By: arjin 

 on 10 April 2024 - 07:58
Tags:
on 10 April 2024 - 07:58
Tags:
Topics:

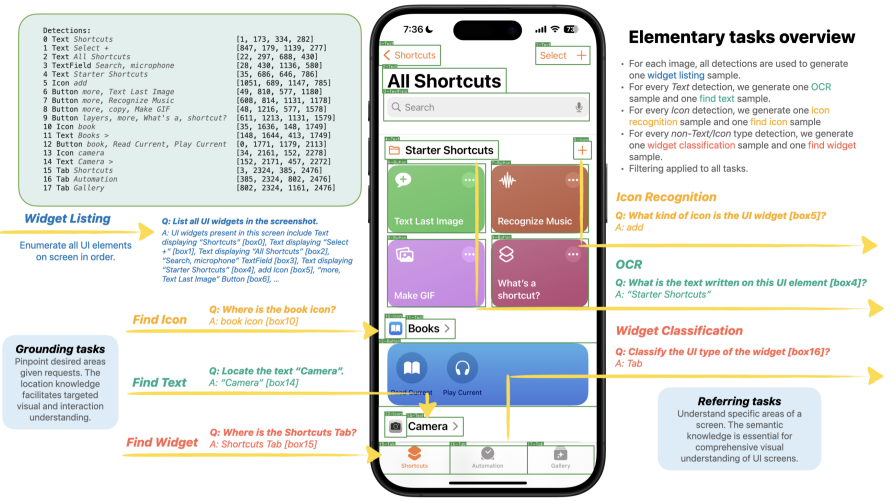
ทีมนักวิจัยของแอปเปิลเผยแพร่งานวิจัยใหม่ Ferret-UI ซึ่งเป็น Generative AI หรือ AI สร้างเนื้อหา ที่ต้องการแก้ไขปัญหาโมเดลภาษาขนาดใหญ่ข้อมูลผสมผสาน (MLLM - Multimodal Large Language Model) ที่ยังมีข้อจำกัดสำหรับอินพุทรูปภาพ ที่มีรายละเอียดเยอะมาก แต่อาจมีจุดสำคัญไม่กี่อย่าง เช่น ภาพจับหน้าจอโทรศัพท์ (Screen Capture)
สิ่งที่ท้าทายของอินพุทภาพหน้าจอโทรศัพท์คือ อัตราส่วนภาพหน้าจอโทรศัพท์ ที่แตกต่างจากรูปที่ AI นิยมใช้เทรนกัน, ในภาพหน้าจอมีไอคอนหรือปุ่ม ที่มีขนาดเล็ก ความละเอียดต่ำ AI อาจแยกแยะไม่ได้ และหลายกรณีปุ่มเหล่านั้นคือประเด็นสำคัญของอินพุทอีกด้วย
Ferret-UI ถูกเทรนด้วยภาพหน้าจอที่มีคำสั่งหรือสิ่งที่ให้ทำต่าง ๆ จึงสามารถแยกแยะไอคอน ค้นหาข้อความสำคัญ จนถึงข้อมูลวิดเจ็ต ได้โดดเด่นกว่าโมเดลอื่น และความสามารถในการทำงานรองรับกับสิ่งที่เกิดบนหน้าจอได้ ผลทดสอบพบว่าทำงานได้ดีกว่า GPT-4V และ MLLM ตัวอื่นที่เน้นการทำงานกับภาพหน้าจอ
งานวิจัยนี้เน้นอธิบายความสำเร็จของโมเดลนี้ แต่ไม่ได้ลงรายละเอียดว่า Ferret-UI จะนำไปใช้งานด้านใด จึงยังไม่ชัดเจนว่าแอปเปิลจะเพิ่มความสามารถของ AI นี้ กับผู้ใช้งานทุกคนหรือไม่ เพราะมีประเด็นความเป็นส่วนตัว แต่อาจใช้งานได้สำหรับการเข้าถึงของผู้ใช้งานที่มีปัญหาการมองเห็น เป็นต้น
ที่มา: 9to5Mac

Get latest news from Blognone
Follow @twitterapi



Comments
ก็เห็นมีข่าวแว่วๆ ว่าจะทำ Home robot ก็น่าจะตัวนั้นแหล่ะมั้ง สไตล์ Apple ต้องปะติดปะต่อข่าวเอาเอง เพราะจดสิทธิบัตรชอบจดแบบกำกวม แต่การ Tag หาตำแหน่งบนหน้าจอ มันคิดได้ไม่กี่อย่าง เช่น การทำ Gesture ด้วยมือ เพื่อควบคุมการกดคำสั่งโดยไม่ต้องสัมผัสจอ รวมไปถึงการใช้สิ่งจากภายนอกเรียนรู้ตำแหน่งเพื่อควบคุมจอแทนเรา เช่น หุ่นยนต์ ซึ่งอาจเป็นมือถือ หรืออุปกรณ์อื่นๆ ก็ได้ ฯลฯ ถ้าทำได้ก็เทพแหล่ะ เพราะมันมีปัญหาแฝงเพียง ทั้งเรื่องสภาพแสง ความยังไม่ละเอียดพอของโมเดลในการสร้าง Skeleton ในการจัดการเคลื่อนไหว ฯลฯ เคยคิดจะลองทำให้มัน Active กับคำสั่งง่ายๆ เหมือนกัน แต่พอเปิด API มาไล่ดู ก็หันกลับมานั่งทำอย่างอื่นดีกว่า มันมีรายละเอียดต้องทำเพิ่มอีกเยอะ
เอาเป็นไอเดียผมก่อนแล้วกัน ถ้าเป็นผมก็จะทำจอสำหรับควบคุมอุปกรณ์ Smart Home ติดไว้ทั่วบ้าน แล้วมี Home Robot ตัวนึงที่รู้แผนที่ในบ้าน พอเราสั่งงานด้วยเสียง หุ่นยนต์ก็จะแปลคำสั่งแล้วดูว่าเราต้องการทำอะไร แล้ววิ่งไปจอที่ใกล้ที่สุดเพื่อกดหน้าจอเพื่อสั่งไปที่อุปกรณ์ Smart Home ให้เกิดผลลัพท์ตามที่เราต้องการ (โดยใช้สิทธิบัตรนี้แหล่ะเรียนรู้คำสั่งบนหน้าจอ) วิธีนี้จะลดขั้นตอนการต้องเรียนรู้ตำแหน่งของจุดติดตั้งของอุปกรณ์ Smart Home ภายในบ้าน รวมถึงวิธีใช้งานไปได้เลย เพียงเชื่อมต่อตามมาตรฐานผ่านเครือข่ายไร้สายเข้ากับหน้าจอสัมผัส แต่แทนที่เราจะไปกดเองก็ให้หุ่นวิ่งไปกดให้ เช่น เฮ้ย เปิดแอร์ที ขอเย็นๆ ที่ 25 องศา เอาเฉพาะห้องรับแขก หุ่นก็จะไปหน้าจอใกล้ๆ แล้วกดเพื่อให้ได้ผลลัพท์ตามที่เราต้องการ ไอเดียนี้ขายได้ไหม 555 อย่าถือสาผมเลย ผมมันเพี้ยน