By: mk 
 on 7 November 2013 - 12:22
Tags:
on 7 November 2013 - 12:22
Tags:

อธิบายสั้นๆ มันคือคู่แข่งของ Apache Hive ที่พัฒนาโดย Facebook ครับ
อธิบายแบบยาวๆ คือบริษัทแบบ Facebook ที่ต้องยุ่งเกี่ยวกับข้อมูลจำนวนมหาศาลระดับ petabyte มีงานเบื้องหลังที่ต้องดึงข้อมูลเก่าที่เก็บใน data warehouse (ที่เก็บด้วย Hadoop/HFS) มาวิเคราะห์อยู่บ่อยๆ ปัญหาคือระบบคิวรีข้อมูลอย่าง Hive ที่พัฒนาอยู่บนแนวคิด MapReduce นั้นออกแบบโดยเน้นสมรรถภาพโดยรวม (overall throughput) เป็นสำคัญ แต่สิ่งที่ Facebook ต้องการคือระบบคิวรีข้อมูลที่มีการตอบสนองรวดเร็ว (low query latency)
ในเมื่อในท้องตลาดไม่มีผลิตภัณฑ์ที่ต้องการก็สร้างมันเองเสียเลย ผลออกมาเป็นโครงการชื่อ Presto ซึ่งเป็นเอนจินสำหรับคิวรีข้อมูลแบบ SQL (รองรับภาษา ANSI SQL ยังไม่ครบชุดแต่ก็เกือบทั้งหมด) มีจุดเด่นที่ความเร็วของการดึงข้อมูล
เนื่องจาก Presto ถูกออกแบบมาให้ดึงข้อมูลขนาดใหญ่ มันจึงต้องทำงานแบบกระจาย (distributed) เพียงแต่ใช้แนวคิดด้านการกระจายงานที่ต่างไปจาก MapReduce โดยใช้วิธีแบ่งงานเป็นขั้นๆ ตาม pipeline โดยออกแบบให้เหมาะสมกับสถาปัตยกรรมศูนย์ข้อมูลของ Facebook มาตั้งแต่ต้น (เพื่อลดการดึงข้อมูลข้ามเครือข่ายโดยไม่จำเป็น)
การทำงานของ Presto เป็นไปตามแผนภาพด้านล่าง เริ่มจากตัวไคลเอนต์ส่งคิวรีมายังตัว coordinator เพื่อแปลความของคิวรี และเตรียมเข้า scheduler คอยจัดคิวการรันคิวรีตาม pipeline ที่เหมาะสม แล้วส่งผลลัพธ์กลับไปยังไคลเอนต์ในท้ายที่สุด
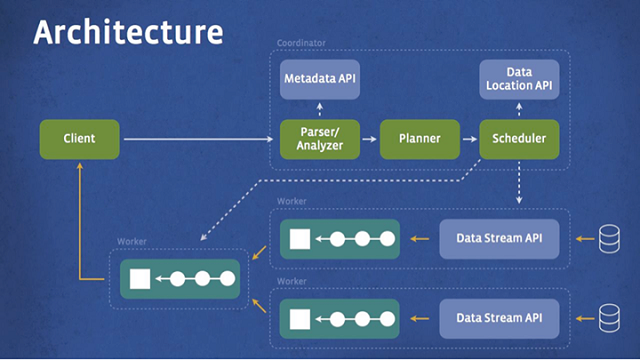
Presto เขียนด้วยภาษา Java เพราะเข้ากับสถาปัตยกรรมของ Facebook ที่ส่วนใหญ่เป็น Java อยู่แล้ว โดยทีมงานก็บอกว่าตั้งใจปรับแต่งเพื่อลดปัญหาเรื่องหน่วยความจำและ garbage collection ของ Java มาเป็นอย่างดี ตัวซอฟต์แวร์ยังออกแบบมาให้มีส่วนต่อขยายกับฐานข้อมูลชนิดอื่นๆ ที่ไม่ใช่ HDFS ได้ด้วย (เช่น ระบบ news feed อยู่บนระบบเฉพาะของบริษัทเอง)
ตอนนี้ Facebook เปิดซอร์สโค้ดของ Presto ภายใต้สัญญาอนุญาตแบบ Apache รายละเอียดของตัวโครงการดูได้จาก เว็บไซต์ของ Presto และ GitHub
ใครที่อยากได้ระบบคิวรีที่ผ่านงานระดับ 300 petabyte และใช้งานโดยพนักงาน Facebook กว่า 1,000 คน รวมถึงบริษัทดังๆ อย่าง Dropbox และ Airbnb ก็เข้าไปศึกษาข้อมูลเพิ่มเติมกันได้ครับ
ที่มา - Facebook Engineering

