By: mk 
 on 11 July 2022 - 20:29
Tags:
on 11 July 2022 - 20:29
Tags:
Topics:

อินเทลเป็นบริษัทที่เปลี่ยนผ่านตัวเองได้อย่างน่าสนใจในช่วงประมาณ 2 ปีที่ผ่านมา ตั้งแต่การประกาศยุทธศาสตร์ใหม่ IDM 2.0 เปิดโรงงานรับจ้างผลิตชิปให้คนนอก และไลน์อัพสินค้าใหม่ที่เปลี่ยนแปลงไปจากเดิมหลายอย่าง บทความนี้จะสรุปแนวทางของอินเทลยุคใหม่ที่เปิดกว้างมากขึ้น ยืดหยุ่นกว่าเดิม ตัวซีพียูไม่จำกัดตัวเองแค่ x86 อีกต่อไป และฝั่งโรงงานผลิตชิปก็ไม่ได้แข่งแต่เรื่องนาโนเมตรเพียงอย่างเดียวอีกแล้ว
บทความนี้เป็นภาคต่อของบทความชุด เกิดอะไรขึ้นที่อินเทล, ตอนที่ 2, ตอนที่ 3 ที่เขียนไว้ช่วงต้นปี 2021 โดยเป็นการอัพเดตความคืบหน้าว่าหลังจากเวลาผ่านมาราวปีครึ่ง อินเทลปรับยุทธศาสตร์ตัวเองไปอย่างไรบ้าง และเรากำลังจะได้เห็นอะไรจากอินเทลบ้างในอีก 2-3 ปีข้างหน้า

การเปลี่ยนแปลงของอินเทลสามารถสรุปได้เป็น 3 เรื่องใหญ่ๆ คือ สถาปัตยกรรมหน่วยประมวลผล (Architecture), กระบวนการผลิตชิป (Process) และเทคโนโลยีการทำแพ็กเกจจิ้งชิป (Packaging)
1) สถาปัตยกรรม: ไม่ใช่แค่ x86 แต่รองรับ Arm และ RISC-V
เมื่อพูดถึงคำว่า "อินเทล" สิ่งที่ผูกพันกันมายาวนานคือสถาปัตยกรรมซีพียูแบบ x86 ที่สร้างอินเทลให้ยิ่งใหญ่มาจนถึงทุกวันนี้
ในรอบประมาณ 30 ปีที่ผ่านมา เราเห็นสถาปัตยกรรม x86 ไล่โค่นสถาปัตยกรรมคู่แข่งให้ล้มหายตายจากไปนับไม่ถ้วน ไม่ว่าจะเป็น Power (IBM), Alpha (DEC) หรือ SPARC (Sun/Oracle) ในโลกเซิร์ฟเวอร์ หรือ MIPS กับ PowerPC (IBM) ในเครื่องเกมคอนโซล และแม้กระทั่งในบริษัทตัวเอง เราก็เห็น x86 เอาชนะสถาปัตยกรรม Itanium กลายเป็นผู้อยู่รอดได้เพียงรายเดียวของบริษัท
แต่ในโลกยุคที่การประมวลผลเปลี่ยนแปลงไปจากเดิม เราเห็นการรุ่งขึ้นมาของหน่วยประมวลผลแบบใหม่ๆ เช่น การเติบโตของจีพียูในฐานะตัวเร่งการประมวลผล (accelerator) สำหรับงานแบบเวกเตอร์ (กราฟิกและ AI) และการเติบโตของสถาปัตยกรรม Arm ในแง่ประสิทธิภาพขึ้นมาทัดเทียมกับ x86 โดยยังคงจุดเด่นเรื่องการประหยัดพลังงานไว้ได้
อินเทลในรอบ 10 ปีที่ผ่านมา เพลี่ยงพล้ำทั้งในตลาดจีพียู (ที่นำโดย NVIDIA) และตลาดอุปกรณ์พกพา (ที่ครองโดย Arm) จนหลายคนอาจมองว่าถึงจุดสิ้นสุดของ x86 แล้ว เพราะไม่สามารถขยายกินแดนได้เพิ่ม (Atom ล้มเหลวในตลาดมือถือ) แถมยังสูญเสียพื้นที่เดิมของตัวเอง (เช่น เสียตลาดโน้ตบุ๊กแอปเปิลให้ Arm)

