By: arjin 

 on 2 March 2023 - 17:40
Tags:
on 2 March 2023 - 17:40
Tags:
ทีมงานนักวิจัยของไมโครซอฟท์ เผยแพร่งานวิจัย Kosmos-1 โมเดลสร้างภาษาบนข้อมูลสื่อผสมผสาน (Multimodal Large Language Model - MLLM) โดยสามารถเรียนรู้ข้อมูลทั้งตัวหนังสือ รูปภาพ แคปชันประกอบรูปภาพ มาประมวลผลจนสามารถให้ข้อมูลอธิบายได้ในหลากหลายมิติ
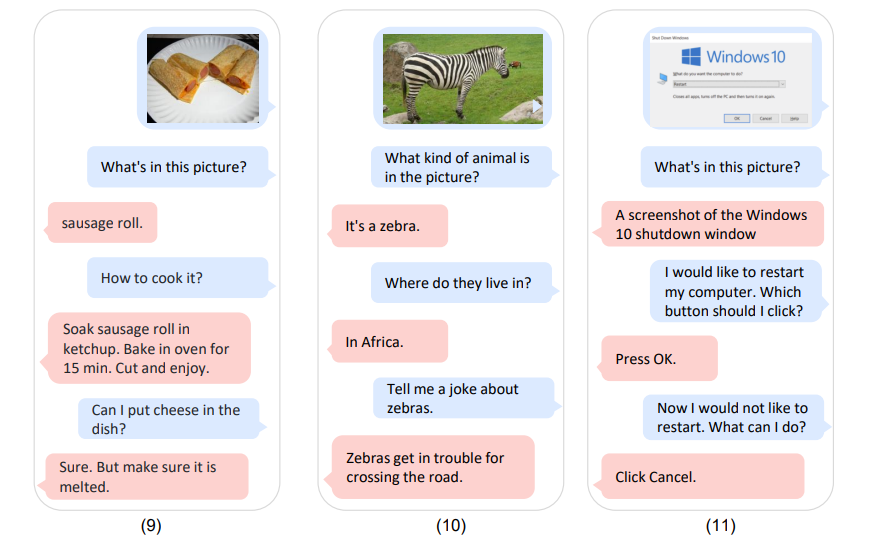
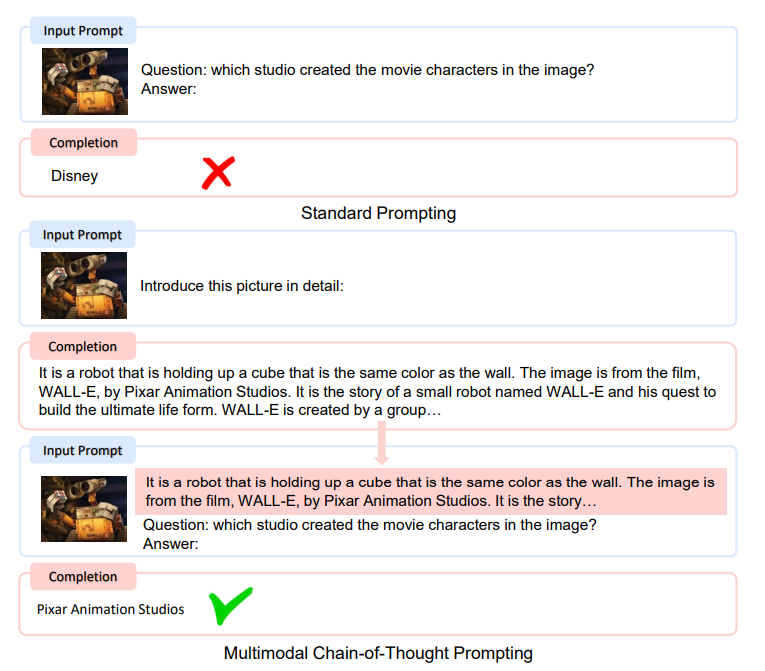
ตัวอย่างความสามารถของ Kosmos-1 ที่เผยแพร่ในงานวิจัย เช่น การตอบคำถามจากข้อมูลรูปภาพที่กำหนด ซึ่งโมเดลสามารถเข้าใจบริบทเรื่องราวที่มีอยู่ในภาพได้, สามารถแปลงข้อมูลตัวหนังสือในภาพ (OCR) เพื่อตอบคำถามได้, สามารถหารายละเอียดสำคัญในรูปภาพ และสืบค้นข้อมูลต่อได้ เป็นต้น
ในการทดสอบโมเดล งานวิจัยยังให้ตอบคำถามหลายรูปแบบ เช่น การให้เหตุผลจากในภาพ การตอบคำถามทดสอบไอคิว หรือการใส่คำถามที่ต้องสืบค้นหลายขั้นตอน สถานะของโมเดลนี้ยังอยู่ในระดับงานวิจัย แต่ทำให้เห็นว่าในอนาคต AI สร้างเนื้อหา จะสามารถเพิ่มความสามารถใหม่ ๆ ได้อีกแค่ไหน สามารถดาวน์โหลดรายละเอียดงานวิจัยได้ที่นี่
ที่มา: Big Tech Wire
ตัวอย่างการทดสอบโมเดล


Get latest news from Blognone
Follow @twitterapi



Comments
ตอนนี้มีวิธีไหนสร้างแคปชั่นจากภาพได้เลยบ้างครับ แบบไม่ต้องล้ำตามข่าวนี้ เราให้ AI อธิบายบอกสิ่งที่อยู่ในภาพได้เช่น แมวกำลังกินปลา ผีเสื้อบนดอกไม้สีแดง ชายสูงอายุถือร่มกันแดด ฯลฯ อะไรแบบนี้
WE ARE THE 99%
https://replicate.com/collections/image-to-text