By: lew 


 on 23 June 2020 - 22:38
Tags:
on 23 June 2020 - 22:38
Tags:
Topics:

สถาบันวิจัยปัญญาประดิษฐ์ประเทศไทย (VISTEC-depa Thailand Artificial Intelligence Research Institute) ปล่อยโมเดล deep learning แบบ Transformer ที่ฝึกด้วย toolkitfairseq ของเฟซบุ๊ก ที่ฝึกกับชุดข้อมูลแปลภาษาไทย-อังกฤษมาแล้ว 1 ล้านคู่ประโยค พร้อมปล่อยชุดข้อมูล โดยได้คะแนน BLEU เหนือกว่า Google Translate API
ทางสถาบันสร้างชุดข้อมูลโดยอาศัยทั้งการจ้างนักแปลโดยตรง, จ้างจากแพลตฟอร์ม crowdsourcing, ใช้นักแปลตรวจสอบการแปลของ Google Translate API, ไปจนถึงเอกสารที่มีการแปลอยู่แล้ว เช่น เอกสารราชการหรือวิกิพีเดีย
โมเดล Transformer เป็นโมเดลที่กูเกิลเสนอไว้ตั้งแต่ปี 2017 และโมเดลในกลุ่มนี้ยังคงเป็นกลุ่มที่มีความแม่นยำสูงสุด ทางสถาบันวิจัยปัญญาประดิษฐ์ใช้โมเดล Transformer แบบพื้นฐานขนาด 74 ล้านพารามิเตอร์ แล้วทดสอบคะแนนด้วยชุดข้อมูล IWSLT 2015 จำนวน 4,242 ประโยค สร้างโมเดลแปลที่ความแม่นยำตามคะแนน BLEU สูงขึ้นกว่าเดิม โดยก่อนหน้านี้ทางสถาบันเคยใช้ชุดข้อมูล OPUS ขนาด 5.4 ล้านประโยคในการสร้างปัญญาประดิษฐ์แบบเดียวกันมาก่อนแล้ว

