สรุปความจากการบรรยายหัวข้อ MLOps: Productionizing Machine Learning at Scale โดยคุณทัศพล อธิอภิญญา Advanced Machine Learning Engineer จากบริษัท กสิกร บิสซิเนส-เทคโนโลยี กรุ๊ป หรือ KBTG
คุณทัศพลเคยเป็นวิศวกรคนไทยในสหรัฐอเมริกามาก่อน เคยทำงานกับ HortonWorks, VMware และร่วมทีม Siri ใน Apple ที่สำนักงานใหญ่ (อ่านบทสัมภาษณ์คุณทัศพล สมัยทำงานที่ HortonWorks)

Machine Learning ไม่ใช่แค่การทำโมเดล
เวลาเราพูดถึง AI เรามักพูดถึง machine learning (ML) และ data science ซึ่งมีความเกี่ยวข้องกัน โดย Data Science จะใช้หรือไม่ใช้ ML ก็ได้
ML คือการตัดสินใจด้วยข้อมูล ไม่ใช่การตัดสินใจด้วยโค้ดเหมือนซอฟต์แวร์ทั่วไป และเทคนิคของ ML มีมากมาย ตัวอย่างที่ได้ยินกันบ่อยๆ เช่น linear regression, logistics regression, deep learning
ทุกวันนี้ทุกองค์กรอยากนำ ML มาใช้งาน แต่ตัวเลขของ Gartner ระบุว่า 85% ของโครงการ AI & Big Data ล้มเหลว ไม่สามารถออกจากแล็บมาใช้งานในเชิงพาณิชย์ได้ เหตุผลคืออะไร?
เวลาเราพูดถึง Machine Learning เรามักพูดกันแค่เรื่องการทำโมเดล แต่ในทางปฏิบัติแล้ว ยังมีประเด็นอื่นๆ อีกมาก ตั้งแต่การตีโจทย์ธุรกิจ การทำความสะอาดข้อมูล การตรวจสอบยืนยันความถูกต้องของโมเดล ฯลฯ ซึ่งกระบวนการทั้งหมดเราเรียกว่า MLOps หรือ Machine Learning Operation ซึ่งเป็นศัพท์ที่ไมโครซอฟท์และกูเกิลใช้
