By: lew 


 on 27 November 2017 - 00:23
Tags:
on 27 November 2017 - 00:23
Tags:
Topics:

เทคโนโลยีปัญญาประดิษฐ์ หรือคอมพิวเตอร์เรียนรู้ด้วยตัวเอง (machine learning) เคยเป็นเทคโนโลยีที่คนทั่วไปเข้าถึงได้ยากและต้องการความเชี่ยวชาญเฉพาะ แต่ในช่วงปีที่ผ่านมาบริการคลาวด์ก็เริ่มออกบริการปัญญาประดิษฐ์มากขึ้นเรื่อยๆ ทำให้เราสามารถคิดพัฒนาแอปพลิเคชั่นต่อยอดได้
บริการประเภทหนึ่งที่เริ่มมีการให้บริการกันหลากหลาย คือบริการจับใบหน้า เช่น Google Vision API, Azure Computer Vision API, Watson Visual Recognition API, และ AWS Rekognition บริการเหล่านี้แม้จะมีความคล้ายกันคือการจับใบหน้า มักมีความแตกต่างกันไปบ้าง เช่น บริการของกูเกิลและ AWS นั้นสามารถค้นหาใบหน้าคนดังในภาพได้เอง ขณะที่บริการส่วนใหญ่มักสามารถบอกอารมณ์ของใบหน้าในภาพได้ กูเกิลพิเศษกว่าคนอื่นเล็กน้อยที่สามารถบรรยายของตกแต่งอย่างแว่นตา หรือหมวกได้ด้วย
แต่ในแง่ของการปรับแต่ง AWS Rekognition ยังเป็นเจ้าเดียวที่เปิดบริการ Face Recognition ที่เปิดให้ผู้ใช้สามารถสร้างฐานข้อมูลใบหน้าของตัวเอง ทำให้สามารถจับใบหน้าของคนที่เรารู้จักก่อนหน้าได้
สำหรับการใช้งานโดยทั่วไปเรามักมีการยกตัวอย่างสำหรับงานในแง่ของความปลอดภัย ที่เราสามารถใช้ AWS Rekognition มาใช้สำหรับการควบคุมการเข้าพื้นที่ต่างๆ ได้ (แต่ในการใช้งานจริงเราอยากให้ประตูถูกควบคุมด้วยเซิร์ฟเวอร์ในฝั่งตะวันตกของสหรัฐฯ จริงๆ?) ในบทความนี้เรายกอีกตัวอย่างหนึ่งที่สามารถใช้งาน AWS Rekognition ได้คือการจับ "เวลาออกอากาศ" ของดาราหรือนักร้องในรายการทีวี ที่เราอาจจะเคยเห็นดาราเกาหลีแซวกันในรายการต่างๆ บ้างว่าเมื่อมาออกรายการแล้วจะมีโอกาสได้ออกอากาศมากน้อยแค่ไหน
บทความนี้เราจึงจะมาสร้างระบบจับเวลาออกอากาศ ของสมาชิกวง Twice ในมิวสิควิดีโอ Likey
พักดู MV ก่อน
อ่านต่อได้...
สร้างฐานข้อมูลใบหน้า
ข้อมูลที่ใช้สร้างฐานข้อมูล เริ่มต้น ต้องหาภาพใบหน้าเพื่อสร้างฐานข้อมูลของสมาชิกแค่ละคนเสียก่อน ในกรณีนี้เราเซฟภาพจาก Google Image Search (เช่น Jihyo) แล้วเลือกเซฟภาพประมาณ 10 ภาพของแต่ละคนออกมา เมื่อครบแล้วจะได้ภาพ 90 ภาพ ตั้งชื่อภาพให้สื่อว่าจะหมายถึงใคร เช่น tzuyu_001.jpg, sana_002.jpg เป็นต้น
ระบบเก็บภาพลงฐานข้อมูลของ Rekognition เรียกว่า Index Faces หากเราใส่ภาพที่มีใบหน้าลงไปโดยไม่บอกข้อมูลอะไรเพิ่มเติม มันจะคืนค่า UUID ของใบหน้ามาให้โดยไม่มีข้อมูลอ้างอิงอื่นอีก แต่เราสามารถเลือกใส่ข้อมูล External Image ID ลงไปด้วยเพื่ออ้างอิงได้ว่าภาพใบหน้านี้มาจากไฟล์อะไร และในกรณีของโครงการนี้คือเราจะรู้ด้วยว่าใบหน้านี้หมายถึงใคร
ก่อนอื่นเราต้องสร้างฐานข้อมูลใบหน้าขึ้นมาก่อนด้วยคำสั่ง $ aws rekognition create-collection --collection-id twice
เราใช้ boto3 ที่เป็นโมดูลไพธอนสำหรับเชื่อมต่อ AWS เอาไว้ ส่วนตัวกุญแจการเข้า API และการเซ็ตอัพอยู่นอกขอบเขตบทความนี้
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #!/usr/bin/env python3 | |
