By: tontan 


 on 19 February 2023 - 17:51
Tags:
on 19 February 2023 - 17:51
Tags:

หลังจากที่กระแส ChatGPT ได้สร้างปรากฏการณ์ในวงการคอมพิวเตอร์จำนวนมาก ทั้ง Bing นำมาเป็นส่วนหนึ่งของระบบค้นหา, Google เปิดตัว Bard ที่ใช้ LaMBDA มาเพื่อแข่งกับ Bing และอื่น ๆ แต่ผู้ใช้งาน ChatGPT คงเจอปัญหาเวลาใช้งาน ChatGPT กับภาษาไทยแล้วทำงานช้ามาก เพราะ ChatGPT ไม่ได้ฝึกฝนด้วยชุดข้อมูลภาษาไทย นอกจากนั้น ChatGPT ยังเป็นซอฟต์แวร์ที่เป็นกรรมสิทธิ์ของ OpenAI และไม่ได้เป็น Open Source (ไม่เปิดเผยชุดข้อมูลที่ใช้ฝึกสอน-ไม่เปิดเผย Source Code)
ในปัจจุบันได้มีความพยายามสร้างโมเดล ChatGPT ในรูปแบบของ Open Source ที่ฝึกสอนโมเดลจากชุดข้อมูลบทสนทนาในภาษาต่าง ๆ ตัวอย่างเช่น ภาษาอังกฤษ, ภาษาจีน โมเดล ChatYuan และภาษาอื่น ๆ แต่สำหรับภาษาไทย ชุดข้อมูลบทสนทนา (conversational datasets) สำหรับใช้สอนโมเดล ณ ปัจจุบันยังไม่มี และค่าใช้จ่ายในการสร้างชุดข้อมูลค่อนข้างสูง เนื่องจากต้องใช้คนมาช่วยกันป้อนข้อมูลบทสนทนาให้โมเดลเรียนรู้ ดังนั้นผมจึงขอเชิญชวนชาว Blognone มาช่วยกันสร้างชุดข้อมูลบทสนทนาภาษาไทยสำหรับสอนแชทบอทที่เหมือน ChatGPT เพื่อให้นักวิจัยไทย และนักพัฒนาปัญญาประดิษฐ์ได้มีชุดข้อมูลสำหรับสร้างปัญญาประดิษฐ์ผู้ช่วยภาษาไทย (Open Assistant; AI Assistant หรือ “ChatGPT ภาษาไทย”)

สำหรับโครงการที่แนะนำคือ โครงการ Open Assistant โดย LAION-AI เจ้าของผลงานชุดข้อมูล LAION-5B ชุดข้อมูลคู่ข้อความ-รูปภาพอันลือลั่นที่ทำให้เกิดปรากฏการณ์ปัญญาประดิษฐ์วาดรูปอย่าง Midjourney และ Stable Diffusion มาแล้ว
ในครั้งนี้ LAION-AI มีเป้าหมายคือสร้างปัญญาประดิษฐ์ผู้ช่วยแบบโอเพนซอร์สเสมือน ChatGPT แต่ใช้งานได้ฟรี, เปิดเผยชุดข้อมูล, เปิดเผย Source Code, และนำไปทำงานบนคอมพิวเตอร์ตัวเองแบบออฟไลน์ได้ทั้งงานวิจัยและเชิงพาณิชย์ ขณะนี้ทางโครงการได้เริ่มต้นรับบริจาคชุดข้อมูลบทสนทนาในภาษาต่าง ๆ แบบ Crowdsourcing โดยหลังจากเสร็จสิ้นจะปล่อยภายใต้ CC BY 4.0 โดยก่อนอื่น ผมขอแนะนำให้อ่านเอกสาร Guidelines ตามที่ทางโครงการ PyThaiNLP ได้จัดทำขึ้นที่ pythainlp.github.io/Open-Assistant-Thailand/
มาเริ่มสร้างชุดข้อมูลกัน!
