By: mk 
 on 7 April 2022 - 08:24
Tags:
on 7 April 2022 - 08:24
Tags:

Google Cloud เปิดตัวบริการฐานข้อมูลแบบใหม่ BigLakes มันคือการขยายร่าง Google BigQuery ให้มาใช้กับข้อมูลประเภท object storage ได้ด้วย เท่ากับว่าใช้คำสั่งและอินเทอร์เฟซแบบ BigQuery ได้กับทั้งข้อมูลแบบดั้งเดิม (database/data warehouse) และข้อมูลแบบวัตถุ (data lake)
Gerrit Kazmaier ผู้บริหารฝ่ายฐานข้อมูลของ Google Cloud บอกว่าในโลกฐานข้อมูล มีเส้นแบ่งระหว่าง data base กับ data lake มายาวนาน เหตุผลคือข้อมูลประเภทใหม่ๆ มีจำนวนเพิ่มขึ้นเร็วมาก จนไม่สามารถจัดการด้วยวิธีแบบดั้งเดิม (database) ไหว จึงต้องมีการจัดการแบบ data warehouse (structured) และ data lake (unstructured) ขึ้นมารับมือ
แต่การแยกข้อมูลเก็บใน data lake ก็มีปัญหาตามมา เพราะแยกส่วน (silo) จากข้อมูลแบบ database เดิมอย่างชัดเจน มีวิธีการจัดการที่แตกต่างกัน
Google BigLake แก้ปัญหานี้ด้วยการรวม data warehouse และ data lake เข้ามาด้วยกัน จัดการข้อมูลและวิเคราะห์ได้จากที่เดียว ไม่ต้องทำสำเนาซ้ำหรือย้ายที่เก็บข้อมูลก่อนให้เปลืองเวลา-ต้นทุน ในแง่การจัดการใช้ BigQuery API ที่ใช้กันแพร่หลายอยู่แล้วได้ทันที
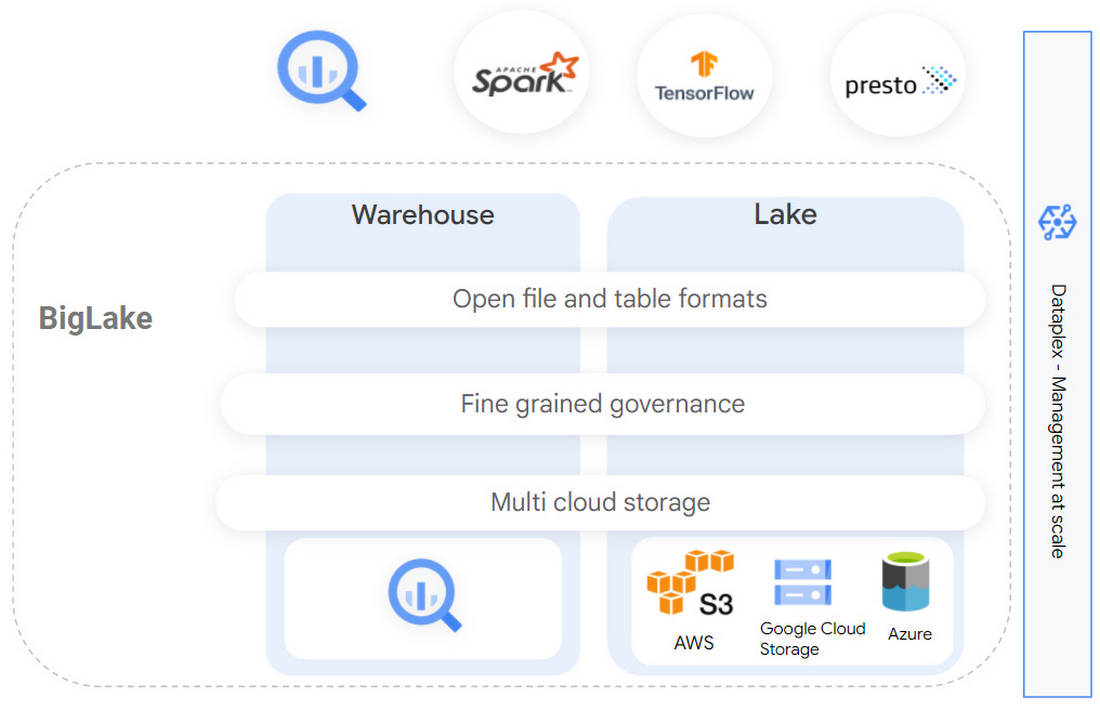

รูปแบบข้อมูลที่ BigLake รองรับ มีทั้ง Google Cloud Storage ของกูเกิลเอง, Amazon S3 และ Azure Data Lake Storage Gen2 (ผ่าน BigQuery Omni) ฟอร์แมตของตารางที่รองรับมี 5 แบบคือ Parquet, ORC, Avro, JSON, CSV แล้วสามารถนำไปวิเคราะห์ข้อมูลต่อด้วย Apache Spark, TensorFlow, Presto ได้
ตอนนี้ BigLake ยังมีสถานะเป็นพรีวิว วิธีคิดเงินมี 2 แบบคือ on-demand เท่าที่ใช้งาน (1TB แรกฟรี) และ flat-rate เหมาจ่ายเป็นรายเดือน-ปี
ที่มา - Google, Google, The Next Platform

Get latest news from Blognone
Follow @twitterapi


