By: lew 


 on 19 April 2024 - 00:19
Tags:
on 19 April 2024 - 00:19
Tags:

Meta ปล่อยโมเดลปัญญาประดิษฐ์ Llama 3 สองรุ่น คือ 8B และ 70B แยกรุ่นย่อยสำหรับการทำตามคำสั่ง โดยยังมีรุ่น 400B อยู่ระหว่างการพัฒนา
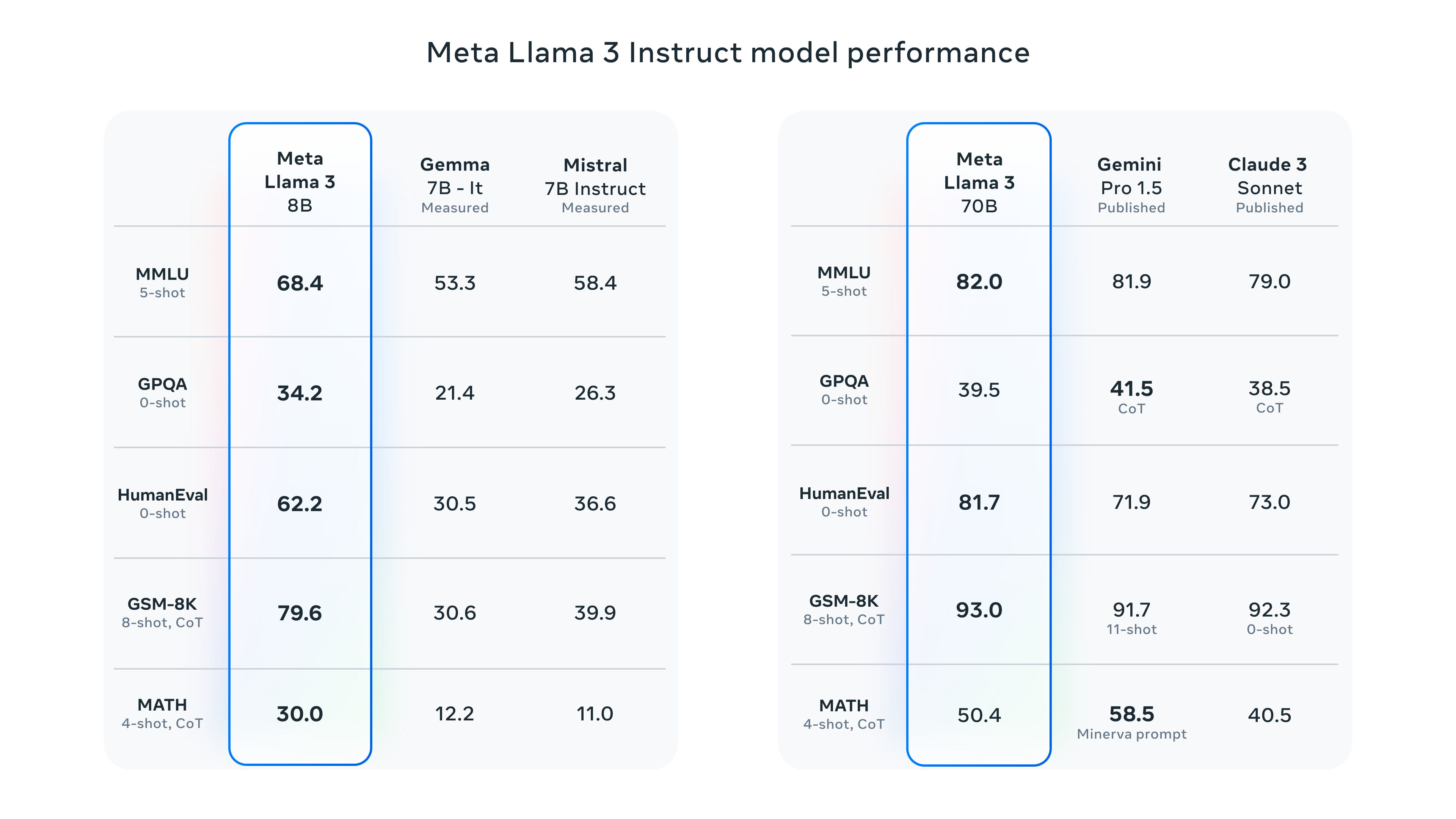
รุ่น 8B นั้น Meta เทียบกับ Gemma 7B และ Mistral 7B Instruct เอาชนะได้ทุกชุดการทดสอบ บางหมวดเช่น HumanEval สำหรับการเขียนโปรแกรม และ GSM-8K สำหรับการคำนวณนั้นนำห่าง