- เข้าไปที่ https://open-assistant.io/th
2. กด Sign In ด้วยอีเมล (ต้องไปเปิดลิงก์ในเมลที่ป้อน) หรือ เข้าสู่ระบบด้วย Discord แล้วจะพบกับหน้าหลักดังนี้
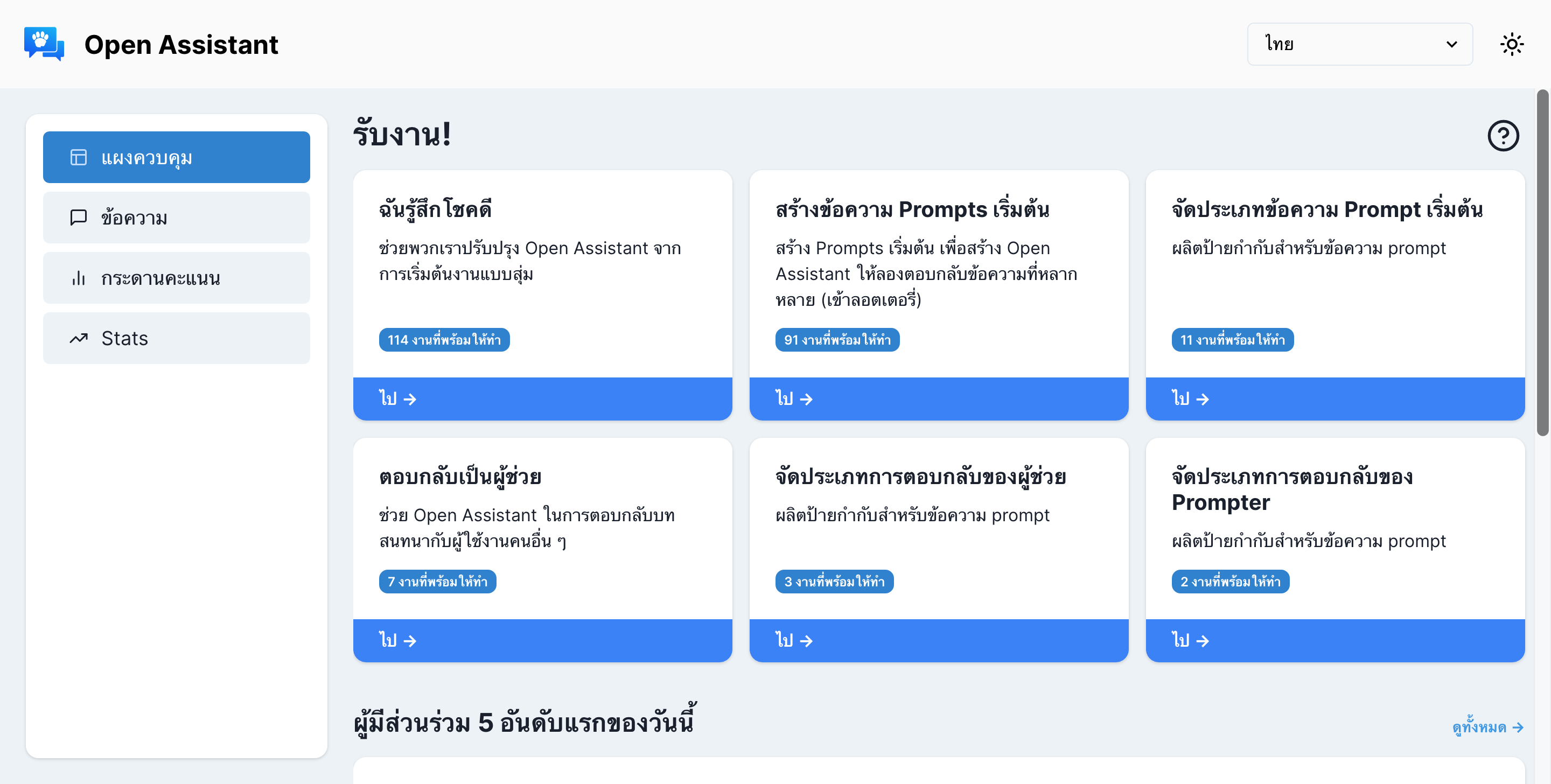
3. ให้เลือกภาษาเป็น “ไทย” เท่านั้น เพราะถ้าเลือกภาษาอื่น ๆ จะไม่สามารถป้อนภาษาไทยได้ โดยงานมีด้วยกัน 7 อย่างดังนี้
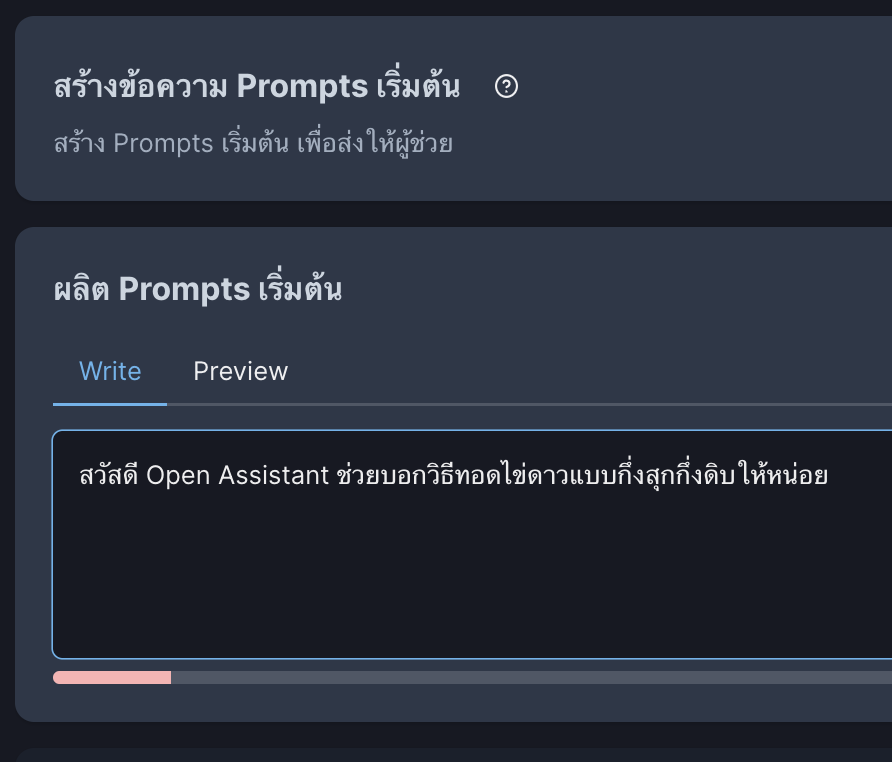
3.1 “สร้างข้อความ Prompts เริ่มต้น” (Create Initial Prompts) สำหรับสร้างข้อความเริ่มต้นสนทนากับ Open Assistant ของเรา เช่น “สวัสดี Open Assistant ช่วยบอกวิธีทอดไข่ดาวแบบกึ่งสุกกึ่งดิบให้หน่อย”
โดยข้อมูลที่ป้อนต้องทำตาม Guidelines สรุปย่อ ๆ คือเป็นข้อความใหม่ ไม่ก็อปจากที่ไหน, เป็นข้อความที่ไม่สนับสนุนความรุนแรง/เนื้อหาทางเพศ/ความเกลียดชัง/ข้อความที่ผิดกฎหมาย ข้อความที่ป้อนสามารถใช้ markdown ได้
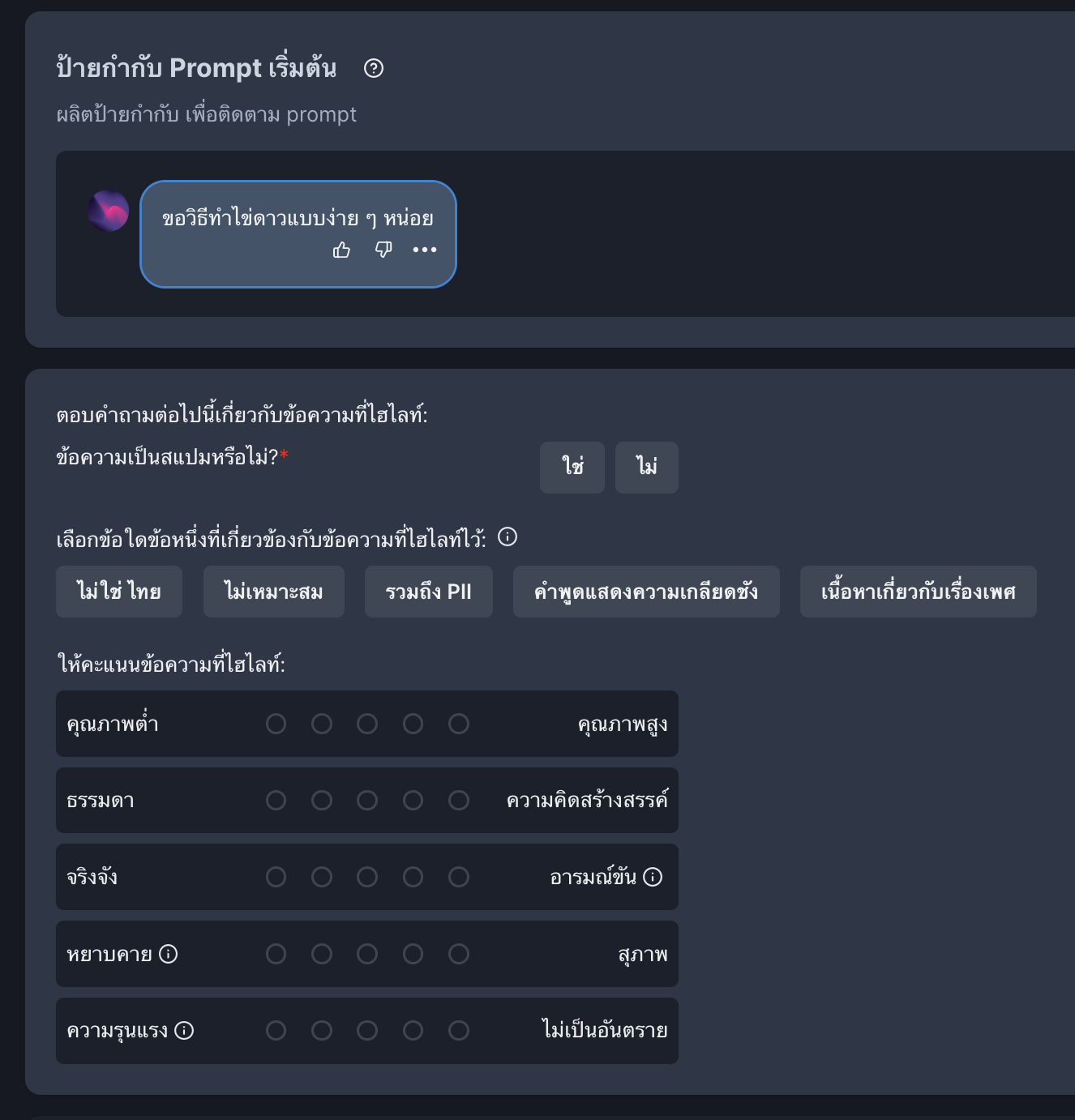
3.2 “จัดประเภทข้อความ Prompt เริ่มต้น” (Classify Initial Prompt) เป็นการกำกับข้อความเริ่มต้นใน 3.1 ว่าเหมาะสมหรือไม่ ได้แก่
- เป็นสแปมหรือไม่ (ใช่/ไม่)
- คุณภาพต่ำ-สูง (1-5)
- ธรรมดา-สร้างสรรค์ (1-5)
- จริงจัง-อารมณ์ขัน (1-5)
- หยาบคาย-สุภาพ (1-5)
- มีความรุนแรง-ไม่มีอันตราย (1-5)