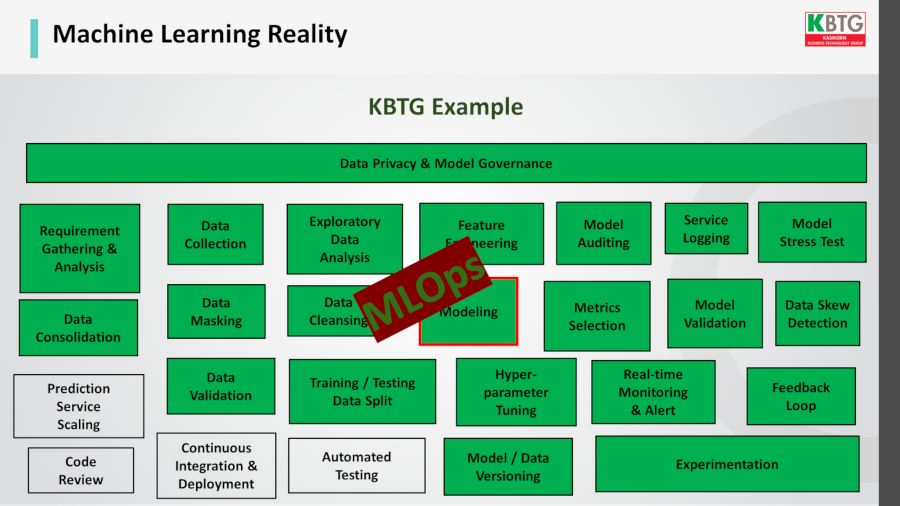
MLOps เป็นการทำงานร่วมกันระหว่าง data scientist กับฝ่ายอื่นๆ เพื่อทำให้การทำโมเดลยกระดับจากการเป็นแค่ต้นแบบ (prototype) ไปสู่การใช้งานจริง (production)
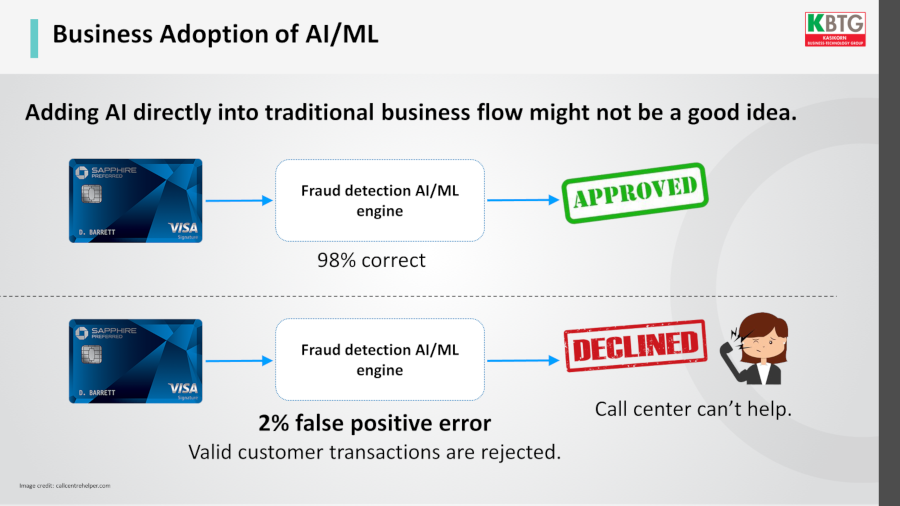
การนำ ML มาใช้ในกระบวนการธุรกิจแบบเดิมทันที อาจไม่ใช่ทางออกที่เหมาะสม เพราะหลักการของ ML คือความน่าจะเป็น ไม่มีทางถูกต้อง 100% ตัวอย่างคือการใช้ ML ช่วยตรวจจับการโกงบัตรเครดิต ถึงแม้โมเดลถูกต้อง 98% แต่หากเข้าเคส 2% ที่เหลือ เราเป็นเจ้าของบัตรเครดิตใบนั้นจริง แต่ถูกระบบมองว่าโกง พอโทรเข้าคอลล์เซ็นเตอร์ หากคอลล์เซ็นเตอร์บอกว่าช่วยอะไรไม่ได้ เพราะโมเดลตัดสินใจแบบนั้นไปแล้ว เราเองก็คงไม่พอใจ
ทางออกที่ดีกว่าคือหาวิธีที่เปลี่ยนการตัดสินใจของ AI ได้ เช่น ถ้าเราเข้าข่าย 2% ที่มีปัญหา ระบบจะมีทางออกให้เรา โดยส่งอีเมลมาถามว่าเราเป็นคนใช้บัตรเครดิตนั้นจริงหรือไม่ หรือคอลล์เซ็นเตอร์อาจเปลี่ยนการตัดสินใจของ AI กลับมาเป็น approve ได้
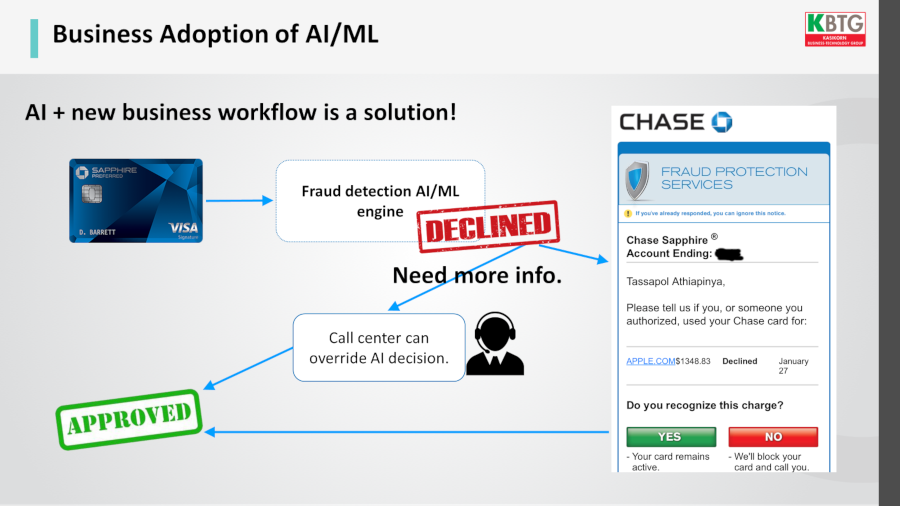
ดังนั้นการนำ AI เข้ามาใช้งาน เราจำเป็นต้องปรับเปลี่ยนกระบวนการของธุรกิจไปด้วย เพื่อให้ได้ประโยชน์ทั้งในแง่การลดต้นทุนจาก AI และการสร้างประสบการณ์ที่ดีของลูกค้า
AI ไม่ใช่แค่การเขียนโค้ด
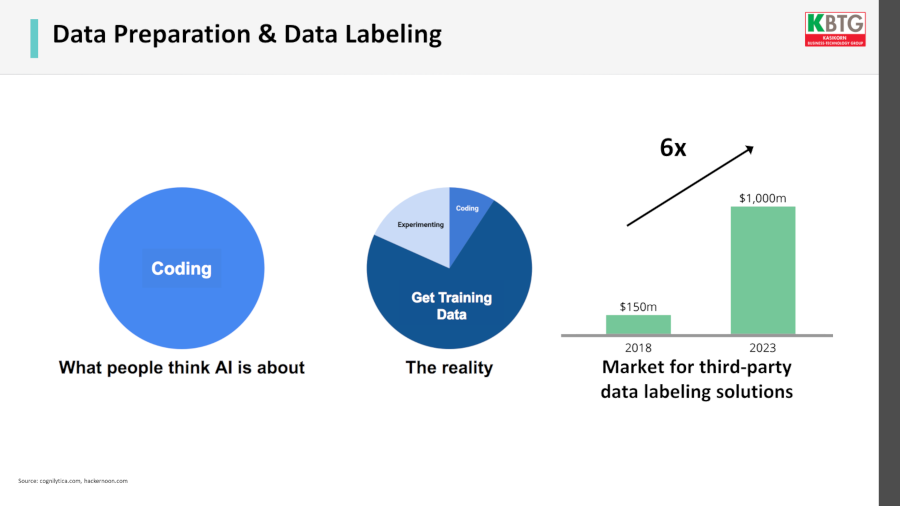