อย่างไรก็ตาม อินเทลยุคใหม่หลังเปลี่ยนตัวซีอีโอมาเป็น Pat Gelsinger (จริงๆ ต้องบอกว่าอินเทลเริ่มเปลี่ยนมาก่อนหน้านั้นมาสักพักแล้ว) มีทิศทางที่เปิดกว้างขึ้นมาก เช่น การเปิดโรงงานของตัวเองให้ลูกค้ารายอื่น (รวมถึงคู่แข่ง) เข้ามาใช้งาน และในแง่สถาปัตยกรรมหน่วยประมวลผล อินเทลก็ทำในสิ่งที่เราไม่เคยเห็นกันมาก่อน นั่นคือเปิดให้มีสถาปัตยกรรมอื่นที่ไม่ใช่ x86 มาอยู่บนชิปแผ่นเดียวกับ x86 ได้ด้วย
ในธุรกิจรับจ้างผลิตชิปของอินเทล (Intel Foundry Service หรือ IFS) ลูกค้าสามารถระบุประเภทชิปที่ต้องการได้ หากเป็นชิปสถาปัตยกรรม Arm ลูกค้าสามารถซื้อแบบพิมพ์เขียวจากบริษัท Arm ได้โดยตรงอยู่แล้ว (แล้วค่อยมาจ้างอินเทล ซัมซุง หรือ TSMC ผลิต ดังที่ Qualcomm และ Amazon ประกาศทำแล้ว) แต่ในฝั่งของรักของหวง x86 เราก็เพิ่งเห็นข่าว อินเทลจะเปิดให้ลูกค้าคัสตอมชิป Xeon ได้เอง ซึ่งเป็นสิ่งที่ไม่มีใครคิดว่าจะเกิดขึ้นได้เมื่อ 5 ปีก่อน
นอกจาก Arm และ x86 แล้ว อินเทลยังให้ความสนใจสถาปัตยกรรมใหม่อย่าง RISC-V โดยเข้าไปลงทุนในบริษัท SiFive ที่ทำชิป RISC-V รวมถึงออกชิปสถาปัตยกรรม RISC-V ของตัวเอง (แม้ยังไม่ใช่ชิปสำคัญมาก)
ในภาพรวมคือเราเห็นโรงงานของอินเทลรองรับสถาปัตยกรรมซีพียู 3 แบบคือ x86, Arm, RISC-V ลูกค้ามีความต้องการแบบไหนก็ยินดีต้อนรับทุกแบบ

ที่มาภาพ - Intel
ด้านชิปที่เป็นสินค้าของอินเทลเอง เราอาจยังไม่ได้เห็นซีพียูประเภทอื่นนอกจาก x86 ในเร็ววัน แต่เราเริ่มเห็นการผนวกตัวช่วยประมวลผล (co-processor หรือ accelerator) ประเภทอื่นเข้ามาแล้ว ทั้งจีพียูที่ใช้สถาปัตยกรรม Xe ของตัวเอง (รอบนี้ดูเหมือนจะทำสำเร็จแล้วสักที) และ FPGA ที่ได้มาจากการซื้อ Altera เมื่อปี 2015 ตอนนี้เราเห็นสินค้าจริงอย่าง Xeon รุ่นปี 2020 ที่ฝัง FGPA มาให้ในตัวมาช่วยรันงาน AI หรือ ชิปเครือข่าย IPU ที่ฝัง FGPA มาช่วยประมวลผลทราฟฟิกขั้นต้น
อินเทลเรียกแนวทางการใส่หน่วยประมวลผลชนิดอื่น (GPU, FPGA) เข้ามารวมกับซีพียูว่า XPU ซึ่งจะออกดอกออกผลเต็มที่ใน Xeon รุ่นปี 2024 โค้ดเนม Falcon Shores ที่รวมเอาซีพียูและจีพียูเข้ามาด้วยกัน (การเปลี่ยนแปลงจะเริ่มจากฝั่งเซิร์ฟเวอร์และคอมพิวเตอร์สมรรถนะสูงก่อน เพราะไม่มีข้อจำกัดเรื่องพื้นที่และพลังงาน)

 ที่มา - Intel YouTube
ที่มา - Intel YouTube

2) กระบวนการผลิต: ไล่คู่แข่งให้ทันด้วย Tick-Tock
อินเทลในยุคก่อนหน้านี้ เพลี่ยงพล้ำให้กับ TSMC และซัมซุงในแง่กระบวนการผลิตชิปที่เล็กและมีประสิทธิภาพ อินเทลติดหล่ม 14nm และไม่สามารถก้าวสู่ 10nm อยู่นานมาก จนโดนคู่แข่งแซงไปไกลมากแล้ว
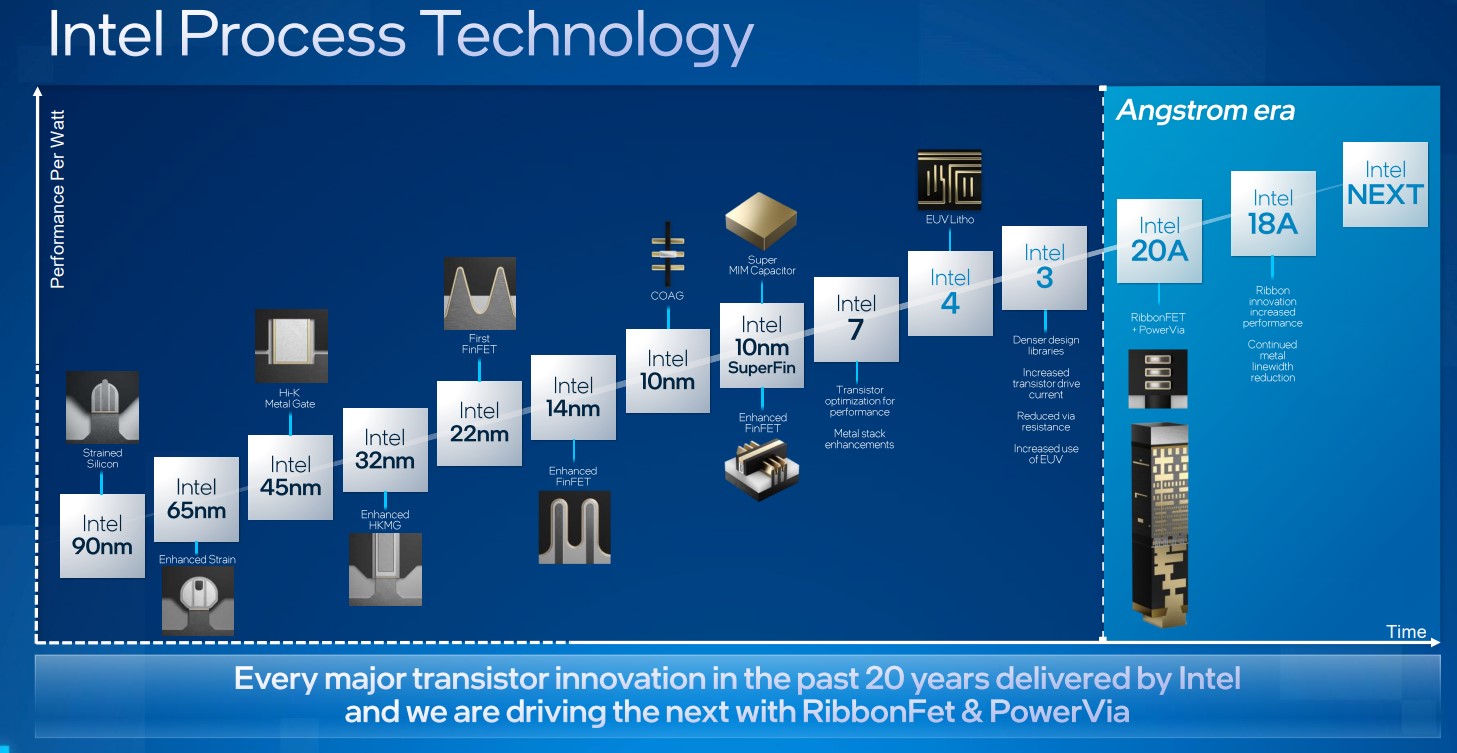
อินเทลเวอร์ชันใหม่ดูเหมือนแก้ปัญหาเรื่องกระบวนการผลิตไปได้พอสมควร และยังหาญกล้า ประกาศเร่งให้ทันคู่แข่งด้วยการขยับกระบวนการผลิตใหม่ทุกปี (ทำได้จริงแค่ไหนอีกเรื่องนึง)