3.3 “ตอบกลับเป็นผู้ช่วย” (Reply as Assistant) สำหรับสร้างข้อความที่ Open Assistant จะตอบคำถามกลับไปหาผู้ใช้งาน เช่น “การทอดไข่ดาวแบบกึ่งสุกกึ่งดิบมีขั้นตอนดังต่อไปนี้ 1. ใช้ไฟอ่อนๆ …” คำแนะนำในการสร้างข้อความคล้ายกับ 3.1 แต่เพิ่มเติมจาก PyThaiNLP คือให้สวมบทเป็นปัญญาประดิษฐ์ เช่น ใช้คำตอบแบบไม่ระบุเพศ (ไม่ต้องมีครับ/ค่ะ, แทนตัว Open Assistant ด้วยฉัน) เป็นต้น
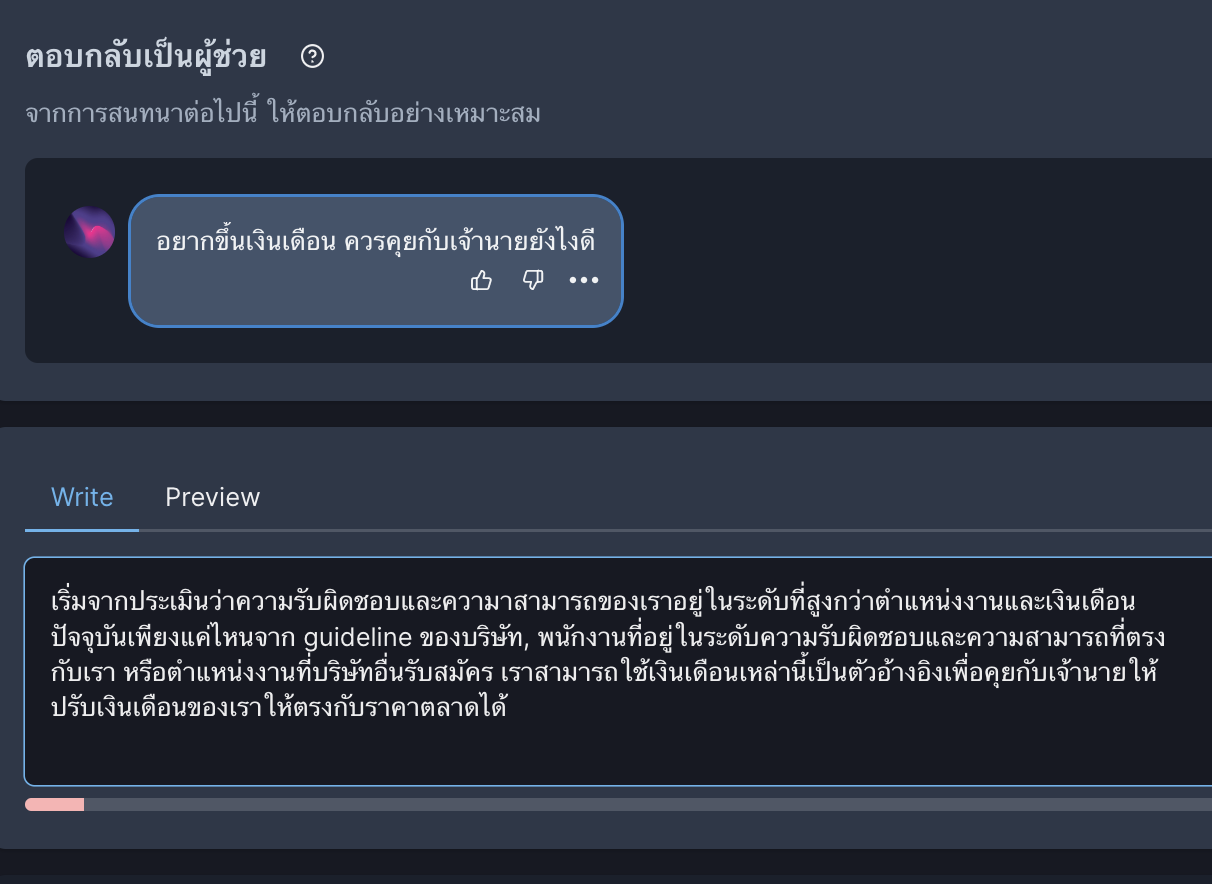
3.4 “จัดประเภทการตอบกลับของผู้ช่วย” (Classify Assistant Reply) เป็นการกำกับข้อความที่ Open Assistant ตอบกลับใน 3.3 เกณฑ์การประเมินคล้ายกับ 3.2 เพิ่มเติมคือ
- เป็นการตอบกลับที่ไม่ดีสำหรับ Prompt ที่ให้มาหรือไม่ (ใช่/ไม่) ส่วนใหญ่คือการตอบไม่ตรงคำถาม เช่น
กรณีไม่ดี (ตอบ ใช่)
ถาม: สีประจำวันพุธสีอะไร
ตอบ: วันพุธเป็นวันกลางสัปดาห์
กรณีดี (ตอบ ไม่)
ถาม: สีประจำวันพุธสีอะไร
ตอบ: สีเขียว
- ไม่เป็นประโยชน์-มีประโยชน์ (1-5)
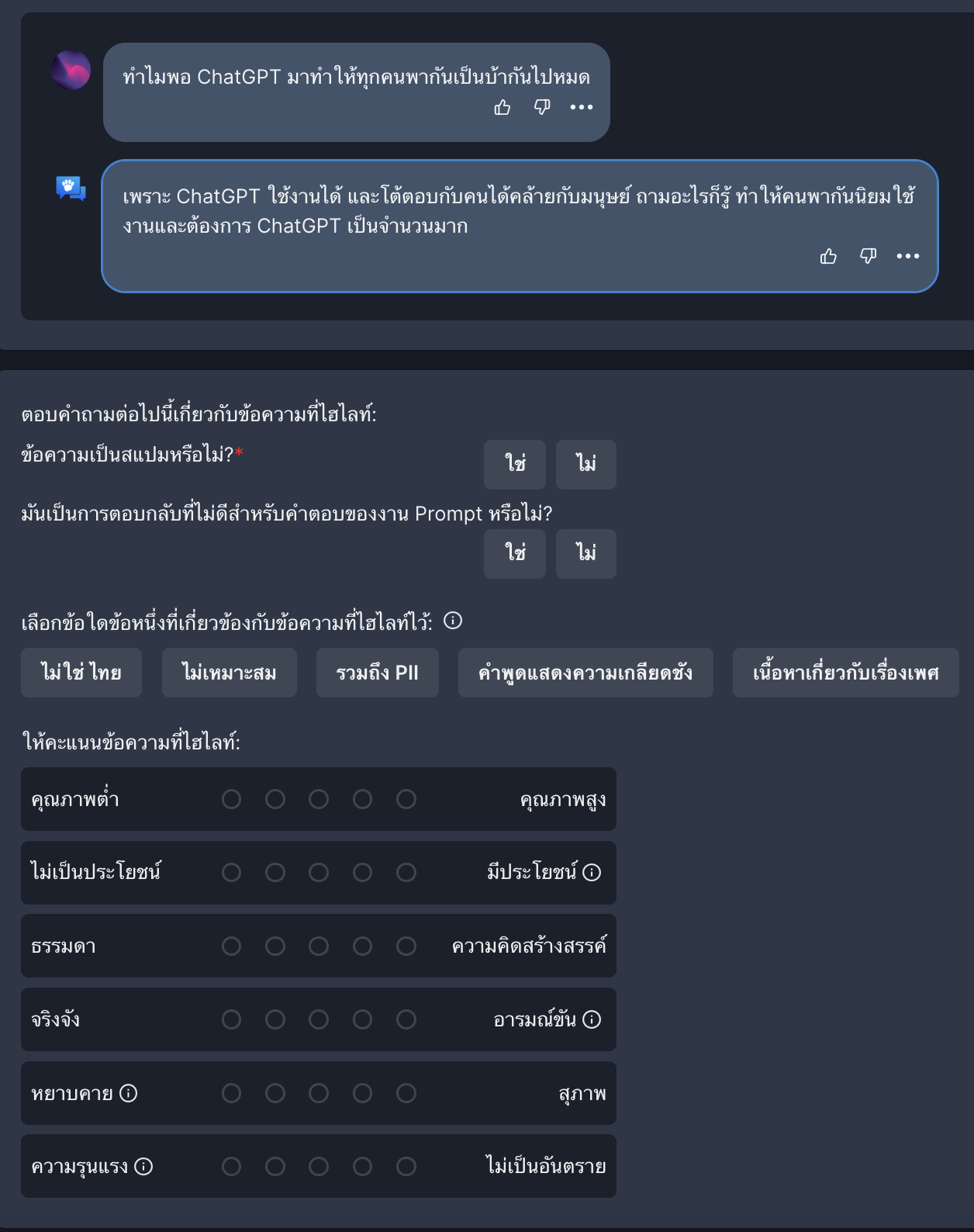
3.5 “จัดอันดับการตอบกลับของผู้ช่วย” (Rank Assistant Replies) เป็นการจัดอันดับความตอบกลับที่ Open Assistant สร้างขึ้น ให้ลากวางคำตอบที่เหมาะกับ Prompt ที่สุด

3.6 “ตอบกลับเป็นผู้ใช้งาน” (Reply as User) สำหรับสร้างข้อความที่ผู้ใช้งานจะตอบกลับข้อความจากที่ Open Assistant สร้างขึ้นต่อจาก 3.3 เช่น
โจทย์