เวลาพูดว่าทำงานด้าน AI คนทั่วไปมักนึกว่างานหลักคือโค้ดดิ้ง แต่ในความเป็นจริงแล้วงานที่เสียเวลามากที่สุดคือการเตรียมข้อมูล เรื่องนี้เป็นปัญหาหนักมาก จนในต่างประเทศมีธุรกิจรับจ้างทำ label ให้ข้อมูลแล้ว ซึ่งนักวิเคราะห์ก็มองกันว่าธุรกิจนี้จะเติบโตขึ้นไปอีกเยอะมาก เพราะทุกคนที่ทำ AI ประสบปัญหานี้
พอได้ข้อมูลมาแล้ว data scientist ที่มีประสบการณ์จะลองนำมาพล็อตกราฟหรือทำ data visualization ดูว่า ข้อมูลที่มีนั้นสามารถใช้งานได้จริงหรือเปล่า ก่อนเริ่มลงมือทำโมเดล
การนำ AI มาพยากรณ์ยังมีประเด็นเรื่องความผิดพลาดแบบ false negative หรือ false positive อยู่เสมอ ซึ่งในมุมของ data scientist เพียงลำพังคงไม่สามารถตัดสินใจได้ว่า ยอมให้เกิด false negative หรือ false positive แบบไหนดีกว่ากัน ตรงนี้ data scientist ต้องทำงานร่วมกับฝั่งธุรกิจ เพื่อหาเป้าหมายที่ชัดเจน จากนั้นค่อยไปลงมือทำโมเดล

เลือกใช้โมเดลให้ถูกกับงาน ไม่มีโมเดลที่ครอบจักรวาล
โมเดลของ ML ก็มีให้เลือกหลายแบบ ต้องเลือกให้ถูกกับงาน ตัวอย่างเช่น การประเมินราคาอสังหาริมทรัพย์ควรใช้ linear regression แต่ถ้าเป็นงานด้านประมวลผลภาษาธรรมชาติ (NLP) มักใช้ neural network หรือถ้าเป็นการจัดกลุ่มของข้อมูล (auto-tagging) ใช้ clustering algorithm

