By: mk 
 on 20 December 2010 - 10:38
Tags:
on 20 December 2010 - 10:38
Tags:
Topics:
เรารู้กันดีว่ากูเกิลได้ร่วมมือกับห้องสมุดของมหาวิทยาลัยชั้นนำหลายแห่ง สแกนหนังสือเก่าๆ ให้อยู่ในรูปดิจิทัลทั้งหมด โครงการนี้ทำมาหลายปี และมันเริ่มออกดอกออกผลแล้ว
กูเกิลได้รวบรวมข้อความทั้งหมดในหนังสือจำนวน 5.2 ล้านเล่ม ถ้านับเป็นคำ จะได้ทั้งหมด 500 ล้านคำ คำทั้งหมดนี้จะถูกแยกตามปี และเราสามารถดูแนวโน้มของคำศัพท์ต่างๆ เทียบกับเวลาได้แล้วด้วย Google Books Ngram Viewer
อธิบายง่ายๆ มันคือ Google Trend แต่เปลี่ยนข้อมูลจากหน้าเว็บมาเป็นหนังสือเก่าแทน เนื่องจากข้อมูลมันเก่าพอสมควร (เก่าที่สุดที่ผมเห็นกูเกิลนำมาโชว์คือปี 1750) ทำให้เราสามารถดูแนวโน้มของเรื่องราวในประวัติศาสตร์ต่างๆ ได้ ภาพข้างล่างเป็นตัวอย่างของ "เครื่องดนตรี" ที่นิยมในแต่ละยุคสมัย
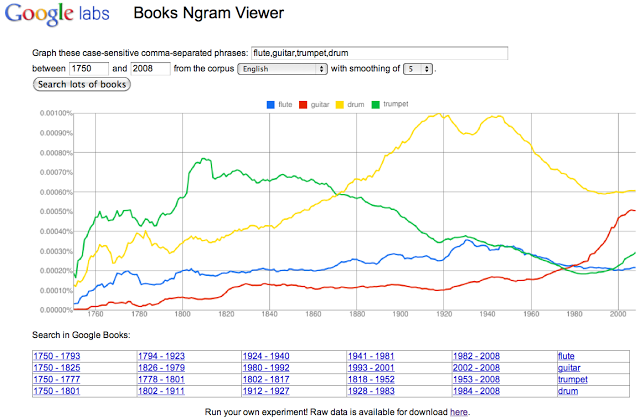
โครงการนี้เป็นความร่วมมือกับทีมนักวิจัยของมหาวิทยาลัยฮาร์วาร์ด ข้อมูลที่นำมาแสดงยังเป็นแค่ส่วนหนึ่งของหนังสือทั้งหมดเท่านั้น เพราะกูเกิลบอกว่าสแกนหนังสือไปแล้ว 15 ล้านเล่ม
ที่มา - Official Google Blog, The New York Times
เว็บไซต์ Ars Technica ได้ลองเล่น Ngram โดยหาข้อมูลจากหนังสือคอมพิวเตอร์มาแสดงแนวโน้มของเทคโนโลยีต่างๆ ไม่ว่าจะเป็นภาษาโปรแกรม ระบบปฏิบัติการ ฮาร์ดแวร์ ตามไปดูได้ที่ A history of computing flamewars—in handy graph form!

Get latest news from Blognone
Follow @twitterapi



Comments
ชอบโครงการนี้มาก นึกถึง Encyclopedia Galactica(ใน Foundation, isac asimov) ขึ้นมาทันที จริงๆในไทยน่าจะจัดงบมา scan หนังสือในหอสมุดแห่งชาติได้แล้วนะ โดยเฉพาะหนังสือเก่าที่มีแต่ microfilm ถ้ายังไง scan ต่อไปเป็น digital ก็ยังดี การเก็บรักษาก็ง่ายกว่า ทั้งการเข้าถึงและต้นทุนการเก็บรักษา