ผู้ใช้: ช่วยบอกวิธีการทำอาหารอิตาเลี่ยนหน่อย
Open Assistant: คุณต้องการอาหารอิตาเลี่ยนเมนูไหน
คุณต้องตอบด้วยข้อความ เช่น “ขอเมนูพาสต้าแล้วกัน” หรือ “ขอเมนูพิซซ่า” เป็นต้น
3.7 “จัดประเภทการตอบกลับของ Prompter” (Classify Prompter Reply) เป็นการกำกับข้อความที่ผู้ใช้ตอบกลับ Open Assistant ใน 3.6 โดยมีเกณฑ์เดียวกับ 3.2
4. การกำกับข้อความหรือป้อนข้อความใด ๆ ให้ปฏิบัติตาม Guidelines หรือเอกสารแนะนำภาษาไทย อย่างเคร่งครัด ที่สำคัญที่สุดคือ
- สร้างข้อความใหม่ ไม่ก็อปจากที่ไหน
- ไม่สร้างข้อความที่สนับสนุนความรุนแรง/เนื้อหาทางเพศ/ความเกลียดชัง/ข้อความที่ผิดกฎหมาย
- เมื่อสร้างข้อความให้ Open Assistant เป็นคนตอบให้สวมบทปัญญาประดิษฐ์ เช่น ใช้คำตอบแบบไม่ระบุเพศ (ไม่ต้องมีครับ/ค่ะ) เป็นต้น
สามารถดูรายละเอียดเพิ่มเติมได้ที่ Open-Assistant.io/th และ pythainlp.github.io/Open-Assistant-Thailand/
พูดคุยกับชุมชน Open Assistant Thailand ได้ที่ Open Assistant Thailand - Facebook Groups
ข้อมูลเปิดเผย โครงการ PyThaiNLP เป็นผู้เขียนบทความนี้


Get latest news from Blognone
Follow @twitterapi



Comments
ขอบคุณมาก ๆ ครับ กำลังทำอยู่พอดี น่าสนใจมาก ๆ แถมเป็นชุดข้อมูลสาธารณะด้วย
UI แปลไทยได้สับสนมาก
