By: mk 
 on 18 September 2022 - 18:14
Tags:
on 18 September 2022 - 18:14
Tags:

NVIDIA และเพื่อนร่วมวงการคือ Arm และ Intel ออกมานำเสนอฟอร์แมต 8-bit floating point (FP8) สำหรับคำนวณทศนิยมเพื่องาน Deep Learning ให้ประหยัดทรัพยากรการประมวลผลขึ้นกว่าเดิม
รูปแบบงานด้านกราฟิกและ AI จำเป็นต้องคำนวณทศนิยม (floating point) ที่เดิมทีมีความแม่นยำ 32-bit (FP32) แต่มีข้อเสียตรงที่ต้องใช้พลังและหน่วยความจำในการประมวลผลมาก ช่วงหลังเมื่อวงการ AI ต้องใช้โมเดลที่มีขนาดใหญ่ขึ้นเรื่อยๆ (เช่น GPT-3 หรือ PaLM) ใช้เวลาเทรนนานเป็นหลายสัปดาห์ จึงต้องขยับมาใช้ 16-bit (FP16) ที่สิ้นเปลืองพลังน้อยลงมาก แต่ความแม่นยำไม่ลดลงมากนัก เช่น bfloat16
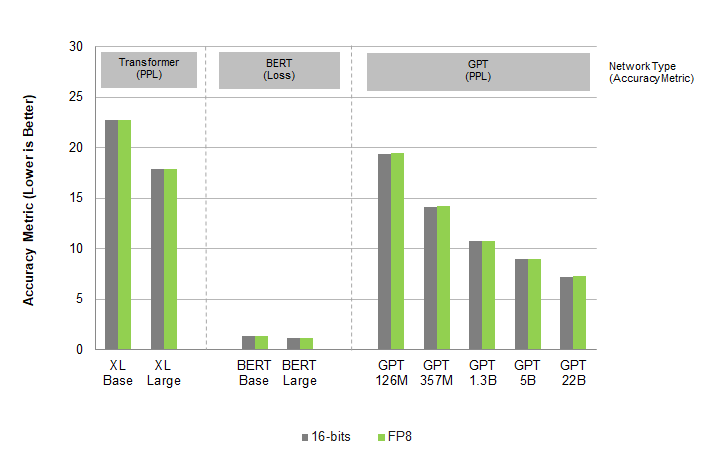
ล่าสุด NVIDIA กับพวกจึงนำเสนอ FP8 ที่เป็นการตัดจำนวนทศนิยมลงไปอีกขั้น ลดกำแพงเรื่องทรัพยากรที่ต้องใช้เทรนโมเดลลง ข้อเสนอ FP8 เป็นการวางมาตรฐานกลางให้อุตสาหกรรมใช้งาน โดย FP8 แยกวิธีการเข้ารหัสข้อมูล (encoding) ออกเป็น 2 แบบคือ E4M3 และ E5M2 ที่มีจำนวนบิตสำหรับ exponent (E) และ mantissa (M) ไม่เท่ากัน สำหรับใช้งานคนละประเภทกัน
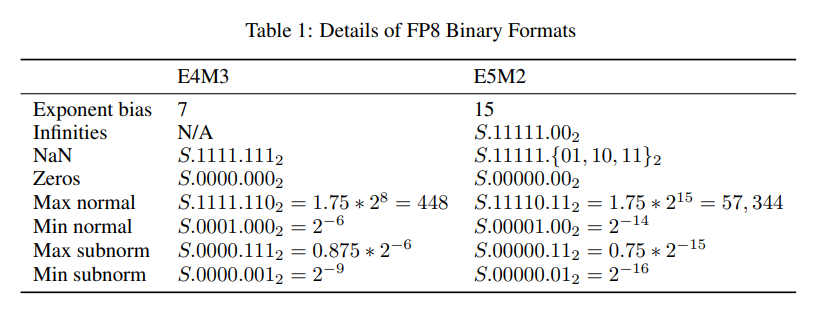
NVIDIA โชว์ผลการทดสอบโมเดล AI ต่างๆ เช่น GPT หรือ BERT ว่าการลดจาก FP16 เหลือ FP8 แทบไม่มีผลต่อความแม่นยำของโมเดลเลย
ฟอร์แมต FP8 ถูกนำมาใช้งานแล้วในจีพียูตัวใหม่ NVIDIA Hopper, Arm ระบุว่าจะเริ่มนำมาใช้กับสถาปัตยกรรม Armv9.5-A ในปี 2023 ส่วน Intel ระบุคร่าวๆ แค่ว่าจะรองรับในอนาคต ทั้งในซีพียู จีพียู และตัวเร่งประมวลผล Habana Gaudi
ที่มา - Whitepaper, NVIDIA, Arm

Get latest news from Blognone
Follow @twitterapi



Cloudnone
- AWS มาไทย ย้ายเลยดีไหม อะไรยังมาไม่ครบบ้าง? | Cloudnone Ep. 23
- NVIDIA จะไปหยุดที่ตรงไหน ทำไมครองโลกดาต้าเซ็นเตอร์ | Cloudnone EP.22
- ถึงคลาวด์เคราะห์: ทำอย่างไรเมื่อบริการคลาวด์ที่ใช้ถูกยกเลิก | Cloudnone EP. 21
- รู้จักอาชีพ Site Reliability Engineer สำคัญยังไง? | Cloudnone EP. 20
- อธิบาย CrowdStrike ทางเทคนิค ทำไมถึงทำพีซีจอฟ้าเป็นล้านๆ เครื่อง | Cloudnone EP.19
Comments
"NVIDIA กับพวก" อิอิ
EVGA : ข้าไม่ใช่พวกเอ็งละ ลาก่อย
"September 2022 the company ended their relationship with Nvidia and thus stopped manufacturing graphics cards."
ตามนั้นเลยงับ
ต้องรอ HW ใหม่ที่ support เช่น
cpu ใหม่ที่มีวงจร FP8 ในตัว
อาจมีการ simd เพื่อทำ fp8 พร้อมกัน 8ตัว (64bit) อะไรทำนองนี้ด้วยสินะ?
เป็นไปได้ครับ เหมือนตอนจาก series 2000 > 3000 เพิ่ม tf32 เข้ามา
ผมละระแวงจริงๆ เวลา cpu เพิ่มวงจรเข้าไปใหม่ จะโดน hack มั้ยล่ะนั่น
เย้
อันนี้เรียก quarter-precision ได้มั้ยครับ :D