

ทีมวิจัยจากสถาบัน Human-Centered Artificial Intelligence (HAI) ของมหาวิทยาลัยสแตนฟอร์ด รายงานถึงผลทดสอบการใช้งานปัญญาประดิษฐ์ในกลุ่ม LLM ว่าแม้จะมีข่าวว่า LLM สามารถวินิจฉัยโรคได้อย่างน่าทึ่งแต่ก็มีความผิดพลาดสูง ต้องระมัดระวัง
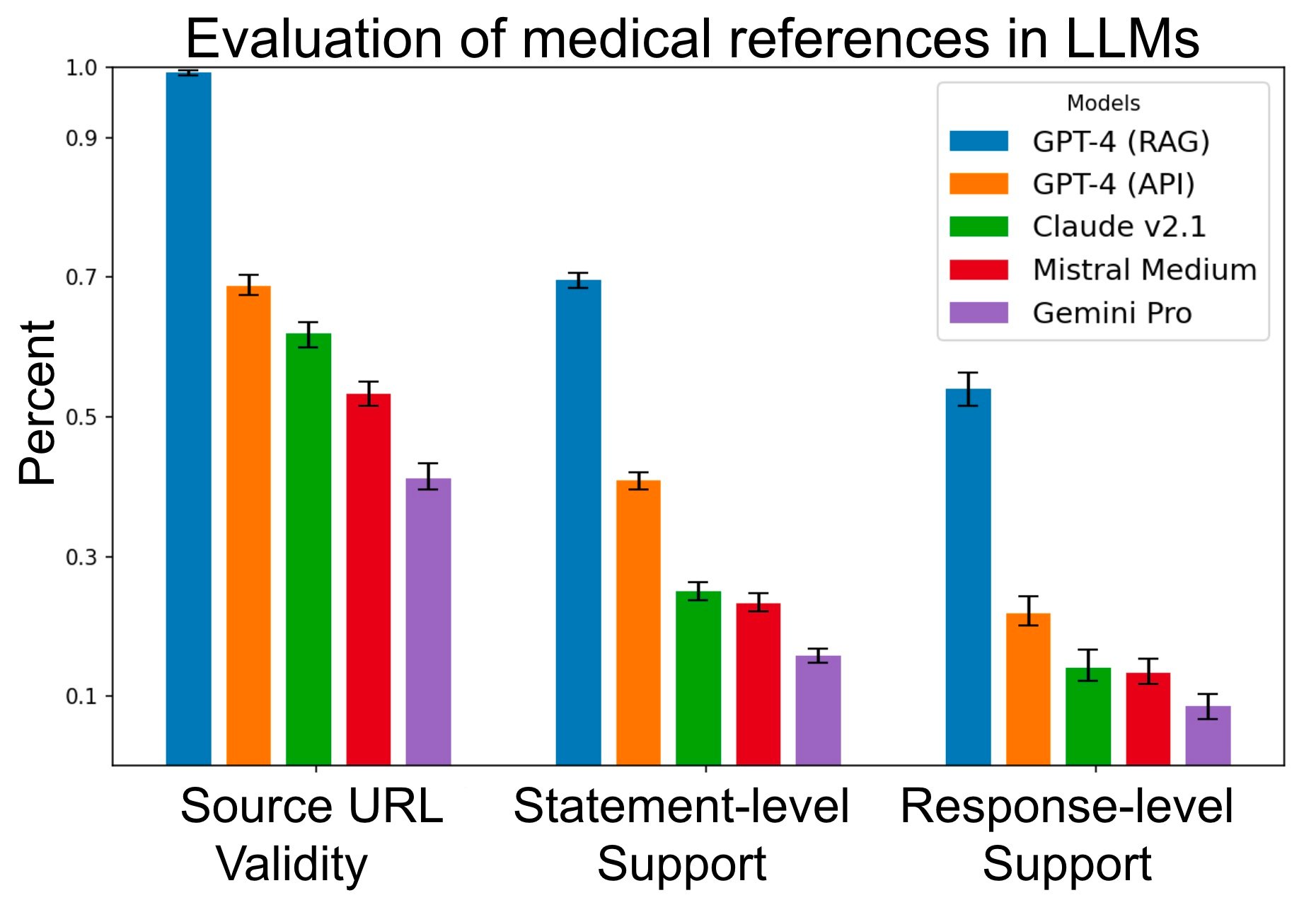
ทีมงานทดสอบการใช้งาน LLM โดยใช้โมเดล 4 ตัว ได้แก่ GPT-4, Claude 2.1, Mistral Medium, และ Gemini Pro เฉพาะ GPT-4 นั้นสร้างแอป retrieval augmented generation (RAG) ครอบอีกชั้นเพื่อทดสอบ โดยวัดว่าเวลาที่ LLM เหล่านี้ตอบคำถามแล้ว สามารถสร้างคำตอบโดยมีการอ้างอิงอย่างถูกต้องหรือไม่
การวัดความถูกต้องมี 3 ระดับ ได้แก่ 1) การวัดว่าที่มาข้อมูลมีจริง ตัวปัญญาประดิษฐ์ไม่ได้สร้าง URL มั่วๆ มาเอง, 2) วัดว่าแต่ละประโยคนั้นมีในที่มาจริง มีแหล่งข้อมูลสนับสนุน, 3) วัดว่าคำตอบโดยรวมมีที่มาสนับสนุนจริงหรือไม่ โดยรวมใช้คำถาม 1,200 คำถาม
ผลทดสอบพบว่า LLM มีแนวโน้มจะสร้างที่มาข้อมูลเองค่อนข้างบ่อย แม้แต่ GPT-4 ก็ยังสร้างที่มา มั่วๆ ถึง 30% ปัญหานี้ลดได้โดยอาศัยการทำ RAG ที่แหล่งที่มาเกือบทั้งหมดมีจริง แต่พอไปดูคำตอบแล้วกลับพบว่าข้อความแต่ละส่วนนั้นไม่ได้มีที่มาสนับสนุนประโยคในคำตอบจำนวนมาก แม้แต่ GPT-4 แบบ RAG ก็ยังมีคำตอบแบบนี้สูงถึง 30%
ทีมวิจัยระบุว่ามีกระแสตื่นเต้นที่ LLM สามารถคำคะแนนทดสอบได้เหนือกว่านักเรียนแพทย์ แต่แพทย์จริงๆ นั้นต้องอาศัยการประเมินหลายด้านกว่าการทำข้อสอบแบบตัวเลือกที่ใช้ทดสอบ LLM มาก
ที่มา - Institute for Human-Centered AI