ผมขออภัยสำหรับการแปลที่ทำให้สับสนครับ นอบรับความคิดเห็นนำไปปรับปรุงครับ ผมขอรบกวนสอบถาม ไม่ทราบว่าท่านเจอจุดใดที่ควรปรับปรุงบ้างนะครับ ขอบคุณครับ
บล็อก: wannaphong.com และ Python 3
+1 เห็นด้วยครับ
การติเพื่อปรับปรุง ถือเป็นเรื่องดีและทำให้ระบบสมบูรณ์ อันนี้เห็นด้วยและชื่นชม
แต่การติแบบที่ว่า:
แต่เป็นการติแบบสักแต่จะติ แบบโยนระเบิดตู้มแล้วก็ไป
มันเป็นการติที่ไม่สร้างสรรค์เอามากๆครับ มันไม่ได้ช่วยอะไรเลย มีแต่ทำให้คนทำงานเขาเสียขวัญกำลังใจไปเปล่า ๆ เพราะงงว่า ฉันต้องไปแก้จุดไหน ยังไง 🤔 😅
ถ้าอยากจะให้เขาปรับปรุง ควรระบุให้ละเอียดที่สุดครับ จุดไหนบ้างควรแก้ ร้อยทั้งร้อยทีมงานเขาพร้อมแก้ไขให้มาก ๆ ครับและแฮปปี้ด้วย ที่ในที่สุดก็มีคนเห็นจุดบกพร่องในสิ่งที่เรามองข้าม
อย่าใช้คำติแบบกว้าง ๆ เลย พวกเรางง พวกเราทำตัวไม่ถูก 😂
จากใจทีมแปลที่โดนแบบนี้บ่อย ๆ 😅
คุณ figgaro ตอบแทนไปบางส่วนแล้ว ซึ่งจริงๆ ผมก็ไม่รู้ทำไมจะต้องตอบให้ละเอียดเพราะหลายๆ อย่างมันค่อนข้าง obvious มาก คือแค่อ่านไม่กี่อย่างก็เห็นแล้วว่าเป็น literal translations เอาง่ายๆ คือการแปลแบบ word-for-word นั่นแหละ ภาษานักแปลก็คงเรียกว่า low readability