 ที่มา - Intel
ที่มา - Intel
ยุทธศาสตร์ที่อินเทลจะนำมาเร่งให้ทันคู่แข่งในเรื่องกระบวนการผลิตคือชื่อที่คุ้นเคยอย่าง Tick-Tock
ปัญหาเดิมของอินเทลคือพยายามเปลี่ยนกระบวนการผลิตครั้งใหญ่ๆ ใส่ของใหม่ทุกอย่างมาพร้อมกันทีเดียวแล้วพัง (14nm → 10nm) รอบนี้อินเทลแก้เกมใหม่ เปลี่ยนเป็นการซอยรอบการเปลี่ยนรุ่นกระบวนการผลิตให้เล็กลง ทยอยเปลี่ยนเทคโนโลยีทีละชิ้น ถ้ามั่นใจว่าดีแล้วค่อยรีดประสิทธิภาพเทคโนโลยีเดิมในรอบถัดไป ดังที่เคยประสบความสำเร็จมาแล้วกับ Tick-Tock ยุคก่อน
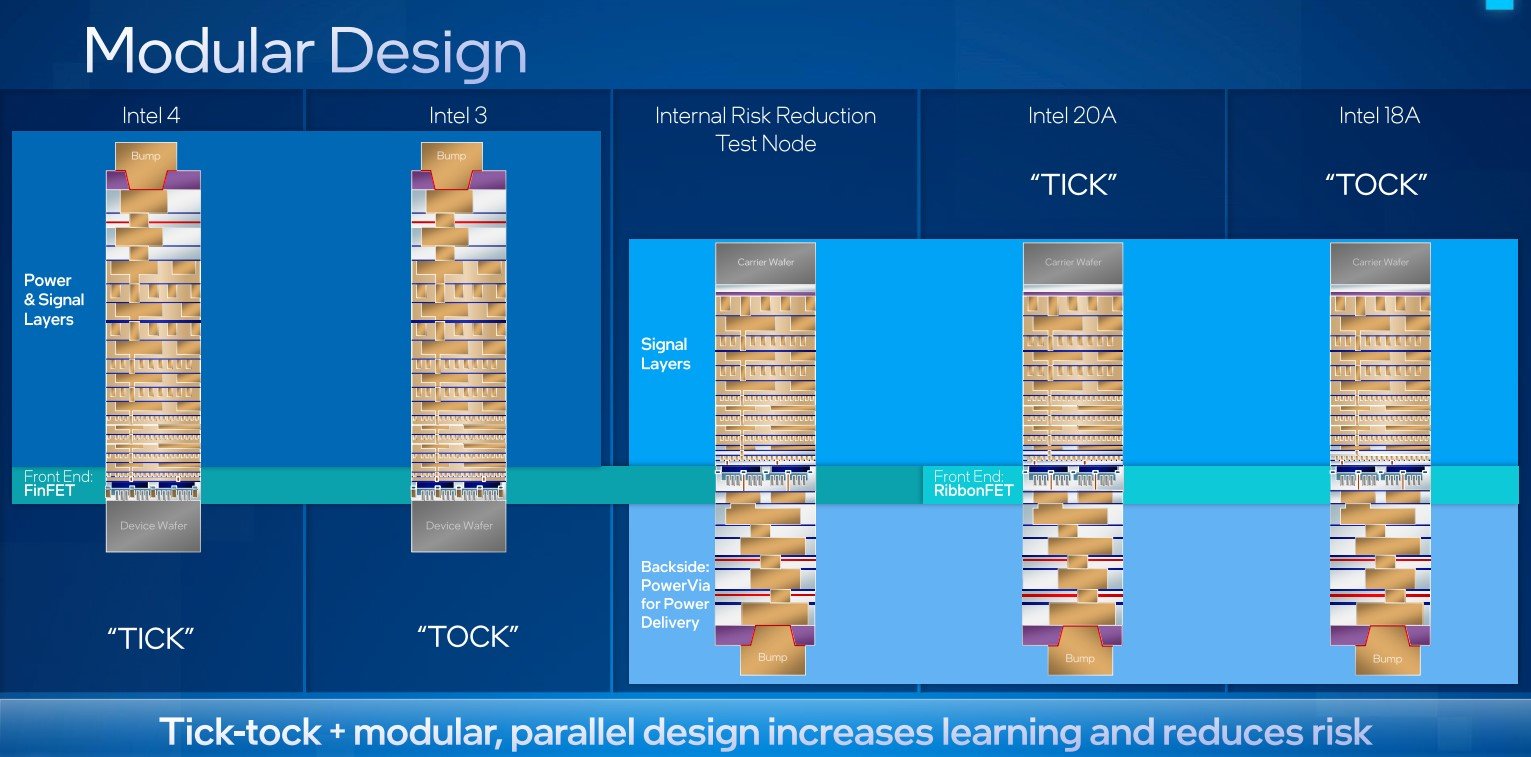
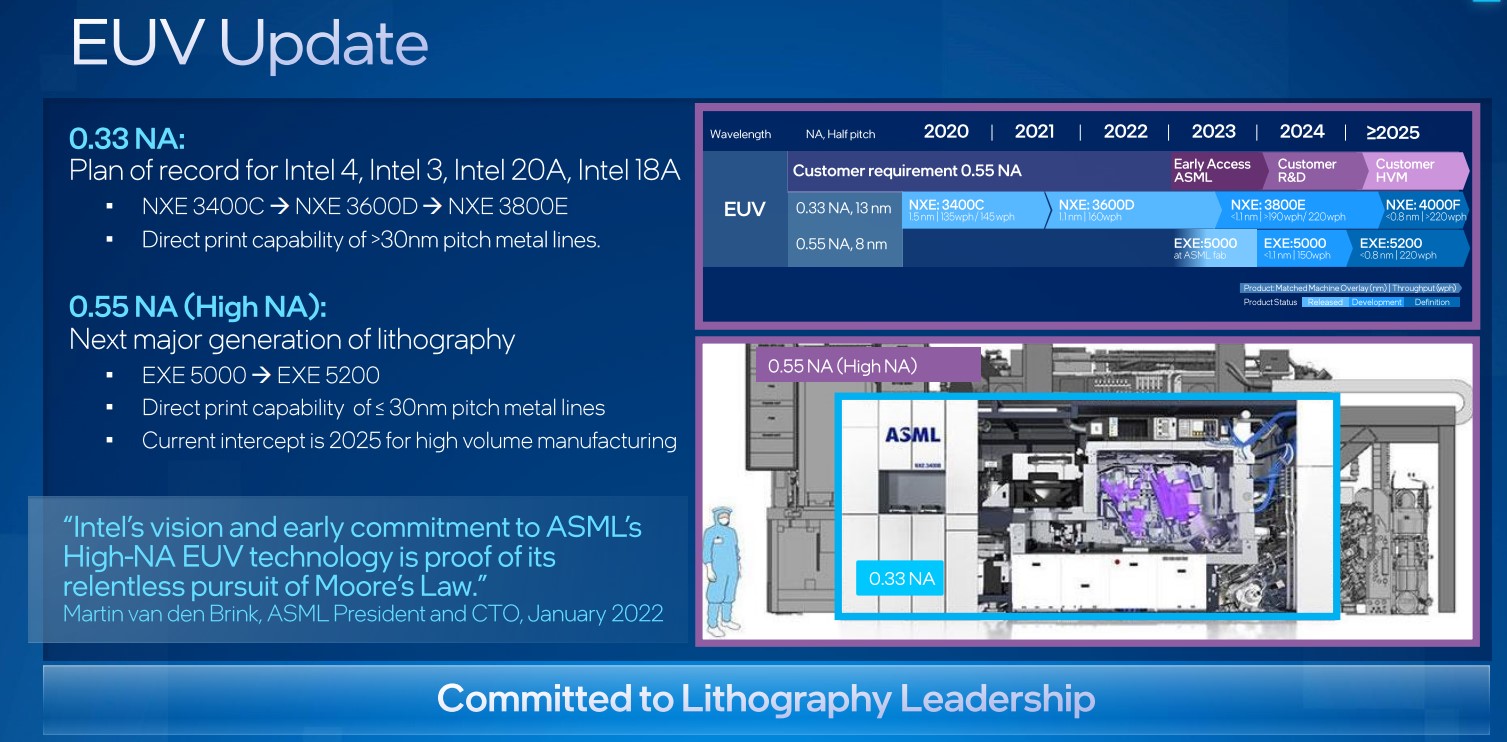
แผนการเปลี่ยนเทคโนโลยีการผลิตของอินเทลตามแนวทาง Tick-Tock จะมีจุดเปลี่ยนสำคัญ (Tick) คือ Intel 4 (7nm) ช่วงปลายปี 2022 นี้ จะเริ่มนำเอาเครื่อง EUV ของ ASML มาใช้เป็นครั้งแรก (ชาวบ้านเขาใช้กันไปนานแล้ว) จากนั้นค่อยรีดประสิทธิภาพของเทคโนโลยีใหม่บนกระบวนการ Intel 3 (7nm) ช่วงปลายปี 2023 (Tock)
อินเทลจะเปลี่ยนเทคโนโลยีใหญ่อีกรอบ (Tick) ในกระบวนการ Intel 20A ที่บอกว่าเริ่มเข้าสู่ยุคอังสตรอม โดยนำเทคนิคด้านการจ่ายกระแสไฟฟ้าของทรานซิสเตอร์ชื่อ RibbonFET (พัฒนาจาก FinFET ที่ใช้กันทุกวันนี้) และ PowerVia มาใช้ในช่วงต้นปี 2024 แล้วจึงรีดประสิทธิภาพอีกรอบในกระบวนการ Intel 18A ช่วงปลายปี 2024 (Tock)
ภาพเปรียบเทียบ FinFET และ RibbonFET ที่ใช้ขนาดทรานซิสเตอร์เล็กลง ในการจ่ายไฟเท่าเดิม

ภาพเปรียบเทียบทรานซิสเตอร์ปัจจุบัน ที่ผสมเส้นจ่ายไฟและสัญญาณเข้าด้วยกัน (ซ้าย) และ PowerVia ที่แยกส่วนจ่ายไฟไปไว้ด้านล่างของทรานซิสเตอร์ (ขวา)
 ที่มา - Intel
ที่มา - Intel
คลิปอธิบาย RibbonFET และ PowerVia
การใช้ EUV อาจเป็นสิ่งที่อินเทลไล่กวดให้ทันคู่แข่ง (technology parity) แต่ RibbonFET และ PoweVia เป็นเทคโนโลยีที่อินเทลพัฒนาเอง และหวังว่าจะช่วยให้อินเทลพลิกกลับมานำหน้าคู่แข่ง (technology leadership) ในแง่กระบวนการผลิตได้ในปี 2025 เป็นต้นไป
ตรงนี้คงต้องรอดูกันว่าอินเทลจะสำเร็จตามแผนหรือไม่ เพราะฝั่งของ TSMC และซัมซุงก็คงไม่นอนรออยู่เฉยๆ เช่นกัน
3) แพ็กเกจจิ้ง: EMIB และ Foveros
นอกจากการกระบวนการผลิตชิป (process) ที่อินเทลหวังเร่งด้วยยุทธศาสตร์ Tick-Tock และการใช้เทคนิคใหม่ๆ อย่าง RibbonFET และ PowerVia มาช่วยแล้ว อีกเรื่องที่อินเทลพูดถึงเยอะมากในช่วงหลังคือ เทคโนโลยีการทำแพ็กเกจจิ้งของชิป (chip packaging)