Model overfitting คือสถานการณ์ที่โมเดลของเราทำงานได้ดีมากกับข้อมูลที่ใช้เทรน แต่พอมีข้อมูลใหม่เข้ามาที่ไม่เคยเทรนมาก่อน กลับทำงานผิดพลาด ไม่สามารถขยายไปทำงานทั่วไป (generalized)
Model understanding เราต้องเข้าใจว่าโมเดลทำงานได้อย่างไรด้วย ไม่ใช่แค่ดูผลลัพธ์ของโมเดลว่าทำงานได้มีประสิทธิภาพสูงเพียงอย่างเดียว กรณีล่าสุดของปัญหานี้คือโมเดลของ YouTube เข้าใจผิด มองว่าคลิปหุ่นยนต์ต่อสู้กันเป็นการทารุณสัตว์ และลบคลิปนี้ออก จนกูเกิลต้องออกมาขอโทษที่ผิดพลาด
ประสบการณ์ของ KBTG พบว่าโมเดลที่แม่นยำมากกว่า ไม่ได้แปลว่าดีกว่าเสมอไป หลายครั้งเราเลือกโมเดลที่แม่นยำน้อยกว่า แต่อธิบายหรือทำความเข้าใจได้ง่ายกว่า เพราะถ้าเกิดปัญหาอะไรขึ้นมา จะได้อธิบายให้ลูกค้าฟังได้
ML คือการทดลอง ต้องทดลองตลอดเวลา และมีเครื่องมือจัดการที่เหมาะสม
ในวงการ AI มีคำว่า “ML Superhero” ซึ่งหมายถึงคนที่เก่งเรื่องนี้มากๆ ระดับว่าทำโมเดลเอง เขียนซอฟต์แวร์เอง เก็บข้อมูลเอง แต่ปัญหาที่พบคือ ถ้าคนคนนี้ไปทำงานอื่นนานๆ แล้วกลับมาดูโค้ดตัวเอง จะจำไม่ได้ว่าทำอะไรไว้ ซึ่งไม่เป็นผลดีกับทีม เพราะแปลว่า ML ที่รันอยู่ใน production จะไม่มีใครสามารถดูแลแก้ไขมันได้
ปัญหานี้ทำให้เกิดแนวทางที่เรียกว่า ML Dashboard เอาไว้เก็บล็อกว่าคนในทีมคนไหนทดลอง (experiment) อะไรไป ด้วยพารามีเตอร์อะไร ได้ผลอย่างไร เพื่อให้ทุกคนในทีมเข้ามาดูและค้นหาข้อมูลได้ว่าเคยทำอะไรไว้ ตรงนี้ KBTG ก็ลองนำมาใช้แล้ว โดยเป็นซอฟต์แวร์โอเพนซอร์สชื่อ MLflow
