By: lew 


 on 1 March 2025 - 12:59
Tags:
on 1 March 2025 - 12:59
Tags:

DeepSeek จัดมหกรรมโอเพนซอร์สประจำสัปดาห์ โดยปล่อยซอฟต์แวร์ที่ใช้พัฒนาและให้บริการ DeepSeek ออกมาเป็นชุด ในกลุ่มนี้มีหลายตัวได้รับความสนใจอย่างสูง เพราะสามารถเร่งความเร็วได้มาก แถมยังเปิดทางแคชการประมวลผลไว้ได้ง่ายขึ้น โครงการที่เปิดมาแล้ว ได้แก่
- FlashMLA: decoding kernel ที่ออปติไมซ์สำหรับ NVIDIA Hopper โดยเฉพาะ พัฒนาต่อมาจาก Flash Attention ตอนนี้ vLLM นำเทคนิคนี้ไปใช้งานแล้ว ส่งผลให้รันโมเดล DeepSeek ประสิทธิภาพดีขึ้น 3 เท่าตัว และเก็บ token ไว้ในหน่วยความจำได้มากขึ้น 10 เท่า
- DeepEP: ไลบรารีสื่อสารข้ามชิปกราฟิกที่ออปติไมซ์สำหรับการรันโมเดลในกลุ่ม Mixture-of-Experts (MoE) เน้นการลด latenncy ให้ต่ำสุด
- DeepGEMM: ไลบรารี CUDA สำหรับการคูณ matrix แบบ FP8 ความเร็วเพิ่มขึ้นสูงสุด 2.7 เท่า แย่ที่สุดคือเท่าเดิม
- EPLB: load balancer สำหรับการรันโมเดลปัญญาประดิษฐ์แบบ MoE ที่ต้องปรับระดับโหลดของแต่ละ expert ในระบบให้เหมาะสม
- DualPipe: pipeline สำหรับรันปัญญาประดิษฐ์ที่เริ่มใช้ครั้งแรกใน DeepSeek-V3 แยกออกมาเป็นไลบรารีให้ใช้งานภายนอกได้
- 3FS: ระบบไฟล์แบบกระจายตัว ทำให้สามารถดึงข้อมูลเข้าโมเดลปัญญาประดิษฐ์ได้เต็มประสิทธิภาพ SSD
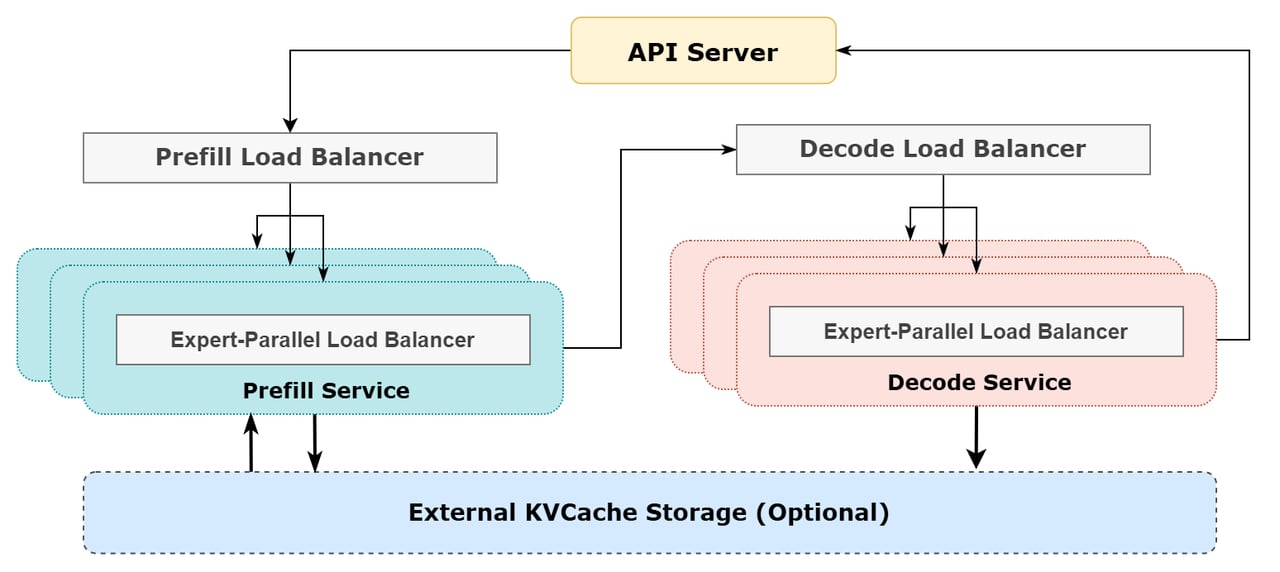
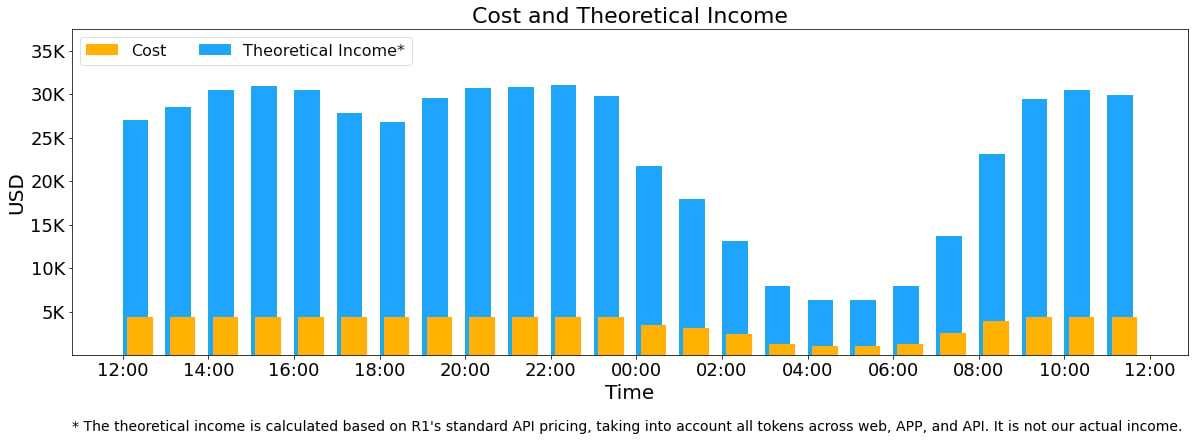
DeepSeek ปิดมหกรรมนี้ด้วยการนำเสนอสถาปัตยกรรมระบบรันโมเดลปัญญาประดิษฐ์ประสิทธิภาพสูง ที่ต้องใช้ชิป H800 ราคาแพงให้เต็มประสิทธิภาพ (ต้นทุน H800 ประมาณชั่วโมงละ 2 ดอลลาร์) การใช้งานตอนนี้เว้นว่างเพียงช่วงเที่ยงคืนถึง 9 โมงเช้า หากคิดราคาค่าโทเค็นตาม DeepSeek-R1 เต็มระบบก็จะทำรายได้ (เฉพาะค่าเซิร์ฟเวอร์) ได้ถึงวันละ 562,027 ดอลลาร์ กำไรต่อต้นทุน 545% แต่ในความเป็นจริงมีคนใช้บริการฟรี หรือใช้ DeepSeek-V3 ที่ราคาถูกกว่าจำนวนมาก ตลอดจนมีส่วนลดการใช้ช่วงเวลาคนใช้น้อยอีก
ที่มา - @DeepSeek_AI

Get latest news from Blognone
Follow @twitterapi


Comments
555 จัดมหกรรม ชอบๆๆๆ
..: เรื่อยไป