การผลิตชิปในยุคใหม่เริ่มหันมาสู่สถาปัตยกรรมแบบ modular มากขึ้น มีชิปหลายประเภทอยู่บนแผ่น die อันเดียวกัน แนวทางนี้บุกเบิกโดย AMD ที่ใช้ท่า chiplet มาตั้งแต่ยุค Ryzen และเป็นหนึ่งในปัจจัยสำคัญที่ทำให้ซีพียู Ryzen เอาชนะอินเทลได้ สามารถเพิ่มจำนวนคอร์ได้ดีกว่า
ที่ผ่านมา อินเทลใช้สถาปัตยกรรมแบบแข็งตัว ทุกอย่างรวมเป็นชิ้นเดียว (System on Chip) มานาน แต่เมื่อตลาดพิสูจน์แล้วว่าแนวทางนี้ไปต่อไม่ได้ อินเทลยุคใหม่ก็ต้องปรับตัว และเปลี่ยนตัวเองมาสู่ยุคที่เรียกว่า System on Package แทน (ทั้งอินเทลและ AMD กำลังร่วมกันวางมาตรฐานการเชื่อมต่อนี้ในชื่อ UCIe)
ตัวอย่างสินค้าของอินเทลที่ใช้แนวทางนี้ คือจีพียู Ponte Vecchio (ซึ่งจะกล่าวถึงต่อไป) และซีพียู Meteor Lake ที่จะออกในปี 2023 (น่าจะนับเป็น Gen 14) จะใช้สถาปัตยกรรมแบบ Tile Architecture ที่ยืดหยุ่นต่อการต่อจิ๊กซอชิปมากขึ้น
ที่มา - Intel
 ที่มา - Intel
ที่มา - Intel
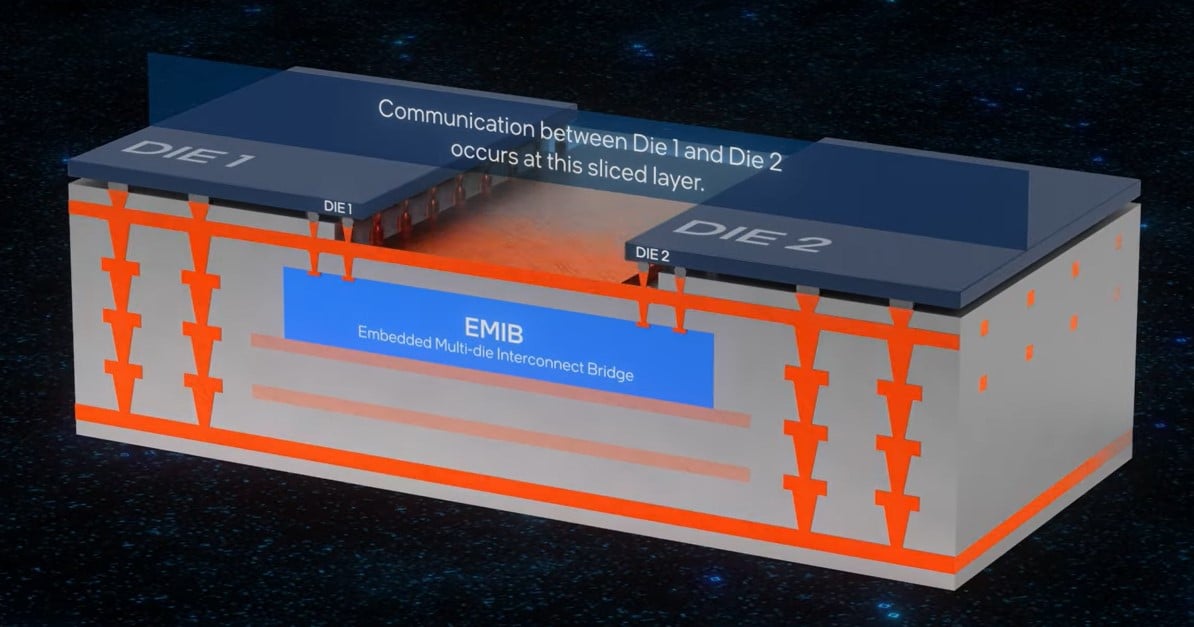
เทคโนโลยีที่อินเทลใช้เชื่อมต่อชิปหลายๆ ตัวเข้าด้วยกัน เรียกว่า "แพ็กเกจจิ้ง" โดยเทคโนโลยีสำคัญของอินเทลมี 2 ตัวคือ EMIB และ Foveros
ถ้าให้อธิบายแบบรวบรัด EMIB คือการเชื่อมต่อชิปในแนวนอน (2D scaling) ส่วน Foveros เป็นการเชื่อมต่อในแนวตั้ง (3D stacking)
 ที่มา - Intel
ที่มา - Intel
EMIB หรือชื่อเต็ม Embedded Multi-Die Interconnect Bridge เป็นเทคโนโลยีการเชื่อมต่อระหว่างชิปลูกแต่ละตัวในแนวนอน (2.5D)
การเชื่อมต่อระหว่างชิปไม่ใช่เรื่องใหม่ในอุตสาหกรรมชิป เทคนิคเดิมที่เคยใช้กันในปัจจุบัน คือการนำแผ่นซิลิคอนอีกแผ่นมาวางซ้อนข้างใต้ชิปลูกที่มาเชื่อมต่อกัน (silicon interposer) แล้วสร้างวงจรเชื่อมต่อในแผ่นซิลิคอนนั้น มีข้อเสียคือเปลืองพื้นที่ของแผ่นซิลิคอนโดยเปล่าประโยชน์ และไม่สามารถวางทับจุดเชื่อมต่อได้ครบ (ดูคลิปประกอบ)

EMIB เป็นเทคนิคคล้ายกับการขุดท่อระบายน้ำใต้แผ่นชิปอีกที ข้อดีคือใช้ซิลิคอนปริมาณน้อยกว่ามาก และอินเทลยังแยกชั้นของการส่งสัญญาณข้อมูล (สีน้ำเงิน) ออกจากการส่งพลังงานไฟฟ้า (สีแดง) ให้เป็นสัดส่วนไม่ปะปนกัน ช่วยให้ประสิทธิภาพดีกว่า
ปัจจุบัน EMIB ถูกนำมาใช้งานแล้วในชิปรุ่นใหม่ๆ อย่าง Alder Lake (Core 12th Gen) ตอนนี้อินเทลผลิต EMIB ที่ 55 micron และมีแผนขยับขนาดให้เล็กลงเหลือ 45 micron ในกระบวนการผลิตรอบ Intel 3
คลิปอธิบาย EMIB
Foveros เป็นเทคนิคการวางชิปซ้อนกันในแนวตั้ง (3D stacking) เพื่อให้การส่งข้อมูลระหว่างชิปมีระยะสั้นกว่าการวางแนวนอน มีกระแสไฟรั่วไหลน้อยลง
อินเทลเริ่มใช้เทคนิคการวางเรียงแนวตั้งในซีพียู Lakefield ที่ออกปี 2020 นับเป็น Foveros Gen 1 (50 micron) และพัฒนาต่อจนเป็น Foveros Gen 2 (36 micron) ซึ่งเราจะได้เห็นในซีพียู Meteor Lake ที่ออกในปีหน้า 2023