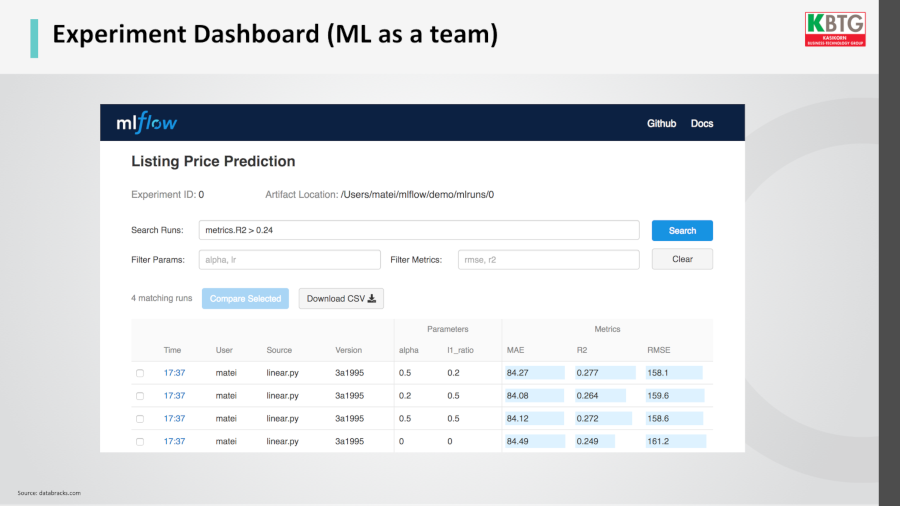
แนวทางนี้มีใช้งานกันในบริษัทใหญ่ๆ เช่น Uber มีแพลตฟอร์มลักษณะเดียวกันชื่อ Michelangelo เก็บเวลา เก็บพาธ เก็บเวอร์ชันของโมเดล เพื่อให้จัดการได้ง่ายขึ้น
Netflix เป็นอีกบริษัทที่นำ ML มาใช้เยอะ ไปไกลถึงขั้นทำ A/B Testing กับตัวโมเดลที่ใช้ใน production เลย สังเกตได้ว่าหนังที่ Netflix แนะนำมาให้เราในแต่ละครั้งมักไม่เหมือนกัน เพราะเป็นการทำ A/B Testing เปรียบเทียบว่าโมเดลไหนมีประสิทธิภาพดีกว่านั่นเอง
KBTG ก็ทำ A/B Testing กับโมเดลเช่นกัน โดยเฉพาะการให้สินเชื่อ โดยทดลองเปรียบเทียบระหว่างการใช้โมเดล ML กับการใช้ decision tree แบบเก่า ว่าแนวทางไหนมีประสิทธิภาพดีกว่า โดยไม่เพิ่มความเสี่ยงให้กับธนาคาร
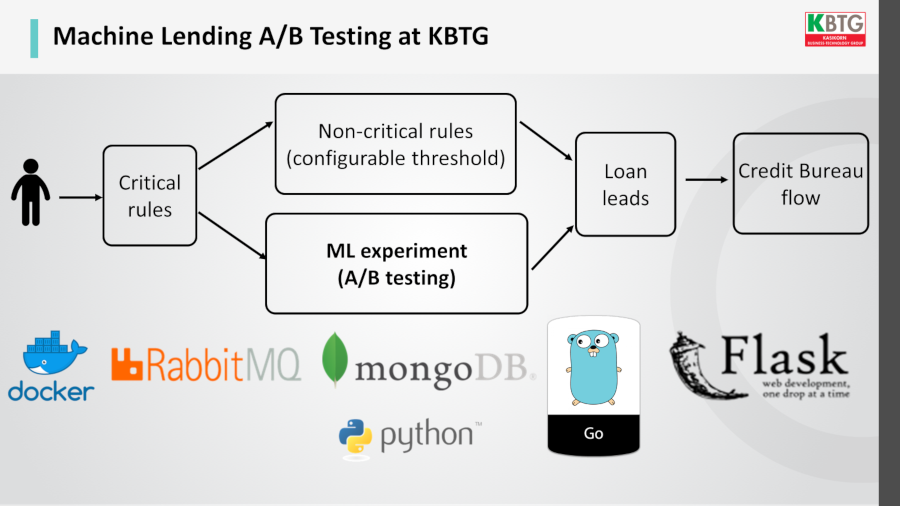
ปัจจัยที่ต้องพิจารณาในการทดลองโมเดลมี 3 อย่างคือ โค้ด (code) ข้อมูล (data) และสภาพแวดล้อม (environment) ต่างจากซอฟต์แวร์ทั่วไปที่มีเฉพาะเรื่องโค้ดเพียงอย่างเดียว โดยสภาพแวดล้อมคือปัจจัยอื่นๆ ที่อยู่รอบข้างทั้งหมด ที่ไม่ใช่โค้ดและข้อมูล