| """Upload all images and index faces with AWS Rekognition""" | |
| import boto3 | |
| import logging | |
| from os.path import split, splitext | |
| def index_faces(collection, files): | |
| client = boto3.client('rekognition') | |
| for fname in files: | |
| logging.debug('Indexing %s', fname) | |
| mainname = splitext(split(fname)[-1])[0] | |
| image_data = open(fname, 'rb').read() | |
| response = client.index_faces( | |
| Image={ | |
| 'Bytes': image_data | |
| }, | |
| CollectionId=collection, | |
| ExternalImageId=mainname | |
| ) | |
| logging.debug("Resp = %s", response) | |
| def main(): | |
| from glob import glob | |
| images = glob('sources/*.jpg') | |
| index_faces('twice', images) | |
| if __name__ == "__main__": | |
| logging.basicConfig(level=logging.DEBUG) | |
| main() |
สคริปต์นี้จะไล่หาไฟล์ใบหน้าที่เราเซฟเก็บไว้ล่วงหน้าและอัพโหลดขึ้นไปฐานข้อมูลของ AWS โดยกระบวนการนี้มีค่าใช้จ่ายเพียงเล็กน้อยเพราะ AWS ไม่ได้เก็บรูปเอาไว้จริงๆ แต่เก็บเพียงข้อมูลลักษณะใบหน้า (metadata) เท่านั้น
จับภาพจากวิดีโอ
การสร้างภาพจากวิดีโอ อาศัยซอฟต์แวร์ youtube-dl ดาวน์โหลดวิดีโอลงมาประมวลผลในเครื่อง และเพื่อลดข้อมูลที่ต้องประมวลผล เราอาจเลือกภาพเพียง 1 เฟรมจากทุกๆ 12 เฟรมด้วยคำสั่ง
ffmpeg -i likey.mp4 -vf "select=not(mod(n\,12))" -vsync vfr -q:v 2 img_%03d.jpg
จะได้ภาพมาประมาณ 443 ภาพ
ประมวลผลภาพ
ขั้นสุดท้ายของการประมวลผลคือการจับภาพใบหน้าจากภาพทั้งหมดที่เราแยกออกมาได้ เราใช้ API Search Faces by Image เป็นการอัพโหลดภาพเพื่อให้หาใบหน้าในฐานข้อมูลที่เรากำหนด โดยผลลัพธ์ออกมาเป็นไฟล์ CSV ที่ระบุเวลาและตำแหน่งที่พบใบหน้า
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #!/usr/bin/env python3 | |
| """Upload all images and index faces with AWS Rekognition""" | |
| import boto3 | |
| import csv | |
| import logging | |
| from os.path import split, splitext | |
| from botocore.exceptions import ClientError | |
| def search_faces(collection, files, outfname): | |
| outfile = open(outfname, 'w') | |
| outcsv = csv.writer(outfile) | |
| client = boto3.client('rekognition') | |
| for fname in files: | |
| logging.info('Searching %s', fname) | |
| mainname = splitext(split(fname)[-1])[0] | |
| image_data = open(fname, 'rb').read() | |
| try: | |
| response = client.search_faces_by_image( | |
| Image={ | |
| 'Bytes': image_data | |
| }, | |
| CollectionId=collection, | |
| MaxFaces=20 | |
| ) | |
| logging.debug("Resp = %s", response) | |
| except ClientError: | |
| logging.info("No face was found, skip") | |
| continue | |
| for matchdict in response['FaceMatches']: | |
| facedict = matchdict['Face'] | |
