By: lew 


 on 12 July 2017 - 20:54
Tags:
on 12 July 2017 - 20:54
Tags:
Topics:
งานวิจัยด้านคอมพิวเตอร์เรียนรู้ด้วยตัวเอง (machine learning) ถูกกระแส deep learning กลบแนวทางอื่นแทบทั้งหมด เพราะคนจำนวนมากค้นพบว่าหากข้อมูลมากพอ โมเดล deep learning นั้นสามารถเรียนรู้ได้มากขึ้นเรื่อย ความแม่นยำจะสูงขึ้นเรื่อยๆ ตามปริมาณข้อมูล แต่ในวงการวิจัย ชุดข้อมูลกลับไม่เติบโตขึ้นเท่าใดนัก ชุดข้อมูลภาพ ImageNet จำนวน 1 ล้านภาพใช้งานมาตั้งแต่ปี 2011 แม้ว่าโมเดล deep learning จะซับซ้อนขึ้นอย่างมากในช่วง 5 ปีที่ผ่านมา
กูเกิลทดสอบศักยภาพที่แท้จริงของ deep learning ด้วยการสร้างชุดข้อมูล JFT-300M ที่มีจำนวนภาพถึง 300 ล้านภาพ แบ่งออกเป็น 18,281 หมวดหมู่ (แต่ละภาพมีได้หลายหมวด) รวมมีการแปะหมวดหมู่ประมาณพันล้านครั้ง โดยชุดข้อมูลสร้างจากระบบอัตโนมัติ อาศัยข้อมูลเช่นสัญญาณจากเว็บ, การลิงก์จากเว็บต่างๆ การแปะหมวดหมู่จึงมีความผิดพลาดอยู่ประมาณ 20%
การทดสอบประโยชน์ของข้อมูลมหาศาลขนาดนี้ กูเกิลทดสอบปัญหาสี่ประเภท ได้แก่ การจัดหมวดหมู่ภาพ, การจับวัตถุในภาพ, การแบ่งส่วนของภาพ (segmentation), และการบรรยายท่าของคนในภาพ ปัญหาทั้งหมดใช้โมเดลเริ่มต้นจาก ResNet-101
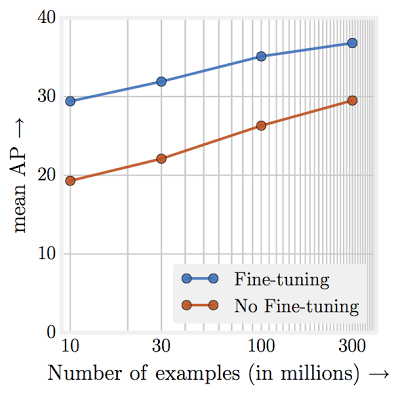
กูเกิลฝึก ResNet-101 โดยใช้ข้อมูล JFT-300M ไป 36 ล้านรอบ (iteration) ก่อนจะมาปรับค่าด้วยข้อมูล ImageNet อีกครั้ง ทำให้ได้โมเดลที่มีความแม่นยำสูงขึ้น และนำค่า weight นี้ไปใช้งานในปัญหาอื่นๆ ตามมา โมเดลที่เริ่มต้นด้วยการใช้ JFT-300M มีความแม่นยำสูงกว่าโมเดิลที่เริ่มต้นด้วย ImageNet อย่างชัดเจน
กระบวนการฝึก ResNet ด้วย JFT-300M ของกูเกิล ใช้การ์ด NVIDIA K80 จำนวน 50 ใบ ฝึกกับข้อมูลขนาด batch ละ 32 ภาพ รวม 36 ล้านรอบหรือ 4 epoch รวมเวลา 2 เดือน โดยความตั้งใจแรกทีมงานอยากฝึกให้ครบ 10 epoch แต่พบว่าใช้เวลานานเกินไป
กูเกิลเรียกร้องให้ชุมชนวิจัยช่วยกันสร้างชุดข้อมูลที่ใหญ่กว่านี้เพื่อให้วงการก้าวหน้า โดยตั้งเป้าให้มีข้อมูลขนาดพันล้านภาพต่อไป
ที่มา - Google Research