Get latest news from Blognone
Follow @twitterapi



Comments
ถ้าประเทศไทย มี dataset เยอะพอ จะได้วิจัย AI ได้ก้าวหน้า แข่งกับต่างประเทศได้ครับ.
ทรัพยากรต้องอยู่ในระดับ "พอไหว" ด้วยครับ โมเดล deep learning เดี๋ยวนี้ใหญ่เกินการ์ดจอ consumer ไปไกล (น่าจะเป็นความตั้งใจของ NVIDIA ที่อั้นแรมไว้) เจอโมเดลใหม่ๆ นี่เทรนทำซ้ำยังไม่ไปเลย
อย่างเคสนี้ของทางสถาบันก็ใช้ DGX-1 มารันได้ ตามมหาวิทยาลัยนี่ก็อาจจะต้องจัดหา Tesla/Quadro แรมเยอะๆ มาให้นักวิจัยใช้งานกันได้สะดวกๆ หน่อย
lewcpe.com, @wasonliw
ผมว่า Nvidia ไม่ได้อั้นแรมหรอกครับ แต่ลูกค้าขาดเงินมากกว่า ถ้ามีเงินก็บอก Nvidia ไปว่าจะเอาแรมเท่าไร เงินถึง ผมว่ายังไงเค้าก็ผลิตให้ครับ
งานนี้เราใช้ V100 ในการเทรนไม่ใช่ DGX-1 แต่โมเดล transformers-base นี้เทรนด้วย GPU ฟรีของ Google Colab หรือ Kaggle ได้ครับ ถ้าในระดับประมาณ 5 ล้านคู่ประโยคเท่าที่เรามีอยู่
data ผมว่ามีอยู่แล้ว แต่น่าจะขาดคนรวบรวม วิเคราะห์ และนำมาใช้ ส่วนหนึ่งต้องยอมรับว่า ทำไปก็ไม่ได้เงิน ทำไปขายได้แค่ตลาดเล็ก ๆ ในประเทศ ได้แต่ใช้เอง ทำไปตลาดต่างประเทศก็ไม่สนใจผลงานของเรา เทคโนโลยีจากประเทศไทย vs เทคโนโลยีจากสหรัฐอเมริกา อืม..แค่ฟังชื่อความรู้สึกก็ต่างกันแล้วครับ มวยรองถ้าจะชนะต้องเอาถึงขั้นน็อคครับ สูสียังไงก็แพ้ แต่ว่ากันเป็นขั้น เอาให้พึ่งพาตัวเองได้ก่อน เพราะตอนนี้อะไร ๆ เราก็ใช้ของนอกครับ แค่ทำเว็บยังใช้ framework เมืองนอกทั้งนั้น
framework มัน opensource ไม่มีประเทศหรอกครับ ใครอยาก contribute ก็ช่วยกัน contribute เข้าไป
ต้องมีดาต้าถึงจะขับเคลื่อนไปได้ 555
มือใหม่!! ใหม่จริงๆนะ
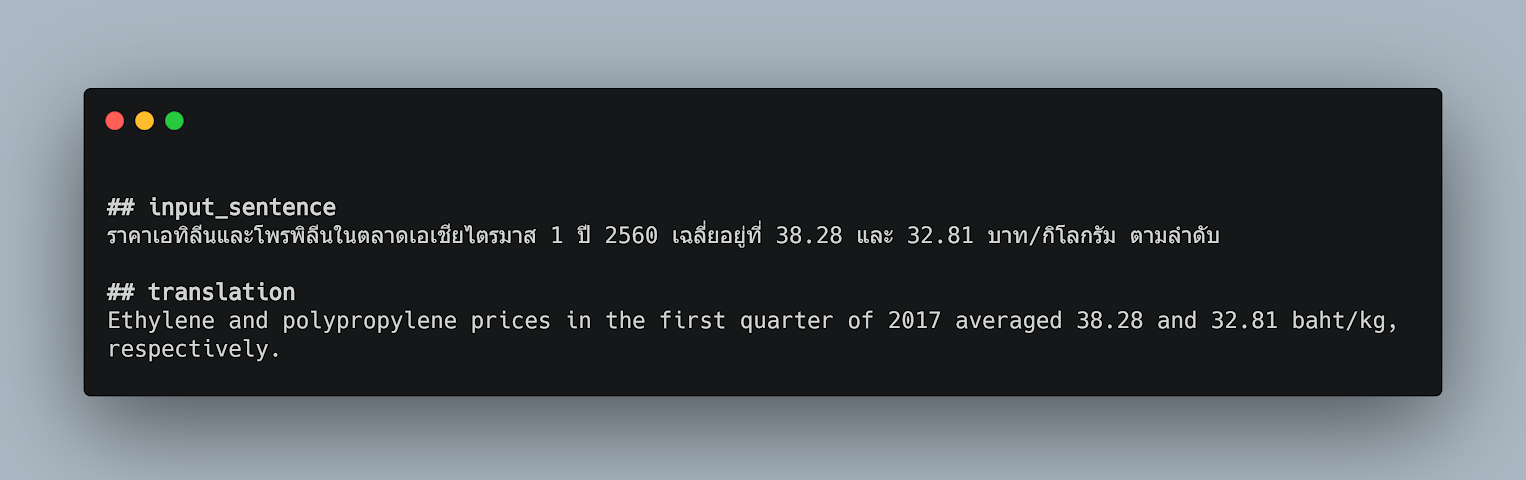
ในรูปนั่นแปลตกใช่ไหม
ตลาดเอเชียหายไปไหนเลย
พึ่งรู้ว่ามีสถาบันแบบนี้ในไทยด้วย
เพิ่งก่อตั้งและให้ทุนโดย ปตท เหมือนจะมีแต่ Graduated School รวมอาจารย์เก่งๆ นักศึกษาเก่งๆไว้เยอะอยู่ครับเท่าที่ได้ข่าว คล้ายๆโรงเรียนกำเนิดวิทย์ซึ่งตอนนี้บางคนบอกว่าดีกว่ามหิดลวิทยานุสรณ์อีกเข้ายากมาก
เฉพาะการแปลคำไม่ใช่สิ่งที่ยากมากนัก แต่การจัดเรียงคำเป็นรูปประโยคสิยาก อย่างตัวอย่างในภาพ การวางตำแหน่งคำยังแปลกๆอยู่
ถ้าแบบไม่มีความรู้ด้านนี้ว่า ยังไม่ได้ให้ user ทั่วไปใช้ใช่ไหมครับ
แบบว่าโหลดมาเปิดในโปรแกรม python แล้วลอง run ดูได้เลย
ลองได้ครับ
จาก link ต้นทาง
กดเข้าไปแล้ว Copy to Drive
จากนั้นเลือก Runtime->Run all ก่อน 1 ครั้งเพื่อติดตั้งแพคเกจและโหลดโมเดล
ลองเปลี่ยน input_sentence แล้วกด run cell นั้นได้เลย
ขอบคุณครับ ลองแปะประโยคสั้นๆดูก็ยังมีแปลแปลกๆแต่ก็โอเคนะครับ เดี๋ยวค่อยลองไปเรื่อยๆ
Chelsea confirm Willian and Pedro have signed short-term contracts to stay until the end of the season.
แปลว่า
Chelsea ยืนยัน Musa และ Pedro ได้ลงนามในสัญญาระยะสั้นที่จะอยู่จนกระทั่งสิ้นสุดฤดูกาล
อยากได้โมเดล OCR อ่ะมีแจกไหมหว่าตอนนี้OCR ภาษาไทยที่หายนะจริงๆจับภาพมาอ่านแล้วอิหยังวะตลอด
ทางสถาบันวิจัยกำลังทำอยู่ครับ รวมถึง speech recognition ด้วยครับ
บล็อก: wannaphong.com และ Python 3
มีข้อแม้ว่าต้องพูดภาษากลางใช่มั้ย 555