ภาพแสดง Foveros Gen 1 ของ Lakefield จะเห็นชิปสองชั้นคือ Compute Die ชั้นบน และ Base Die ชั้นล่าง
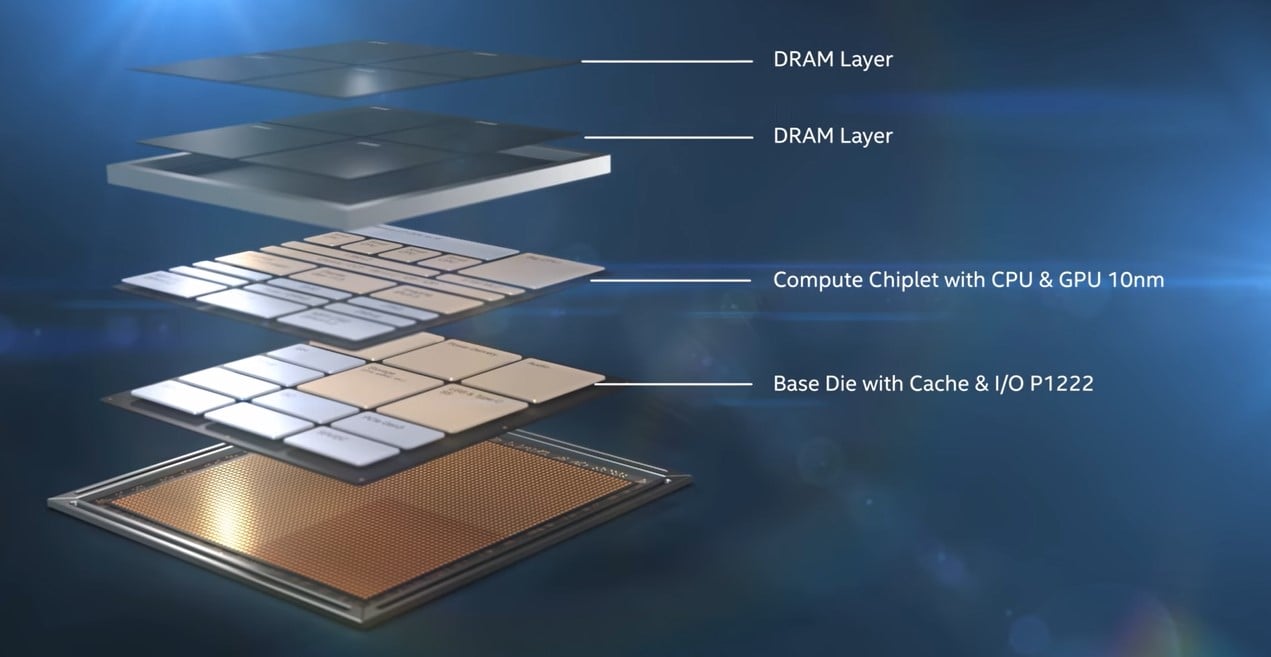 ที่มา - Intel YouTube
ที่มา - Intel YouTube
ภาพการวางชิปชั้นบน (สีดำ) ลงบนชิปชั้นล่าง (สีเทา) โดยขาเชื่อมต่อของชิปชั้นบนคือ Foveros ส่วนช่องสี่เหลี่ยมสีเหลืองในภาพคือ EMIB ที่เป็นการเชื่อมแนวนอน
ในระยะถัดไป อินเทลประกาศว่าจะพัฒนา Foveros ต่ออีก 2 ขั้นตอน ได้แก่ Foveros Omni และ Foveros Direct ซึ่งจะนำมาใช้พร้อมกันในช่วงปลายปี 2023
Foveros Omni เป็นเทคนิคการทำขาเชื่อมต่อให้รองรับการเชื่อมหลายทิศทาง (Omni-Directional Interconnect) เพื่อให้ชิปแผ่นบนสามารถใหญ่กว่าแผ่นล่างได้ และเปิดให้วางชิปสลับฟันปลาซ้อนกันได้ (Foveros Gen 2 จำกัดตรงที่แผ่นบนต้องเล็กกว่าแผ่นล่าง)
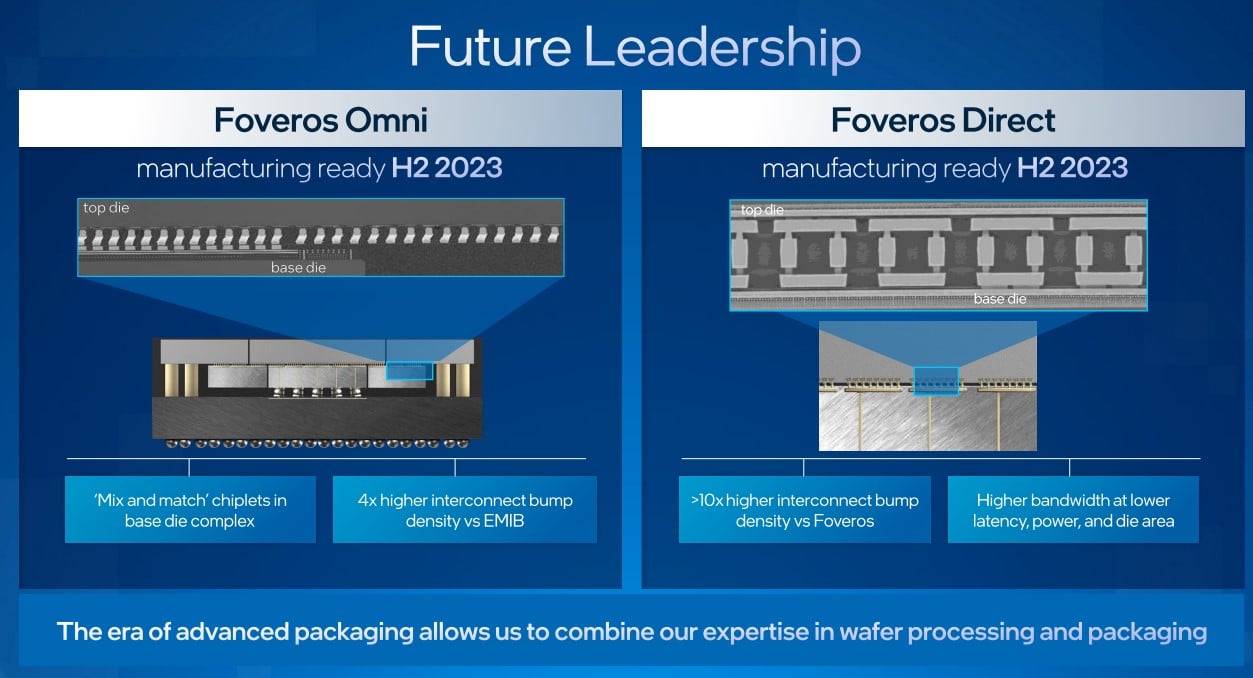
Foveros Direct เป็นอีกเทคนิคที่ทำให้ขาเชื่อมต่อมีขนาดเล็กลงกว่าเดิม (10 micron) เปลืองพื้นที่จุดเชื่อมต่อน้อยลง (วางขาได้ถี่ขึ้น)
ผู้สนใจสามารถอ่านรายละเอียดเรื่อง EMIB และ Foveros เพิ่มเติมได้จาก AnandTech
ผู้ผลิตชิปรายอื่นอย่าง TSMC ก็มีเทคนิคคล้ายๆ กับ Foveros ชื่อ 3DFabric แต่ดูไม่จริงจังมากเท่ากับอินเทลนัก (ส่วนหนึ่งเป็นเพราะอินเทลมีทั้งฝั่งออกแบบชิป และฝั่งผลิตในบริษัทเดียวกัน ประสานงานกันได้ดีกว่า)
ที่ผ่านมาเพิ่งมี AMD นำเทคโนโลยี 3DFabric ไปใช้งานเชื่อมแคช L3 ในแนวตั้ง และออกเป็นซีพียู Ryzen 7 5800X3D วางออกขายเมื่อเร็วๆ นี้
หากวิสัยทัศน์ของอินเทลถูกต้อง อินเทลอาจยังตามหลังในแง่ขนาดของการผลิต (Process) แต่เมื่อชิปยุคหน้าไม่ใช่ชิปใหญ่ตัวเดียว แต่เป็นชิปตัวเล็กๆ จำนวนมากมาเชื่อมต่อกัน อินเทลก็มั่นใจว่าเทคโนโลยีแพ็กเกจจิ้งของตัวเองที่ก้าวหน้ากว่า จะช่วยให้เอาชนะในตลาดนี้ได้

Ponte Vecchio จุดเริ่มต้นที่เชื่อมทุกอย่างเข้าด้วยกัน
จากที่กล่าวมาทั้งหมด จะเห็นว่าวิสัยทัศน์ของอินเทลยุคใหม่ประกอบด้วยแนวคิด 3 เรื่องคือ
- รองรับสถาปัตยกรรมที่หลากหลายขึ้น (Architecture)
- ปรับกระบวนการผลิตให้ทันคู่แข่ง (Process)
- นำเทคโนโลยีด้านแพ็กเกจจิ้งมาช่วย (Packaging) ให้เชื่อมต่อชิปได้หลากหลายขึ้น
ชิปยุคใหม่ของอินเทลที่จะบุกเบิกแนวคิดใหม่ทั้ง 3 เรื่องนี้ คือ จีพียูระดับเรือธงของอินเทล Ponte Vecchio ที่จะถูกนำมาใช้ในซูเปอร์คอมพิวเตอร์ Aurora ของกระทรวงพลังงานสหรัฐ มีกำหนดเสร็จช่วงปลายปี 2022 นี้