Get latest news from Blognone
Follow @twitterapi



Cloudnone
- AWS มาไทย ย้ายเลยดีไหม อะไรยังมาไม่ครบบ้าง? | Cloudnone Ep. 23
- NVIDIA จะไปหยุดที่ตรงไหน ทำไมครองโลกดาต้าเซ็นเตอร์ | Cloudnone EP.22
- ถึงคลาวด์เคราะห์: ทำอย่างไรเมื่อบริการคลาวด์ที่ใช้ถูกยกเลิก | Cloudnone EP. 21
- รู้จักอาชีพ Site Reliability Engineer สำคัญยังไง? | Cloudnone EP. 20
- อธิบาย CrowdStrike ทางเทคนิค ทำไมถึงทำพีซีจอฟ้าเป็นล้านๆ เครื่อง | Cloudnone EP.19
Comments
ทำไมจู่ๆ ผมก็นึกถึงเว็บฝากภาพอนิเม เช่นพวก danbooru ที่มีสารพัดจะ tag (บาง tag ก็แบบ....มันยังจะมี tag แบบนี้อีกเหรอ) ว่าถ้ามีคลังภาพแบบนี้กับภาพลักษณะอื่นๆ คงเอามาใช้สอนได้สบายๆ
แยกหมวดหมู่ภาพว่ายากแล้ว แยกหมวดหมู่วิดีโอยิ่งยากไปอีกเพราะภาพเคลื่อนไหว+เสียง แต่ถ้าทำได้นี่จะเข้าใกล้ General Intelligence มาก
ผมว่าทำให้รับ input เป็นภาพต่อเนื่อง (ภาพเคลื่อนไหว-วิดีโอ) มันยากครับ แต่ขั้นตอนการฝึกมันน่าจะเป็นไปได้เร็วกว่า ตอนเราเป็นทารกเราก็เริ่มแยก object เป็นชิ้นได้เพราะมันเป็นภาพเคลื่อนไหว (ที่รับผ่านลูกตา) แล้วเริ่มรับรู้จากว่ามันเคลื่อนไหวแบบแยกกันต่างหากแล้วสมองถึงจะค่อยๆ เริ่มจำมาว่าจะแบ่งแยก object ได้ยังไงผ่านวิธีอื่นๆ ซ้อนมาอีกทีจนสามารถแยก object หลายชิ้นที่อยู่ติดกันตลอดเวลาได้ (เพราะจำได้ว่ามันน่าจะเป็น object คนละชิ้น) ไปจนถึงแยก object ในภาพนิ่งได้ ถ้าเอาภาพนิ่งไปให้ทารก (ระดับทารกมากๆ) ดูทารกก็ไม่เข้าใจว่าในภาพมี object กี่ชิ้น
ใช้ RNN(Recurrent Neural Network) มาทำครับ อย่าง Deep Q Learning ที่เล่น Atari ตอนนี้ก็ใช้ RNN มาทำแล้ว
แต่ RNN รับประทานทรัพยากรยิ่งกว่านี้อีก แล้ว Train ช้ากว่าด้วยนะครับ ลองไปถามคนที่ทำ NLP สิครับ ทำ RNN ทีพอกดรันปั๊บก็ต้องรำวงรอไปหรือไม่ก็ไปเล่นมุขสามบาทห้าบาทกับคนอื่นเพื่อแก้เซ็ง
เข้ามาอ้าปากค้าง
FB จะมาแซงได้ก็ด้วยปริมาณข้อมูลให้เทรนไม่อั้นเนี่ยแหละ -..-'
my blog
Google photos เองก็มีเยอะใช่ย่อยนะครับ
ถ้างาน NLP มองว่า Facebook ตอนนี้เก่งกว่าครับ
ตัว TensorFlow ยังไม่เก่งทำพวก RNN ครับ
อยากได้แบบนี้มาใช้กับงานด้านอาชญกรรมในไทยจัง
แบบเห็นหน้าแล้วก็บอกได้เลยว่าเป็นใคร
เห็นแล้วอยากให้มีข้อมูลแมลงมั่งจัง เห็นในพันทิบชอบมีกระทู้ถามว่าแมลงตัวนี้คือแมลงอะไรโผล่มาเป็นระยะๆ มันจะดีกับเกษตรกรหน้าใหม่ด้วยจะได้ทำความรู้จักกับแมลงในสวนของเค้า
จริงๆ 36 ล้านรอบผมว่าเอาออกไปดีกว่านะครับ บอกแค่ว่า 4 epoch ก็น่าจะพอแล้ว