ถ้าใครเคยแปลกับบริษัทใหญ่ๆ หรือโดยเฉพาะถ้าเคยเป็น team lead มาก่อนน่าจะเห็นตรงกันว่าปัญหาการแปลแนวๆ นี้มักจะเกิดขึ้นกับมือใหม่ที่ชอบแปลตรงตัว แปลโดยไม่กล้าแก้ไขอะไรจาก source text ไม่ paraphrase ไม่ relocate อะไรเพราะกลัวมันจะผิดเพี้ยนจากต้นฉบับ ข้อผิดพลาดที่เจอกันบ่อยสุดคือการคงไว้ซึ่ง passive voice เหมือนในภาษาอังกฤษ พอมาใช้กับภาษาไทยอ่านแล้วปวดหัว เหมือนต้องแปลไทยเป็นไทยอีกรอบ
แต่เห็นคุณ jaideejung007 บอกว่าตัวเองเป็นทีมแปลที่โดนแบบนี้บ่อยๆ ผมแนะนำว่าถ้าโดนบ่อยๆ ต้องไปศึกษาจากผู้ใช้ดูครับว่าตรงไหนที่มีปัญหา เขาไม่เข้าใจตรงไหน หรือตรงไหนที่รู้สึกว่ามันไม่เป็นธรรมชาติ ตรงไหนที่ถ้าแก้สักนิดแล้วจะดีขึ้น หรือเอาง่ายๆ แปลเสร็จลองอ่านออกเสียงดังๆ ให้ตัวเองฟังดูครับว่าฟังแล้วเหมือนภาษาคนปกติหรือเปล่า (ไม่นับพวก legal text หรือ domain ที่ต้อง formality) แต่เอาจริงๆ หลายๆ ครั้งผมสังเกตว่าคนแปลจะไม่เห็นว่าตัวเองแปลไม่ดีนะ ถ้าจะให้ดีต้องถามคนใช้อีกทีว่าเขาโอเคหรือเปล่า อีกอย่างบางครั้ง client ก็ไม่ได้รู้เรื่องภาษาที่เขาให้เราแปล บางทีให้ 3rd party มาตรวจก็ตรวจส่งๆ กลายเป็นว่าสุดท้ายก็เอางานที่ไม่เสร็จดีนั่นละมา go live เฉย บางทีเห็นแล้วก็ท้อ
ถ้าจะเสวนาเรื่องนี้เพิ่มเติม ทักอีเมลผมมาก็ได้ครับ เติม @gmail.com ใส่ท้ายชื่อส่งมาได้เลย
ถ้ามองในแง่คนทำ หลาย ๆ ครั้ง obvious สำหรับคนใช้ มันก็ไม่ obvious สำหรับคนทำครับ
อันนี้คนที่เคยพัฒนาอะไรสักอย่างน่าจะเจอกันมาหมดแล้ว