ตัวอย่างโครงการ AI ที่ล้มเหลวคือ Google Flu Trends ที่กูเกิลพยายามนำข้อมูลการค้นหา (search) มาพยากรณ์ว่าเกิดโรคไข้หวัดใหญ่ระบาดหรือไม่ ผลคือการพยากรณ์ผิดไปมาก เหตุผลหลักเป็นเพราะระหว่างทาง กูเกิลมีการปรับอันดับของผลการค้นหาอยู่ตลอดเวลา ทำให้การพยากรณ์ผิดพลาด เนื่องจากตัวสภาพแวดล้อมเปลี่ยนนั่นเอง

ML ในเชิงวิศวกรรม
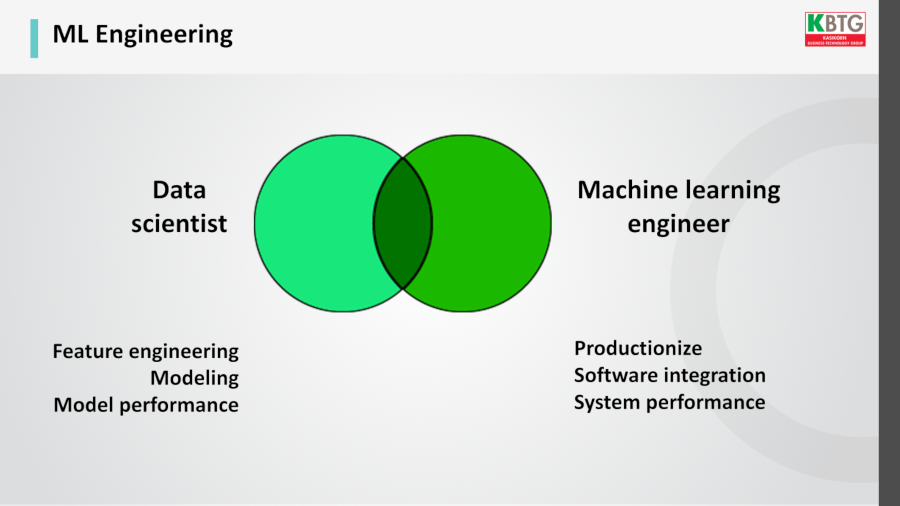
เมื่อพูดถึง ML เรามักพูดถึงอาชีพ data scientist แต่ในความเป็นจริงแล้วยังต้องมีตำแหน่งที่เรียกว่า machine learning engineer มาทำงานควบคู่กันไปด้วย ต้องมีงานที่ทักษะต่างกัน 2 แบบในทีม
หน้าที่ของ data scientist คือการทำโมเดลที่แม่นยำ
ส่วนหน้าที่ของ machine learning engineer คือต้องเข้าใจโมเดล และสามารถนำโมเดลไปใช้ทำงานร่วมกับซอฟต์แวร์อื่นๆ ได้อย่างมีประสิทธิภาพ ไม่ใช่รันโมเดลแล้วทำงานช้าลง
ในโลกของซอฟต์แวร์แบบเดิม หากซอฟต์แวร์มีบั๊ก ก็ทำงานผิดพลาดให้เห็นชัดเจน แต่ในโลกของ ML ถ้ามันทำงานผิดพลาด มักไม่มีใครมองเห็น (silent failure) เพราะพยากรณ์พลาดก็ไม่มีใครดูออก ไม่มีการแจ้ง error บอก แต่ผลเสียจริงๆ คือทุกครั้งที่พยากรณ์ผิด ก็เสียโอกาสทางธุรกิจไปเสมอ
วิธีการแก้ไขก็ไม่มีวิธีที่ตรงไปตรงมา ในเอกสารวิจัยของกูเกิลบอกว่าเราต้องมีระบบที่คอยเฝ้าดู (monitor) ว่าข้อมูลที่เราเทรน กับข้อมูลที่ใช้จริงๆ มีโครงสร้างหรือการกระจายตัวที่แตกต่างกันแค่ไหน หรือต้องมี action limits คือดูจำนวนครั้งของการกระทำบางอย่างว่าเยอะผิดปกติหรือไม่ แล้วแจ้งเตือนบอกให้ทีมทราบ