| name, sourceid = facedict['ExternalImageId'].split('_') | |
| top = facedict['BoundingBox']['Top'] | |
| left = facedict['BoundingBox']['Left'] | |
| height = facedict['BoundingBox']['Height'] | |
| width = facedict['BoundingBox']['Width'] | |
| outcsv.writerow([mainname, name, sourceid, top, left, height, width]) | |
| outfile.close() | |
| def main(): | |
| from glob import glob | |
| images = glob('full_hd.jpg') | |
| images.sort() | |
| search_faces('twice', images, 'twice_likey_test.csv') | |
| if __name__ == "__main__": | |
| logging.basicConfig(level=logging.INFO) | |
| main() |
ในกรณีนี้เราใส่ภาพใบหน้าของคนเดียวกันซ้ำๆ ไปหลายครั้งในฐานข้อมูลแรก ผมพบว่า Rekognition มีพฤติกรรมแปลกๆ คือแทนที่จะจับใบหน้าทีละใบหน้าแล้วหาภาพในฐานข้อมูลที่ตรงที่สุด มันกลับส่งข้อมูลออกมาซ้ำๆ กันอยู่บ่อยๆ เช่นเฟรมแรก สามารถจับใบหน้า Jihyo ได้จากภาพอ้างอิง 5 ภาพ แถมทั้ง 5 ภาพกลับมีตำแหน่งต่างกันทั้งที่ในภาพน่าจะมีใบหน้าอยู่หน้าเดียวเท่านั้น
อย่างไรก็ดีเมื่อประมวลผลเสร็จก็จะได้ไฟล์ CSV ออกมา
ประมวลผลข้อมูล
เราสามารถประมวลผลข้อมูลได้อีกหลายอย่าง แต่ข้อมูลที่ง่ายที่สุดคือการหาว่าแต่ละคนได้ "ออกกล้อง" มาน้อยเพียงใด เราสามารถเลือกเพียง 2 คอลัมภ์แรกแล้วหาข้อมูลที่ไม่ซ้ำกัน จากนั้นนับออกมาว่าแต่ละคนปรากฎใบหน้าในเฟรมมากน้อยแค่ไหน
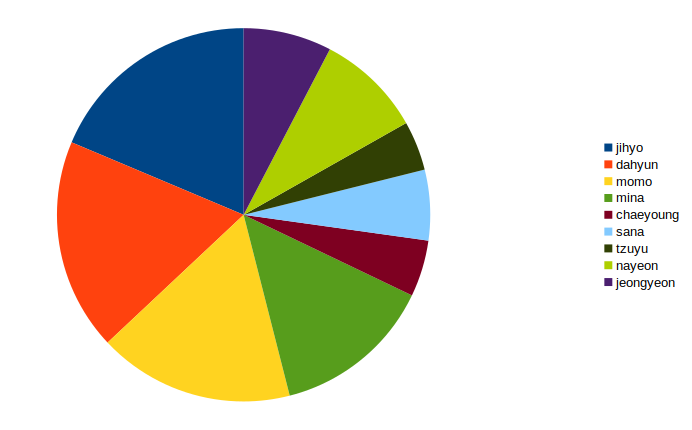
ปล. ผลนี้ยังไม่แม่นยำมากๆ อย่านำไปอ้างอิง
บทเรียนจากการลองใช้งาน
ผมทดสอบ Rekognition มาสักระยะ พบว่ามันน่าสนใจอย่างมากเพราะกระบวนการสร้างระบบจดจำใบหน้า หรือแม้แต่แค่ตรวจจับใบหน้าในภาพเคยเป็นเรื่องค่อนข้างซับซ้อน แต่ Rekognition ทำให้โปรแกรมเมอร์ทั่วๆ ไปเข้าถึงความสามารถเหล่านี้ได้ง่ายมาก
อย่างไรก็ดี Rekognition ยังมีข้อจำกัดของมันอยู่หลายประการ
- กระบวนการหาใบหน้าจากฐานข้อมูลมีความแม่นยำต่ำกว่าการหาใบหน้าปกติมาก เช่นในกรณี MV นี้เมื่อภาพซูมออกครบทั้งวงก็แทบจะจับใบหน้าใครไม่ได้ ทั้งที่เมื่อทดสอบ API หาใบหน้าอย่างเดียวกลับสามารถจับใบหน้าออกมาได้ดี แถมยังจับอารมณ์ของคนในภาพได้อีกด้วย
- Rekognition ไม่รองรับการใส่ภาพตัวอย่างสำหรับคนๆ เดียวหลายๆ มุมมองโดยตัวเอง นับเป็นข้อจำกัดที่ทำให้โครงการซับซ้อนขึ้น
แต่แม้จะมีข้อจำกัด Rekognition และบริการปัญญาประดิษฐ์อื่นๆ กำลังแสดงให้เห็นว่าเรื่องที่เคยต้องอาศัยความสามารถพิเศษกำลังกลายเป็นเรื่องที่ใครๆ ก็ใช้งานได้ หากมีจินตนาการเพียงพอว่าจะใช้ API เหล่านี้สร้างบริการใหม่ได้อย่างไร

Get latest news from Blognone
Follow @twitterapi


Comments
ปร๊าดดดด เอาไปใช้กับ BNK48 รู้ได้เลยใครจะเป็น Center ดู MV มาใครได้ออกบ่อยมีบทบาทบ่อยได้เลย
ขอบคุณสำหรับบทความครับ ได้ไอเดียไปทำอะไรต่ออีกเยอะเลย
แต่มีตรงที่ว่า กูเกิลแยกแยะแว่นตาหรือหมวกได้ ตรงนี้ถ้าเป็นแว่นตาอเมซอนก็ทำได้นะ โดยบอกว่าใส่อยู่หรือเปล่า ส่วนหมวกเท่าที่ลอง ยังไม่ได้
หนูจื่อออกกล้องน้อยสุดเลย