ผมว่าจะเป็นเรื่องการแปลที่ตรงตัวอักษรเกินไปครับ เพราะมันดูไม่ใช่ภาษาที่คนทั่วไปใช้และอ่าน เช่น
Will Open Assistant be free? => Open Assistant จะฟรีใช่ไหม?
อาจจะเขียนได้ประมาณนี้ซึ่งดูเข้าใจตรงภาษาไทยมากกว่า
"มีค่าใช้จ่ายในการใช้งาน Open Assistant ไหม?"
Yes, Open Assistant will be free to use and modify. => ใช่ Open Assistant จะใช้และแก้ไขได้ฟรี
อาจจะเขียนได้ประมาณนี้ซึ่งดูเข้าใจตรงภาษาไทยมากกว่า
"Open Assistant ไม่มีค่าใช้จ่ายในการใช้งานและแก้ไข"
FREE FOR ALL
อยากให้มีชุมชนบน discord ด้วย
เพราะบน fb บางคนไม่ค่อยสะดวกครับ
WE ARE THE 99%
ขอบคุณครับ ส่วนตัวผมไม่แน่ใจเรื่องชุมชนผู้ใช้งานระหว่างบน fb กับ discord ครับ ผมเคยพูดคุยกันภายในทีมเลยได้ข้อสรุป เบื้องต้นสร้างบน fb ก่อนครับ ส่วนบน discord ค่อยว่ากันอีกรอบครับ แต่ส่วนตัวผม ถ้าบน discord อยากให้ยึด discord ของ open assistant เป็นหลักครับ
บล็อก: wannaphong.com และ Python 3
ปรากฎ => ปรากฏ
ปฎิบัติ => ปฏิบัติ
สีออะไร => สีอะไร
แก้ไขเรียบร้อยแล้วครับ ขอบคุณครับ
บล็อก: wannaphong.com และ Python 3
ดูยุ่งยากมาก ไม่มีวิธีอื่นที่ดีกว่านี้แล้วหรือ
รอวันนึง Google, Facebook ทำมาให้ใช้ เมื่อเขาคิดว่าตลาดประเทศไทยสำคัญพอ ง่ายสุด
เทียบกับ CatGPT แล้ว เป็นไงบ้างครับ?
