By: lew 


 on 8 October 2023 - 20:58
Tags:
on 8 October 2023 - 20:58
Tags:

การพัฒนาของปัญญาประดิษฐ์กลุ่มโมเดลภาษาขนาดใหญ่ (large language model - LLM) ทำให้มีความพยายามศึกษาการทำงานโครงสร้างภายในของโมเดลเหล่านี้ว่ามัน “คิด” อย่างไร และตอนนี้ Anthropic ผู้สร้าง Claude AI ก็ออกมารายงานถึงแนวทางการศึกษา LLM ว่าควรมองเป็นกลุ่มนิวรอน เรียกว่าฟีเจอร์
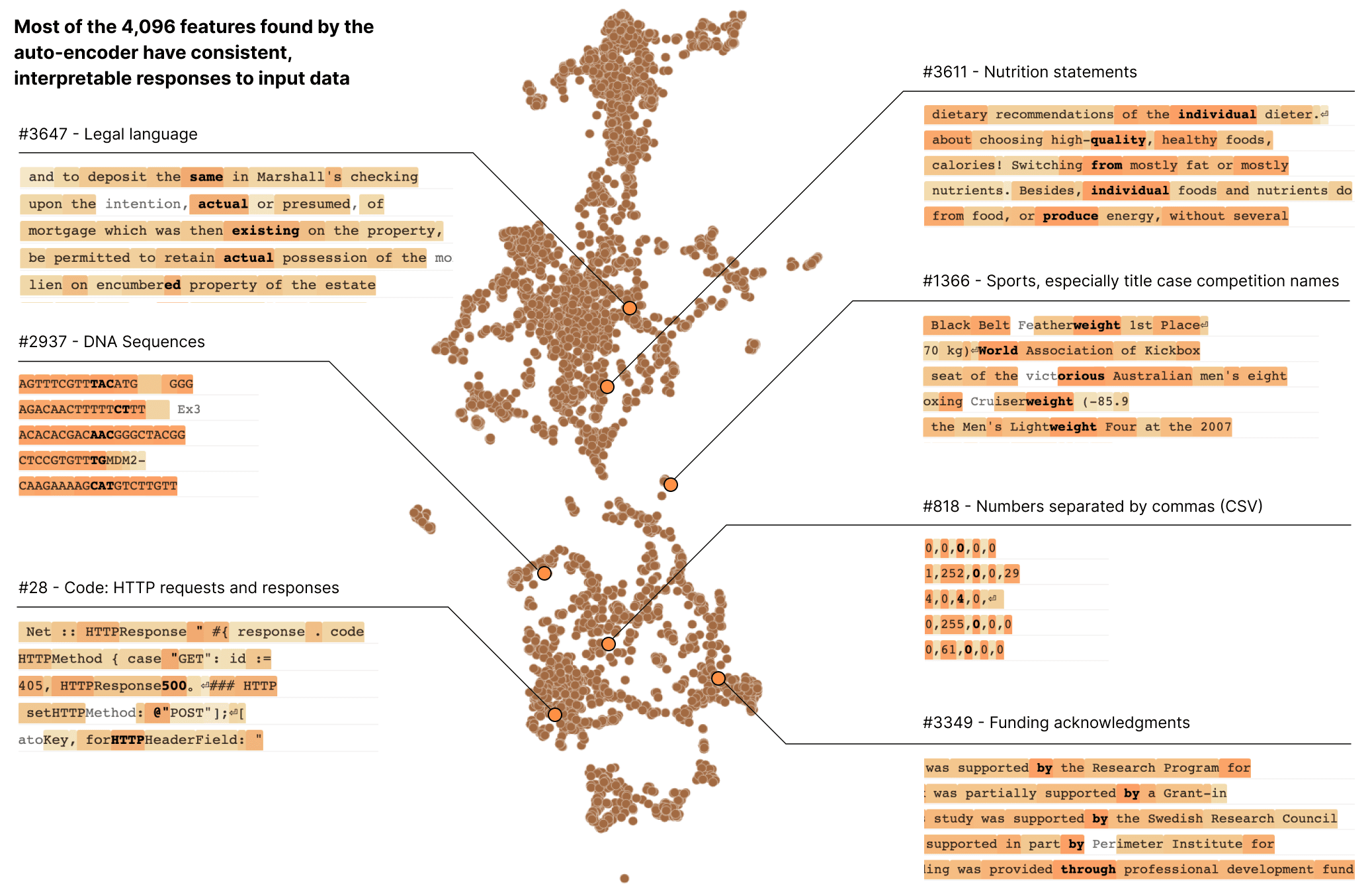
ที่ผ่านมาการศึกษาปัญญาประดิษฐ์กลุ่ม deep learning โดยเฉพาะในงานที่เป็นการจัดการภาพนั้น มักจะพบว่านิวรอนแต่ละตัวถูกกระตุ้นโดยอินพุตที่ตรงไปตรงมา เช่น นิวรอนบางตัวอาจจะถูกกระตุ้นโดยภาพแมวเท่านั้น บางตัวถูกกระตุ้นโดยภาพหมา เราสามารถวิเคราะห์อย่างละเอียดได้ว่าอินพุดแบบใดจึงกระตุ้นนิวรอนเหล่านี้ แต่ใน LLM เมื่อมองเป็นนิวรอนรายตัว Anthropic กลับพบว่านิวรอนแต่ละตัวถูกกระตุ้นในภาวะที่ต่างกันไปจนหารูปแบบไม่ได้
ทาง Anthropic เสนอว่าแทนที่จะมองนิวรอนรายตัว ควรมองเป็นกลุ่มของนิวรอนและดูจากรูปแบบการกระตุ้นของทั้งกลุ่มนั้น เรียกว่าฟีเจอร์ เมื่อมองการกระตุ้นของฟีเจอร์โดยรวมแล้วจะพบรูปแบบที่ชัดเจนขึ้น บางฟีเจอร์ถูกกระตุ้นเมื่อเห็นลำดับ DNA, บางฟีเจอร์ถูกกระตุ้นเมื่อเห็น HTTP request, และบางกลุ่มถูกกระตุ้นเมื่อเห็นภาษาฮีบรู
การทดลองอย่างหนึ่งคือระหว่างการใส่อินพุตเป็นชุดของตัวเลข แต่บังคับกระตุ้นฟีเจอร์บางกลุ่ม ก็จะทำให้เอาท์พุตของโมเดลโดยรวมเป็นไปตามลักษณะของฟีเจอร์นั้นๆ เช่น กระตุ้นกลุ่มภาษาจีนกลางก็จะได้เอาท์พุตเป็นภาษาจีนกลาง กระตุ้นกลุ่มภาษาฮีบรูก็จะได้ภาษาฮีบรู, บางฟีเฟอร์สามารถระบุได้ว่าเป็นตัวอักษรภาษาอังกฤษตัวใหญ่
แนวทางการศึกษาอย่างละเอียดว่าปัญญาประดิษฐ์มองเห็นอะไรจึงให้คำตอบแต่ละคำตอบมาเป็นส่วนสำคัญของการพัฒนาปัญญาประดิษฐ์โดยพยายาทำให้มันปลอดภัยยิ่งขึ้นไปในอนาคต
ที่มา - Anthropic

Get latest news from Blognone
Follow @twitterapi