Get latest news from Blognone
Follow @twitterapi


Comments
Java เร็วเนอะ?
ตอนแรกนึกว่า c++ ที่ไหนได้ Java นิหว่า
เขาก็ไม่ได้บอกว่า java เร็วนิ
ก็บอกว่า เร็วในการดึงข้อมูล ไม่ใช่บอกว่าเร็วในการประมวลผลซะหน่อย
Java ถ้าไม่ใช้ UI ใช้ Core Library เป็นหลัก มันเร็วพอสมควรนะ ถ้างานไหนยากๆ ประมวลผลต้องการความเร็วส่วนใหญ่จะเขียนเป็น Library ด้วย C หรือ C++ แล้วใช้ Java ครอบอีกชั้นเวลาเรียกใช้จากโปรแกรมภายนอก ถ้าวิธีนี้อย่างไงก็เร็ว
แต่ผมว่าอย่าง Facebook น่าจะใช้ C หรือ C++ ประมวลผล แล้วพ่นออกมาเป็น Byte Code เลย เวลาเรียกใช้ก็เรียกจาก Byte Code ของ Java เอาโดยไม่ผ่าน Library Java โดยตรง ใช้เฉพาะโครงสร้างภาษา และ VM ถ้าทำวิธีนี้ หาคนเก่งๆ ทำส่วน Layer ล่างสุดไม่กี่คน ส่วน Layer บนที่จะเอาไป Apply ก็เขียนด้วยภาษา Java ตามปรกติวิธีนี้อย่างไรก็เร็วและหาคนทำงานไม่ยากด้วย
UI นี่หมายถึง swing ใช่ไหมครับ ถ้าใช่เห็นด้วยเต็มที่เพราะ swing ช้าจริงแต่ถ้ารันแบบ console ทั่วไปยอมรับว่าเร็วสุดๆ
อ่านหนังสือไม่แตกหรือเปล่าครับ?
กับ
จาวาไม่เร็ว แต่คนใช้หล่อ เพราะผมใช้
เป็น OOP ที่มี Library เยอะจริงๆ
เมื่อไรจะเลิกออกเสียงว่าคิวรี่ กัน
ทีฝรั่งยังออกเสียงภาษาไทยเพี้ยนเลย ทำไมคนไทยจะออกเสียงภาษาฝรั่งเพี้ยนบ้างไม่ได้
คู-เอ-รี ?
น่าจะเป็นเพราะหลีกเลี่ยงเสียงที่คล้ายคำไม่สุภาพของภาษาไทย
เจอวิทยากรคนอินเดีย ออกเสียง ค_ยยยยยรี่
เน้นพยางค์หน้าอย่างเสียงดังฟังชัดเลยครับ
แค่ระบบ ตรวจสอบการสะกดคำภาษาไทยของ web นี้ผมก็แย่แล้วครับ
ยังจะต้องออกเสียง ภาษาอังกฤษในข่าวให้ถูกตามหลัก ภาษาอังกฤษ อีกเหลอครับเนี่ย ?
เกราย? เอาแบบสเปนผสมละตินไปเลย
ผมอ่านว่า คิวเอรี่ อ่ะ
แล้วจริงๆมันต้องออกเสียงยังไงหรอครับ
ออกเสียงว่า ควย-หรี่ ( ขออภัย แค่ออกเสียงนะฮะ )
o___O !!!!!!!!!!
เควียรีครับ
ลองพยายามออกเสียง q, u, e พร้อมๆ กันสิครับ
เคว(ควบกล้ำ)-รี่ ครับ
อ้างอิงจากอาจารย์ที่มหาวิทยาลัยที่ผมเรียน
ยึดตาม dictionary ก็ได้ตามนี้ครับ
ควีรี?
คิวรีข้อมูลขนาดใหญ่ เท่าไหรถึงเรียกใหญ่ครับ
ส่วนตัวมองว่าแค่ระดับ GB นี่ก็ใหญ่มากแล้ว (ชีวิตเจอแค่นี้) แต่ถ้าอ้างอิงจากข่าว
รอผู้มีประสบการณ์สูงกว่ามาตอบครับ
ดู sample จากที่มา ดึงข้อมูลใหญ่ ๆ ได้เร็วมากจริง ๆ ครับ
select n_name, count(*) customers
-> from customer
-> join nation on (c_nationkey = n_nationkey)
-> group by 1
-> order by 2 desc
-> limit 5;
Query 20131105_005539_00082_ee7y3, FINISHED, 13 nodes
Splits: 187 total, 187 done (100.00%)
0:07 [150M rows, 22.4GB] [22.2M rows/s, 3.32GB/s]