By: mk 
 on 17 August 2013 - 09:57
Tags:
on 17 August 2013 - 09:57
Tags:

Facebook เป็นเครือข่ายสังคมที่เชื่อมโยง "ความสัมพันธ์" ของผู้คนและวัตถุต่างๆ ซึ่งบริษัทได้ออกแบบแพลตฟอร์ม Open Graph มารองรับฟีเจอร์นี้ (ข่าวเปิดตัวเมื่อปี 2010) ระยะหลัง Facebook จึงมองข้อมูลต่างๆ ในระบบของตัวเองเป็น "กราฟ" (ในความหมายทางคณิตศาสตร์ ไม่ใช้กราฟเส้นแบบราคาหุ้นนะครับ) ไปซะเยอะ
ล่าสุด Facebook ออกมาอธิบายสถาปัตยกรรมเบื้องหลัง Open Graph ที่สามารถประมวลผลข้อมูลกราฟขนาดมหาศาล (Facebook มองไกลถึงระดับ "ล้านล้าน" ความสัมพันธ์)
เริ่มจากซอฟต์แวร์ประมวลผลกราฟ Facebook ทดสอบการทำงานของซอฟต์แวร์ 3 ตัวคือ Apache Hive, GraphLab, Apache Giraph ด้วยข้อมูลระดับ 25 ล้านความสัมพันธ์ (edge ในภาษาของทฤษฎีกราฟ) และสุดท้ายเลือก Giraph ด้วยเหตุผลว่าทำงานร่วมกับสถาปัตยกรรมซอฟต์แวร์อื่นๆ ของ Facebook (เช่น Hadoop/HDFS/Hive/Corona) ได้ดี
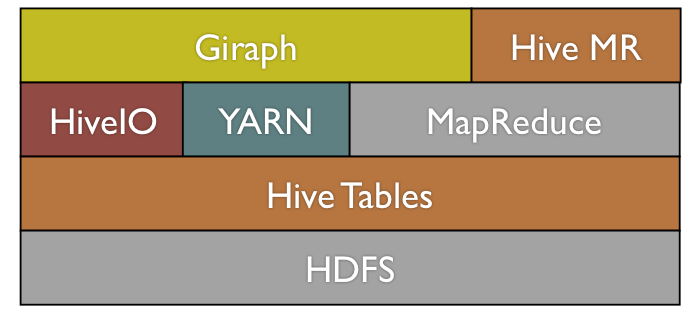
อย่างไรก็ตาม Giraph ยังไม่เพียงพอต่อความต้องการของ Facebook ทำให้บริษัทต้องแก้ไขปรับปรุงโค้ดเพิ่ม รวมถึงเขียนซอฟต์แวร์อื่นๆ มาใช้งานร่วมด้วย
- ปรับ Giraph ให้รับข้อมูลกราฟ (vertex/edge) ได้หลากหลายมากขึ้น จากเดิมที่ Giraph จะเน้นข้อมูล vertex เป็นหลัก
- ข้อมูลของ Facebook เก็บอยู่ใน Hive แต่ดึงข้อมูลจากตารางออกมาโดยตรงไม่ได้ (Hive ต้องใช้ HQL เท่านั้น) ทำให้ Facebook ต้องสร้างซอฟต์แวร์ HiveIO ขึ้นมาอ่านข้อมูลเพื่อส่งต่อให้ Giraph อีกต่อหนึ่ง
- พัฒนาให้ Giraph ทำงานแบบ multithreading ได้ เพื่อกระจายงานออกไปรันอย่างมีประสิทธิภาพ
- ปรับปรุงวิธีการใช้หน่วยความจำของ Giraph ใหม่ จากเดิมที่เก็บทุกอย่างเป็นวัตถุในระบบของ Java ที่กินหน่วยความจำมาก มาเป็น byte array แทน
- ปรับปรุงด้านเสถียรภาพและประสิทธิภาพเมื่อต้องประมวลผลข้อมูลจำนวนมากๆ
โค้ดทั้งหมด Facebook ส่งเข้าโครงการ Giraph แล้ว และล่าสุด Giraph ก็ออกรุ่น 1.0.0 ที่มีฟีเจอร์พวกนี้ทั้งหมด เพื่อให้องค์กรหรือบริษัทอื่นๆ ที่อยากมีสถาปัตยกรรมแบบเดียวกันนำไปใช้งานได้ด้วย
บทความต้นฉบับอธิบายเรื่องการใช้งานกราฟกับข้อมูลจริงไว้อย่างละเอียด (ที่เขียนมานี้ย่อมากแล้ว) ใครสนใจเรื่องทฤษฎีกราฟ และ big data ตามไปอ่านกันได้ครับ
ที่มา - Facebook Engineering

Get latest news from Blognone
Follow @twitterapi


Comments
ขอบคุณครับ
สุดยอดครับ
สุดยอด
สุดยอดเลยแหะพี่มาร์ค อลังการสุดๆ
สุดยอด
Graph Theory
http://en.wikipedia.org/wiki/Graph_theory
link ข่าวเปิดตัวเมื่อปี 2010 เป็น DS Lite!!! นะครับ
ฮ่า ก็อป URL ตกไปตัวนึงครับ ขอบคุณที่แจ้งมา
สุดยอด (ด้วยคน(ใครๆ ก็พูดกัน))
จะบอกว่าเบื้องหลังของ fb ก็คืออากู๋เราดีๆนี่เอง
HDFS = Hadoop File System
เก็บข้อมูลที่ได้แบ่งออกทีละ 64 K โดยมี replicate ไว้อีกหนึ่ง
กระจายไปบนคลัสเตอร์ โดยวิธีการค้นคืนข้อมูลมาทำได้โดย
Map Reduce
สุดยอด
เคยเขียน Java สร้าง udfs ให้ Hive สนุกดี