แกนหลักของ Ponte Vecchio คือแกนจีพียูสถาปัตยกรรม Xe ตัวเดียวกับที่ใช้ในโน้ตบุ๊กและเดสก์ท็อป เพื่อความเข้ากันได้ของซอฟต์แวร์ OneAPI ชุดเดียว จากนั้นเพิ่มด้วยฟีเจอร์ฮาร์ดแวร์ เช่น หน่วยความจำความเร็วสูง HBM2e, การเชื่อมต่อแบบ Xe Link
ในฝั่งของกระบวนการจัดแพ็กเกจชิป มันเป็นชิปตัวแรกที่ใช้ทั้ง EMIB และ Foveros ครบเซ็ต (จากภาพด้านล่างจะเห็น tile จำนวนมากมายที่วางซ้อนกัน)
 ที่มา - Intel
ที่มา - Intel
สิ่งที่อินเทลไปไกลกว่านั้นอีกคือ ชิปแต่ละชิ้นบนแพ็กเกจของ Ponte Vecchio มาจากคนละแหล่งผลิตกันด้วย โดยบางชิ้นเป็นอินเทลผลิตเองที่ 7nm แต่มีบางชิ้นที่ไปจ้างคู่แข่งคือ TSMC ผลิตให้ (ทั้ง 5nm และ 7nm ตามภาพ) สะท้อนให้เห็นว่า อินเทลยอมเสียศักดิ์ศรี (ที่กินไม่ได้) ไปใช้โรงงานของคู่แข่งที่ทำได้ดีกว่าตัวเองในตอนนี้

แม้ Ponte Vecchio มีแนวคิดก้าวหน้ามากมาย แต่แผนการของอินเทลยังไม่จบแค่นั้น เพราะชิป Ponte Vecchio เป็นแค่จีพียูอย่างเดียว ในการทำงานจริงยังต้องใช้ควบคู่กับซีพียูตระกูล Xeon อยู่
ขั้นถัดไป อินเทลจะออกจีพียู Rialto Bridge ที่ถือเป็นเวอร์ชันอัพเกรดของ Ponte Vecchio (บนสถาปัตยกรรมเดิม) ในปี 2023 หลังจากนั้นในปี 2024 ถึงเป็นของจริงคือชิป XPU ตัวแรก Falcon Shores ที่จะรวมซีพียู x86 กับจีพียู Xe เข้าด้วยกัน ชิปตัวนี้จะรวมทุกอย่างที่กล่าวมาในบทความนี้ คือเป็น XPU (CPU+GPU) ที่ใช้กระบวนการผลิตระดับอังสตรอม และใช้แพ็กเกจจิ้งแบบใหม่ๆ ของอินเทลทั้งหมด

อนาคตของอินเทล: ฟิวชั่นเสริมพลัง 2 ฝั่งธุรกิจ
ในงานประชุมนักลงทุนของอินเทลเมื่อต้นปี 2022 Raja Koduri หัวหน้าฝ่ายจีพียูของอินเทล ได้โชว์แผนผังวิธีคิดของอินเทลยุคใหม่
ผมคิดว่าแผนภาพนี้รวบยอดให้เราเห็นภาพใหญ่ว่า อินเทลกำลังคิดและทำอะไรบ้าง
- กระบวนการผลิตชิป แบบ 2 ขา คือ ทำของตัวเองให้ดี แต่ถ้ายังไม่ดี ก็ไม่ฝืนทน ไปจ้าง TSMC ได้
- เทคโนโลยีแพ็กเกจจิ้ง ทั้ง EMIB และ Foveros ทั้งหลาย
- สถาปัตยกรรม ฝั่งซีพียูแยก P-core และ E-core บวกด้วยจีพียู Xe มุ่งสู่โลก XPU
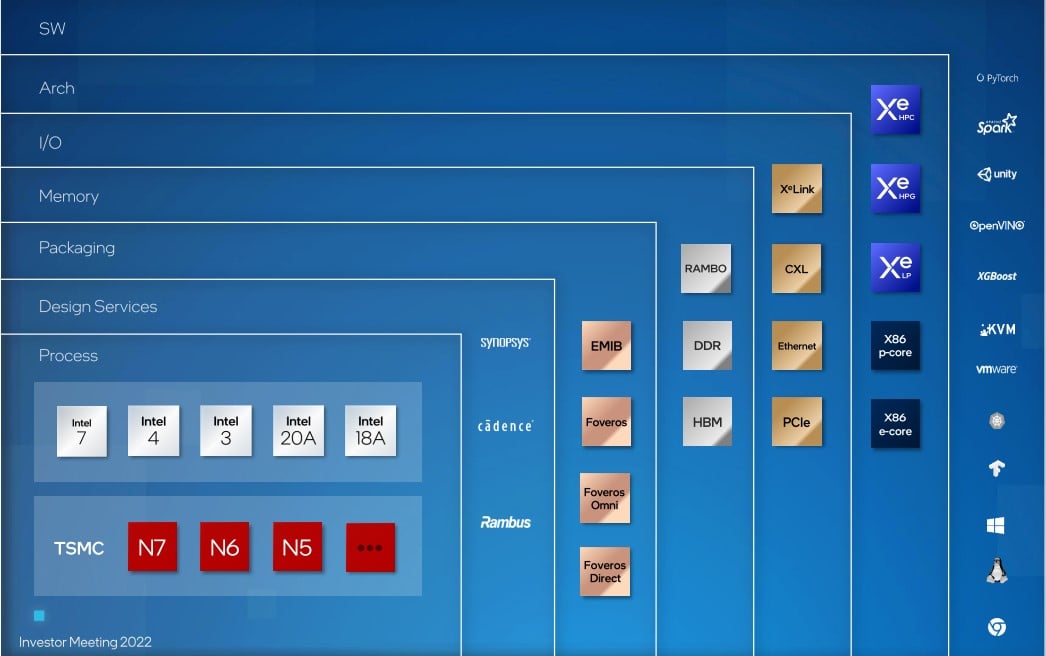 ที่มา - Intel
ที่มา - Intel
การต่อจิ๊กซอของอินเทลน่าสนใจมากทีเดียว จุดต่างของอินเทลจากคู่แข่งอย่างมากคือ อินเทลเป็นบริษัทเดียวที่มีทั้งฝั่งออกแบบซีพียูและฝั่งผลิตซีพียูครบในตัว (integrated device manufacturing หรือ IDM) ต่างจากคู่แข่งผู้ผลิตชิป AMD/NVIDIA ที่ต้องไปประกอบร่างกับโรงงาน TSMC/ซัมซุงเสมอ
นโยบาย IDM เคยเป็นจุดแข็ง (ยุค 2000s ที่ไม่มีใครไล่ทัน) แล้วกลับกลายเป็นจุดอ่อน (ยุค 2010s ที่ติดหล่ม 14nm) แต่หลังจากอินเทลเริ่มปรับตัวเป็น IDM 2.0 ที่เปิดกว้างมากขึ้น ยืดหยุ่นต่อโลกมากขึ้น การที่อินเทลมีทั้งสองขา หากประสานงานกันดีๆ กลับไปได้เร็วกว่า