ม้าว ม้าว ม้าว
😂
การสร้างหรือพัฒนาของเราเองผมว่าดีมากครับ
หลังจากที่ทดลองใช้มาโดยเน้นด้านเรื่องทั่วไป การศึกษา และการขอความคิดเห็น ขอบอกไว้ก่อนนะครับว่าผมไม่ได้เชี่ยวชาญใน IT แต่เรื่องการจัดการ การทำความเข้าใจในกระบวนการ การเรียนรู้ รับรู้ พอมีทักษะบ้าง ผมพบว่าภาษาไม่ใช่ปัญหาหลักในการใช้งาน ChatGPT ในเวลานี้ และปัญหาพวกนี้จะค่อยๆลดลงไปในอนาคตเนื่องจากการพัฒนา
สิ่งสำคัญคือโครงสร้างการเขียนที่ต้องสอดคล้องกับเรื่องที่ถามนั้น AI เรียนรู้มาแบบไหน อย่างไร จากไหน
ทดลองจากคำสั่งทางวิชาการสั้นๆไม่ซับซ้อนปรากฏว่าถูกทุกอย่าง แต่ก็ผิดด้วย นอกจากนี้จากการลองเขียนเนื้อหาที่เขียน prompt เป็นชุดสั้นๆ แต่ละชุดได้คำตอบถูกต้องตามต้องการ แต่พอเอามารวมกันและถาม ปรากฏว่าตกหล่น prompt ไปบางอัน.ทำให้พอเข้าใจได้ว่าหากจะใช้ให้ได้ประสิทธิภาพอย่างน้อยต้องลองให้รู้จักนิสัยของมัน(รูปแบบการเรียนรู้ที่ได้รับ)ในเรื่องที่เราจะถาม.
เรื่องนี้เป็นจุดอ่อนของ ChatGPT ที่คนยังไม่เข้าใจมากนัก เนื่องจากการเรียนรู้ของมันผมคิดว่าเกิดจากการกระจายงาน และแยกทำ แล้วใช้การรวมเข้าด้วยกันโดยอาจมีกาจำแนกด้วยการกำหนดคีย์เวิร์ด แต่ขาดการต่อติดเชื่อมโยงต่อกันในบางด้านเช่นการลำดับขั้น อย่างสมมุติว่าจะสอนเรื่อง A แล้วกระจายงานแยกหัวข้อ 1 2 3 4 5 เป็นรายบุคคล พอส่งข้อมูลเข้ามาอาจสั่งให้เรียงตาม 1 2 3 4 5 แต่ไม่ได้ระบุว่า ความสำคัญ ขั้นตอน ของเนื้อหา AI จะต้องเรียงยังไงอันไหนสำคัญกว่ากันหรือเรียงการใช้กันยังไง จุดนี้ผมเจอจากการที่ prompt ซึ่งถามถึง กระบวนการ ขั้นตอน หรือ process ปรากฏว่าตอบมีเนื้อหา 2 ข้อที่เกินมาแล้วไปเรียงเป็นลำดับท้ายสุด ทั้งที่ 2 อันนี้มันเป็นวิธีการ หรือ method จะอยู่นอกเรื่องหรือไปอยู่เป็นข้อย่อยได้แล้วแต่การให้ความสำคัญ จะเห็นว่าปัญหาอาจมาจากการที่ เรื่องที่ 1-5 มีเนื้อหาเกี่ยวข้องกันแล้วเรื่องนึงพูดแบบ method แต่อีกเรื่องพูด process
ผมอยากจะให้นำจุดนี้ไปคำนึงถึงการสร้าง AI ที่จะทำกันด้วยทั้งในเรื่องโครงสร้างการเขียน prompt ที่ส่งผลต่างกันตามข้อมูล และการทำฐานข้อมูลให้สอดคล้อง เพราะรูปแบบการทำงานคล้ายกันคือการแบ่งงานกันทำ ส่วนใหญจะตรวจสอบด้วยความถูกต้องของข้อมูลที่ส่งมาเป็นรายๆโดยเทียบแหล่งอ้างอิง หรือส่งให้ผู้เชี่ยวชาญตรวจสอบไม่น่าจะถามลึกในประเด็นกระบวนการหรือลำดับแน่เพราะงานสเกลนี้ก็ไม่ได้ให้ผู้เชี่ยชาญทำคนเดียวต่อเรื่อง
การแก้ไขให้คิดว่าเราไม่ได้เข้าใจทุกเรื่องและผู้เชี่ยวชาญใช่ว่าจะรู้ทุกอย่าง ผู้เชี่ยวชาญเฉพาะด้านก็เก่งด้านนั้นแต่เรื่องที่เป็นด้านที่กว้างออกมากลับต้องใช้อีกคน ควรต้องมีการตรวจเป็นเรื่องๆ และรวมกันอีกที