By: lew 


 on 30 December 2024 - 00:01
Tags:
on 30 December 2024 - 00:01
Tags:
Topics:

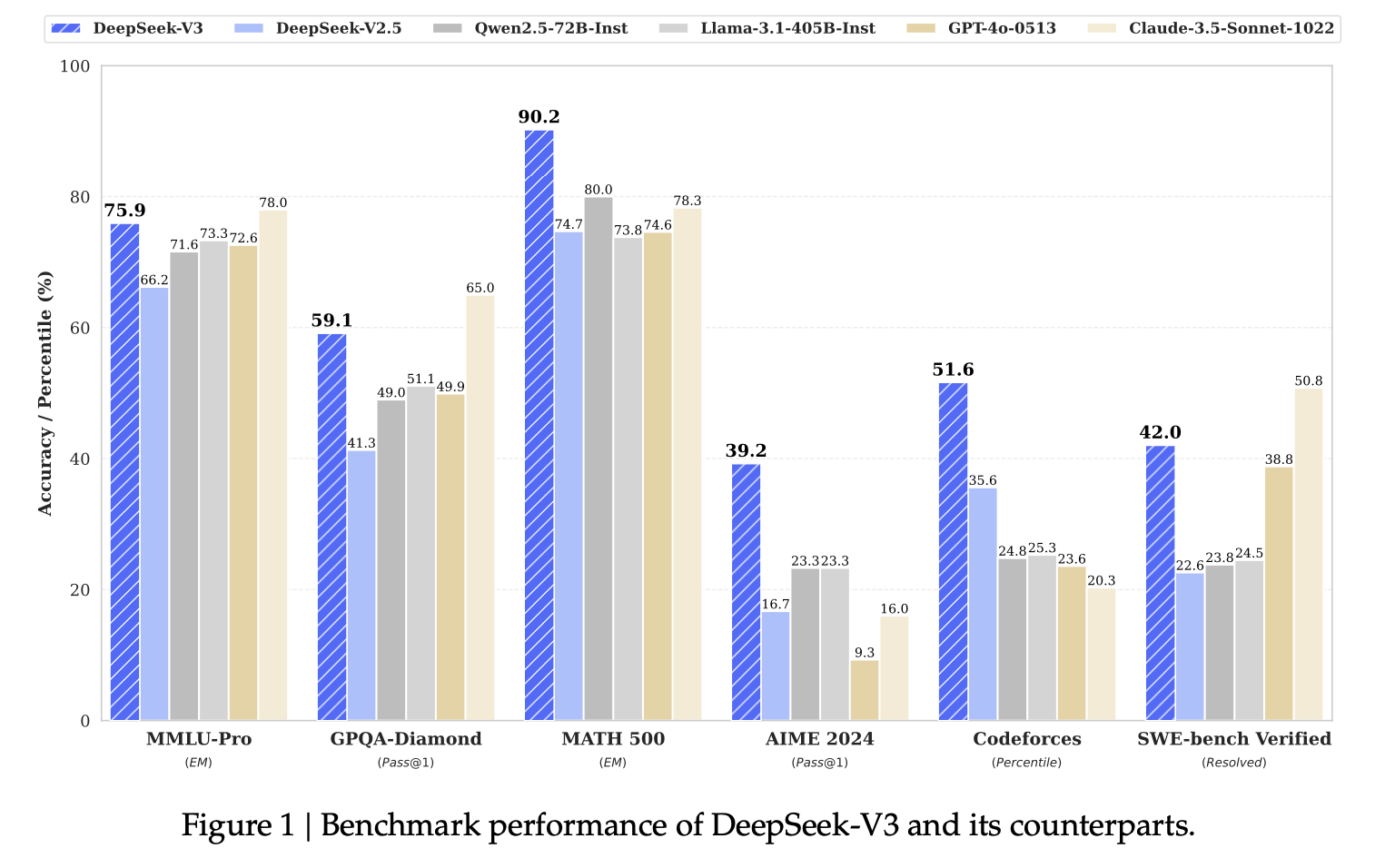
DeepSeek v3 โมเดลปัญญาประดิษฐ์ LLM ที่เปิดให้ดาวน์โหลดไปใช้งานเองที่ใหญ่ที่สุดในตอนนี้ รวม 685B ออกรายงานเชิงเทคนิค เปิดเผยถึงสถาปัตยกรรมและกระบวนการฝึก
เซิร์ฟเวอร์ที่ใช่งานเป็นคลัสเตอร์ NVIDIA H800 รุ่นขายในจีนโดยเฉพาะ ซอฟต์แวร์เป็น HAI-LLM ของบริษัท High Flyer (ตัว DeekSeek ได้ทุนจาก High Flyer Capital Management) รายงานระบุว่า DeepSeek พยายามใช้ช่องทางการสื่อสารระหว่างชิปอย่างเต็มประสิทธิภาพ โดยชิป H800 ถูกบีบแบนวิดท์ระหว่างชิปเหลือ 300Gbps เทียบกับ H100 ที่ส่งข้อมูลได้ 600Gbps กระบวนการฝึกทั้งหดใช้เวลา 2.788 ล้านชั่วโมง
กระบวนการฝึกใช้ข้อมูลแบบ FP8 ข้อมูลที่ใช้ฝึกมีขนาดรวม 14.8 ล้านโทเค็น โดยทีมงานลดความซ้ำซ้อนข้อมูลก่อนใช้งานจริง รูปแบบโทเค็นที่รองรับมีขนาด 128K หลังจากนั้นฝึกแบบ supervised fine-tuning อีกครั้ง ด้วยตัวอย่าง 1.5 ล้านรูปแบบ
ตอนนี้ DeepSeek V3 ให้บริการในราคา 0.014 ดอลลาร์ต่อล้านโทเค็นสำหรับอินพุต และ 0.28 ดอลลาร์สำหรับเอาท์พุต เว็บ Artificial Analysis เทียบให้เห็นว่าเป็นโมเดลที่สุดคุ้ม เพราะราคาเกาะกลุ่มกับ Gemini 1.5 Flash แต่คุณภาพพอๆ กับ Gemini 1.5 Pro หากจะแข่งคุณภาพสูงกว่านี้ก็มีตัวเลือก OpenAI o1-mini หรือ o1-preview ที่ราคาแพงกว่ามาก
ที่มา - DeepSeek

Get latest news from Blognone
Follow @twitterapi



Comments
ชิปเจอแบน ไปร่วมปีแล้ว , โมเดลจากจีน ก็ยังออกใหม่กันรัวๆ
.. ตอนที่ยังซื้อได้ ซื้อไปเท่าไหร่หนอ , เหมือนมี พลังล้นเหลือ ?
ตั้งแต่ v 2.5 ก็ใช้งานได้ดีมาก เรื่อง codeing ดีแบบใช้งานจริงได้ ดีกว่า gemini แทน sonnet เพราะไม่ติด limit
WE ARE THE 99%
ผมติดว่าไม่ขายผ่าน AWS, Azure, GCP นี่ล่ะครับ เปิด vendor ใหม่ลำบาก
lewcpe.com, @wasonliw