- อินเทลฝั่งออกแบบ ยืดหยุ่นขึ้นด้วยการแยก P-core และ E-core ให้แยกส่วนกัน เพิ่มจำนวนคอร์สู้ AMD ได้, แก้เกมจนตอนนี้มีจีพียูของตัวเองแล้ว แถมใช้ได้ตั้งแต่โน้ตบุ๊กไปจนถึงซูเปอร์คอมพิวเตอร์, ไปซื้อบริษัท FPGA มาเพิ่ม ถนนทุกสายมุ่งสู่ XPU
- อินเทลฝั่งผลิต วิ่งตามคู่แข่งให้ทันด้วย Tick-Tock และหวังจะแซงหน้าด้วยเทคโนโลยีที่อยู่ในห้องวิจัยของอินเทลอย่าง RibbonFET, PowerVia, EMIB, Foveros ซึ่งชิปของอินเทลจะได้ใช้ก่อนใครเพื่อน, แก้ปัญหาต้นทุนโรงงานแพงด้วยการเปิดรับจ้างผลิตจากข้างนอก
เราอาจเคยเห็น AMD ก้าวนำหน้าอินเทลด้วยการออกแบบซีพียูยุค Ryzen ที่ยืดหยุ่นกว่า (เป็น chiplet เพิ่มจำนวนคอร์ได้ดีกว่า) บวกด้วยการจ้างโรงงาน TSMC ที่มีศักยภาพในการผลิตเหนือกว่า แต่เราเริ่มเห็นจุดอ่อนของการแยกส่วนลักษณะนี้บ้างแล้ว ตัวอย่างคือ เมื่อมาถึงยุคแพ็กเกจจิ้งแบบ 3D เราจะเห็นว่า AMD ต้องพึ่งพา TSMC ซึ่งเคลื่อนตัวได้ไม่เร็วนัก เพราะกระบวนการออกแบบชิปกับการผลิตไม่ซิงก์กัน (AMD จึงทำได้แค่ทำ stacking ให้แคช) แต่อินเทลนั้นผสาน Foveros เข้าไปตั้งแต่กระบวนการออกแบบชิป Ponte Vecchio ตั้งแต่แรกเลย
แผนการทั้งหมดของอินเทลยังต้องใช้เวลาอีกพอสมควร ตอนนี้อาจเรียกได้ว่าอยู่ในจุดครึ่งทาง แต่อินเทลก็มีแผนการปล่อยของที่ชัดเจนเรียบร้อยแล้วว่าจะออกอะไรปีไหน ถ้าหากเรารอดูกันจนถึงปี 2024-2025 ที่แผนการของอินเทลออกดอกออกผลเต็มขั้นแล้ว อินเทลก็คงกลับมาเป็นบริษัทที่น่ากลัวมากทีเดียว
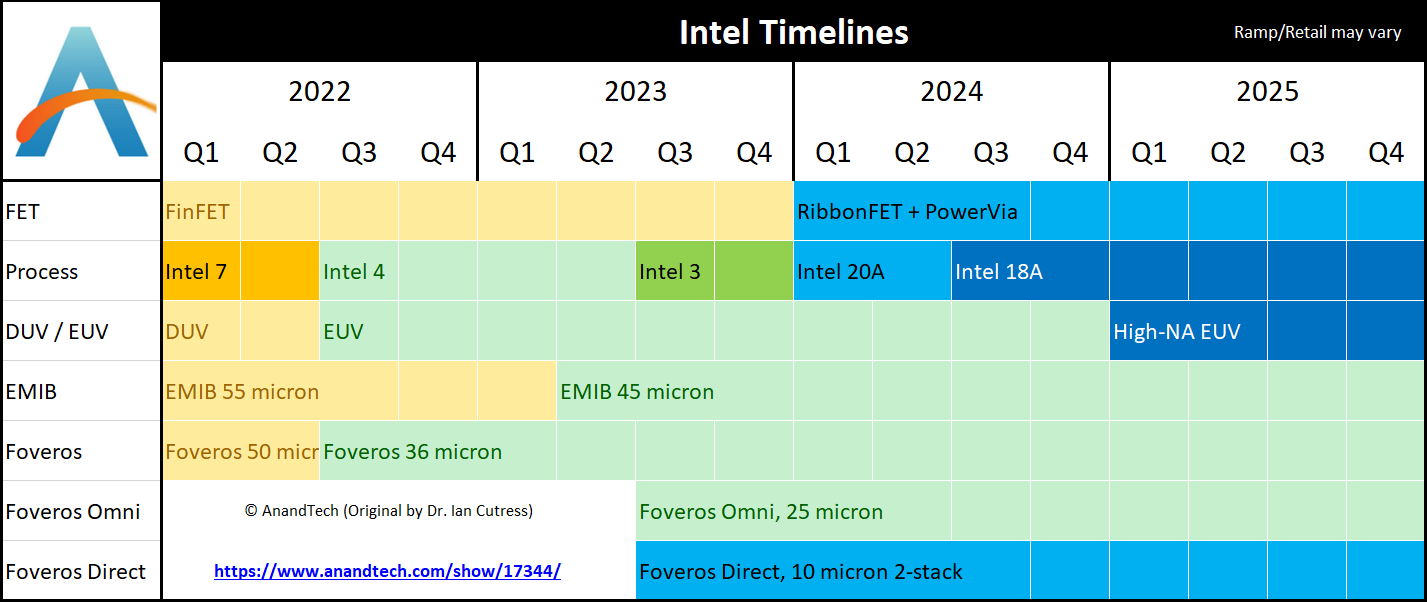
ตารางสรุปแผนการด้านการผลิตของอินเทล โดย AnandTech

Get latest news from Blognone
Follow @twitterapi



Cloudnone
- AWS มาไทย ย้ายเลยดีไหม อะไรยังมาไม่ครบบ้าง? | Cloudnone Ep. 23
- NVIDIA จะไปหยุดที่ตรงไหน ทำไมครองโลกดาต้าเซ็นเตอร์ | Cloudnone EP.22
- ถึงคลาวด์เคราะห์: ทำอย่างไรเมื่อบริการคลาวด์ที่ใช้ถูกยกเลิก | Cloudnone EP. 21
- รู้จักอาชีพ Site Reliability Engineer สำคัญยังไง? | Cloudnone EP. 20
- อธิบาย CrowdStrike ทางเทคนิค ทำไมถึงทำพีซีจอฟ้าเป็นล้านๆ เครื่อง | Cloudnone EP.19
Comments
ขอบคุณสำหรับบทความดีๆ ครับ 👍
โยลี -> โลยี
py' -> ยัง
ขอบคุณสำหรับบทความดีๆครับ อ่านแล้วได้ความรู้เพียบเลย
พอเห็นเทคโนโลยีการพัฒนาซีพียูหรือชิปเซ็ตกระโดดก้าวไปไกลแบบนี้ ผมนึกภาพไม่ออกเลยว่า สมมุติมีเด็กนักศึกษาวิศวะคอมไทยคนนึงอยากจะเติบโตไปในอุตสหกรรมนี้ (กับบริษัทยักษ์ใหญ่ระดับโลก) จะต้องพัฒนาตัวเองยังไงถึงจะก้าวไปอยู่จุดนั้นได้