Get latest news from Blognone
Follow @twitterapi



Comments
ใช้บรรดาสารพัด AI ในการหาข้อมูลทางการแพทย์ ไม่ได้ใช้ในการวินิจฉัยคนไข้นะบอกไว้ก่อน
ข้อมูลที่มากับเนื้อหาที่สรุปไม่ได้มีที่มาที่แท้จริง link ที่ให้มาก็ไม่ได้กล่าวถึงสิ่งเหล่านั้น อยู่ดีๆก็อุปโลกขึ้นมาเอง
ถ้าหากว่าให้มันสร้างบทความขึ้นมาให้ ระยะเวลาในการตรวจสอบบทความและต้องแก้ใหม่นานกว่าที่จะเขียนเองด้วยซ้ำไป ถ้าจะให้มันสร้างให้เราต้องมีความรู้มากกว่ามันถึงจะจับผิดมันได้ แต่ถ้าเป็นเด็กน้อยขี้เกียจทำการบ้าน แล้วให้ AI สร้างบทความขึ้นมาให้ตายสถานเดียว เพราะคุณไม่มีความรู้มากพอที่จะไปจับผิดมันหรือเฉลียวใจว่ามันให้ข้อมูลผิด
แต่ถ้าคุณมีความรู้มากกว่ามันและให้มันสร้างบทความให้ คุณก็ต้องมาแก้ไขเนื้อหาบทความนานกว่าที่จะเขียนเองด้วยซ้ำไป
มันช่วยเรากำหนดขอบเขตเนื้อหาได้ชัดเจนขึ้น แม้ detail จะไม่ได้ลึกมาก แต่ก็ยังไม่เจอข้อมูลที่มันตอบผิด (ผมใช้ copilot) โดยรวมแล้ว มันช่วยทำให้เราเขียนบทความได้ไวขึ้นนะครับ
จริง ชอบใช้ลองใส่อาการคนไข้ลงไปให้ลองวินิจฉัย ได้คำตอบไม่ต่างจาก google เท่าไหร่ กว้างๆและมั่ว
แนวเนื้อหาตรงๆก็ตอบถูกปนผิด
แต่ถ้าทำแนวๆ akinator ทายดารา แบบ ai ถามเพิ่มเติมไปเรื่อยๆจนคิดว่า confidence ที่จะตอบถูก น่าจะแม่นยำขึ้น
Google เท่าที่เคยค้นอาการ สองสามอันดับแรกนี่ได้เว็บโรงพยาบาลแทบตลอดนะครับ ถ้าเป็นภาษาอังกฤษนี่ได้ mayo clinic อันดับหนึ่งแทบจะ 100% เลย
เลยสงสัยว่าที่ค้นๆ กันแล้วเจอว่ามั่วนี่ใช้ keyword อะไรกัน
lewcpe.com, @wasonliw
อาการ... pantip
:D
Google: -*-
lewcpe.com, @wasonliw
ปกติใช้ approach to .... อาการที่เป็นศัพท์แพทย์ครับ
น่าจะยากนะ เพราะ เป็นข้อมูลปิด