เพื่อใช้ในงานพัฒนาระบบตัดคำ และเดาคำ แต่ราชบัณฑิตย์ บอกว่าไม่สามารถให้ข้อมูลพจนานุกรมได้เพราะกลัวเอาข้อมูลไปทำอะไรมิดีมิร้าย แต่ราชบัณฑิตย์เองที่มีข้อมูลอยู่กลับไม่สามารถทำประโยชน์จากข้อมูลที่มีได้เลย เฮ้ออออออ
การเมืองเยอะครับ เราคงต้องอาศัยแกนนำสักคนทำ crowdsourcing ใช้ร่วมกัน
SPICYDOG's Blog
เอาประโยคนั้นมาให้คนตัด คนยังงงเลยคับ 555
สุดยอดครับ
แต่จะให้ดีกว่านี้ True ควรใช้ data scientist มาแก้ปัญหาในเชิง operation ที่สำคัญๆด้วยครับ
อย่างใช้ DL ทำ CRM ให้ดีเท่าคู่แข่ง หรือปัญหาอื่นๆที่หลายๆคนชอบบ่นกัน