แต่ผมก็จบมานานแล้วเนอะ ข้อมูลในหัวอาจจะล้าหลังไปละ บ้านเราทุกวันนี้มี ม. ไหนที่มี lab ด้าน semicondutor ที่โดดเด่นบ้างครับ
..: เรื่อยไป
บทความละเอียดมากครับ
Falcon Shores นี่น่าสนใจ
ผมว่าแนวคิดคล้ายๆ AMD Fusion คือรวม CPU+GPU และใช้ Memory เดียวกัน ไม่ต้องย้ายข้อมูลไปมา ระหว่าง RAM, VRAM ซึ่งถือเป็นคอขวดที่สำคัญของการประมวลผลใน GPU เพราะ (1)ขนาดเล็กไม่พอ (2)ถ้าต้องโอนข้อมูลบ่อยๆ ก็ไม่คุ้ม (3)ทำให้การเขียนโปรแกรมซับซ้อน แต่ AMD Fusion มาก่อนกาลเกินไปหน่อย เทคโนโลยี Chiplets, 3D Stacking ของยุคนั้นก็ยังไม่ดีพอเลยออกมาได้เท่าที่เห็น (ไม่แรง เป็นเป็ด)
ซึ่งมันก็คือสิ่งที่ Apple M1 ทำ
คือวางทุกอย่างเป็น System on Package เลย มี Unified Memory ใช้รวมกัน แถม Apple ไม่สนใจเรื่องการอัพเกรดอยู่แล้ว ก็รวม Memory เข้าไปด้วยเลย (มันก็ยิ่งแรง) แต่ Intel/AMD คงทำสุดโต่งแบบนั้นไม่ได้
ปัญหารอบนี้ไม่ใช่มาเร็วไป
แต่เป็น "มาช้าไป" "จะทันมั๊ย?" "ใครจะใช้?" "จะเกิดมั๊ย?" Intel เป็นบริษัทใหญ่ ตัดสินใจอะไรมันก็ช้า ไม่ทันชาวบ้าน เพราะ GPU computing ตอนนี้ Nvidia CUDA ยึดไว้หมดแล้ว และมี AMD Instinct (OpenCL) เล็กน้อย ส่วน Xe Core และ oneAPI จะไปลงตรงไหน?
บางทีของมันดีแต่ไม่มีคนใช้ (Google Plus, Windows Phones, etc.) นักพัฒนาไม่อยากย้าย ไม่อยากทำใหม่ ก็เหมือนที่คนยังติดอยู่กับการใช้ Windows/x86 นั่นแหละ (Intel ก็คงเข้าใจดี ใช่ไหมล่ะ 555) Intel คงต้องใช้กำลังภายในมากหน่อยรอบนี้ เอาจริงๆ ในบทความเก่าก็พูดไว้แล้ว
มองในแง่หนึ่ง AMD ก็ทำ UMA ไปแล้วใน console แต่คิดว่าที่ไม่ทำบน PC น่าจะเกิดจากฝั่ง OS ตรงนี้คงต้องไปทำงานร่วมกับ OS vendor ให้รองรับด้วย
คิดว่าที่ Fusion ไม่ไปถึงขั้น UMA (ทั้ง ๆ ที่อยู่ในแผนแต่แรก) ก็เพราะ OS นี่ล่ะครับ
แข่งกันพัฒนา ดีครับ
อ่านเพลินมากครับ ถึงแม้จะไม่ค่อยเข้าใจโลกเทคโนโลยีฝั่งเท่าไรก็ตาม
เมื่อได้วิศวกรลูกหม้อกลับมาเป็น CEO แถมยังได้วิชาการตลาดจากการไปเป็น CEO บริษัทภายนอก มันก็จะอย่างนี้แหล่ะ ต้องยกนิ้วให้บอร์ดชุดปัจจุบันที่มองขาดหาคนที่คนอื่นมองไม่เห็นกลับมาช่วยบริษัทที่กำลังเหนื่อย คล้าย Microsoft ที่พลิกสถานการณ์ได้ บริษัทที่มีแนวโน้มเป็นบริษัทร้อยปี มันต้องมีบอร์ดที่ตาคมหาคนเก่งมาทดแทนได้ถูกที่ถูกเวลา
บริษัท startup ก็เช่นกัน ไม่ใช่ founder เก่งแล้วจบ มันต้องมีผู้สนับสนุนที่มีสายตาคมมองคนขาด เพื่อหาคนมาทดแทน หรือเสริมกรณีที่ founder เหนื่อยล้า
ผู้นำ ≥ CEO ≥ Manager ที่เก่งยังสำคัญต่อองค์กร ถ้ามีคนเดียวกันหาคนมาช่วยซะ แล้วคุณจะรอด
ทำมาครับ รอซื้อ ขอเย็นและประหยัดไฟ