ประเด็นเหล่านี้เป็นสิ่งที่เพิ่งเกิดขึ้นมาพร้อมกับโลกของ ML ซึ่งในโลกของซอฟต์แวร์ปกติ เราไม่ค่อยเคยทำกัน
แนวปฏิบัติในการทำ MLOps ที่เหมาะสม
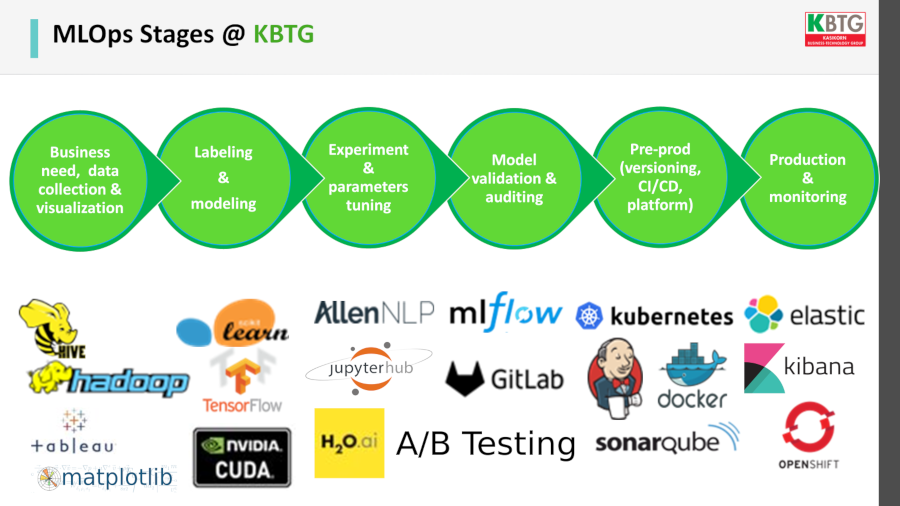
ตัวอย่างของ MLOps ใน KBTG สรุปมาได้เป็นแผนภาพ เริ่มจากการตีโจทย์ทางธุรกิจให้ชัด เก็บข้อมูล ทำป้ายข้อมูล และที่สำคัญต้องทำ model validation ตรวจสอบว่าโมเดลนั้นเวิร์คจริงไหม จากนั้นจึงเข้าส่วนของการนำไปใช้งาน และมอนิเตอร์ผลลัพธ์
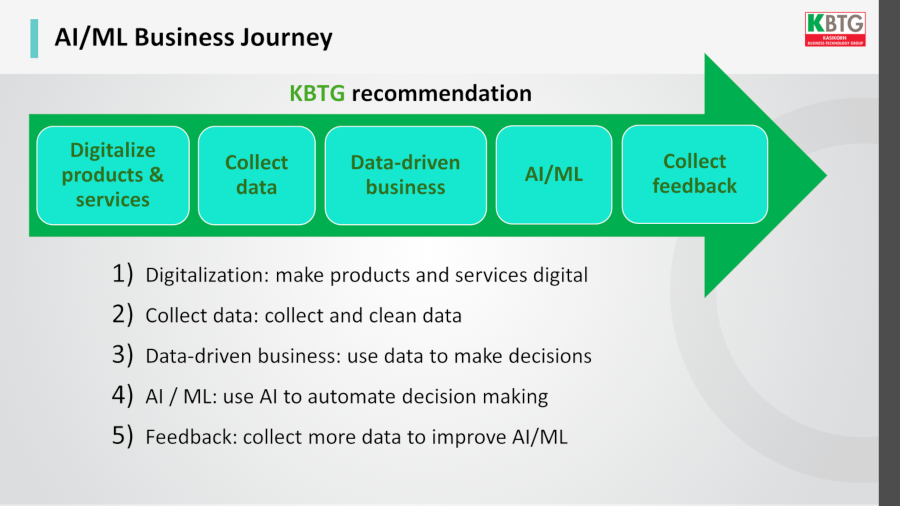
หากเป็นองค์กรที่ไม่เคยใช้ machine learning มาก่อนเลย ควรทำอย่างไรดี ทุกองค์กรสามารถใช้ประโยชน์ของ machine learning ได้หมด โดยคำแนะนำคือแบ่งกระบวนการออกเป็น 5 ขั้นตอน
- ปรับธุรกิจ สินค้าและบริการให้เป็นดิจิทัลให้มากที่สุด
- เริ่มต้นเก็บข้อมูล และทำความสะอาดข้อมูลให้พร้อมใช้
- ปรับวัฒนธรรมองค์กรให้ตัดสินใจด้วยข้อมูล (data-driven decision)
- นำเทคนิค AI/ML มาใช้งานให้สามารถตัดสินใจเชิงธุรกิจได้อย่างอัตโนมัติ (automate decision making)
- วัดผลลัพธ์เพื่อนำไปปรับปรุง AI/ML ให้แม่นยำยิ่งขึ้น
คลิปการบรรยายของคุณทัศพล อธิอภิญญา ในงาน Blognone Tomorrow 2019
ข้อมูลอ้างอิง
- MLOps: Manage, deploy, and monitor models with azure machine learning service
- YouTube. ML Ops Best Practices on Google Cloud (Cloud Next ’19) [Online; accessed 27-June-2019]
- Martin Zinkevich. Rules of machine learning: Best practices for ml engineering.
- David Sculley, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, and Michael Young. Machine learning: The high interest credit card of technical debt. 2014.

Get latest news from Blognone
Follow @twitterapi
Hiring! บริษัทที่น่าสนใจ



Cloudnone
- AWS มาไทย ย้ายเลยดีไหม อะไรยังมาไม่ครบบ้าง? | Cloudnone Ep. 23
- NVIDIA จะไปหยุดที่ตรงไหน ทำไมครองโลกดาต้าเซ็นเตอร์ | Cloudnone EP.22
- ถึงคลาวด์เคราะห์: ทำอย่างไรเมื่อบริการคลาวด์ที่ใช้ถูกยกเลิก | Cloudnone EP. 21
- รู้จักอาชีพ Site Reliability Engineer สำคัญยังไง? | Cloudnone EP. 20
- อธิบาย CrowdStrike ทางเทคนิค ทำไมถึงทำพีซีจอฟ้าเป็นล้านๆ เครื่อง | Cloudnone EP.19
Comments
Wow...
การทำโมเดล Generalize ยากจริงๆ ครับ
และเดต้าที่น้อยทำให้เราคิดว่าเลข Accuracy มันบ่งบอกว่าโมเดลดีจริงๆ หรือไม่ ได้น้อยมาก
มือใหม่!! ใหม่จริงๆนะ
อ้าว Google Flu Trends นี่เคยเห็นคนเขียนบทความชื่นชมอยู่เลย ตกลงเฟลเหรอเนี่ย
เทคโนโลยีไม่ผิด คนใช้มันในทางที่ผิดนั่นแหละที่ผิด!?!
สุดยอครับ
เป็น session ที่ดีอันนึงครับ อันอื่นหลาย session นี่เน้นแต่ขายของ