รุ่น 70B ทาง Meta นำไปเทียบกับ Gemini Pro 1.5 ทำคะแนนนำได้บางชุดทดสอบ และเมื่อเทียบกับ Claude 3 Sonnet ก็ชนะทุกชุดทดสอบเช่นกัน
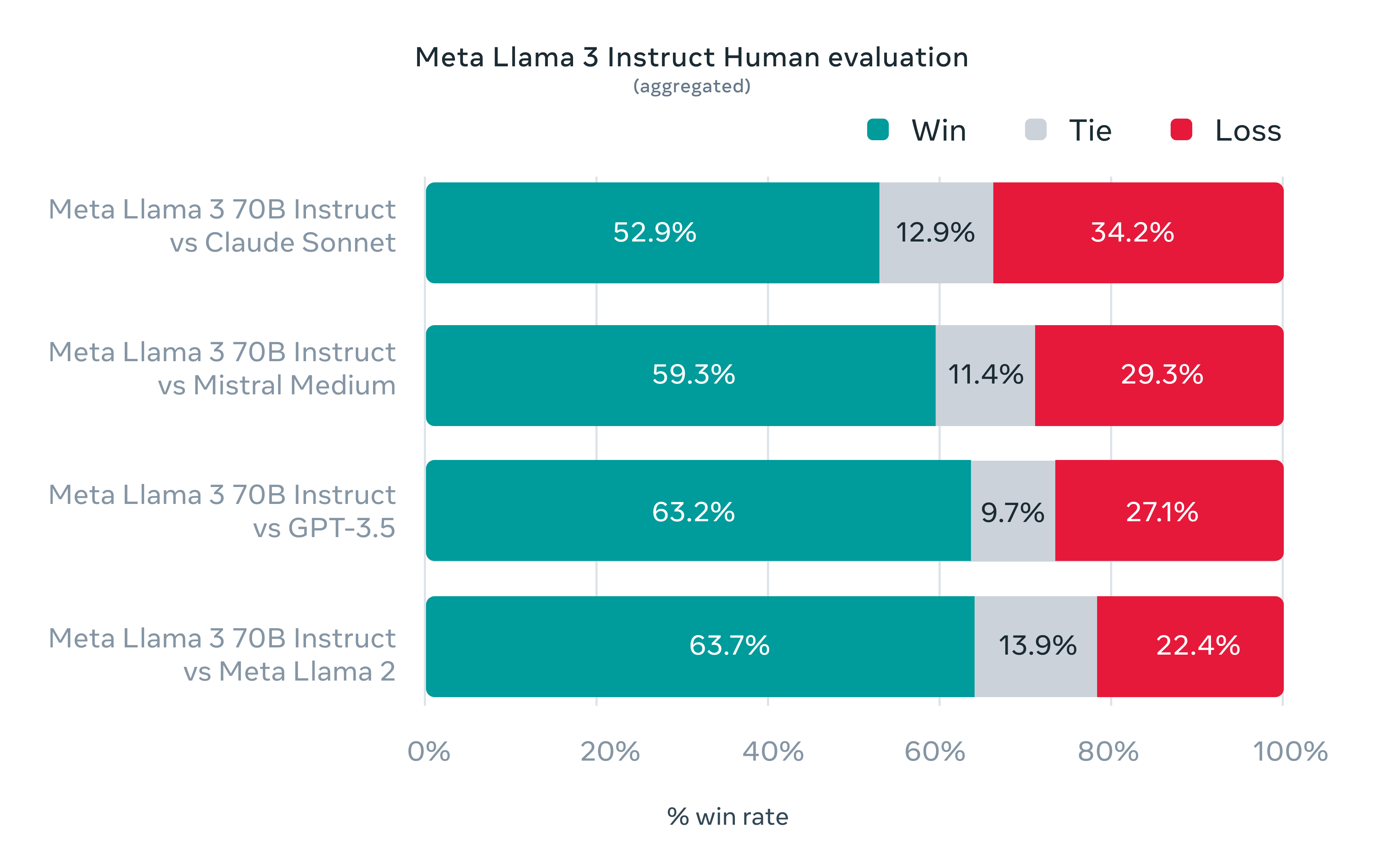
การทดสอบสุดท้ายของ Llama 3 อาศัยชุดทดสอบเฉพาะกิจที่เป็นคำถาม 1,800 รายการที่ทีมพัฒนาไม่ได้เห็นคำถามมาก่อน และนำไปให้คะแนนคำตอบเทียบกันโดยให้คนเป็นคนตัดสินว่า LLM ตัวใดตอบได้ดีกว่ากัน ผลพบว่า Llama 3 70B สามารถชนะ Cluade Sonnet, Mistral Medium, GPT-3.5, และ Llama 2 ได้ชัดเจน
สถาปัตยกรรมภายในรอบนี้มีการเปลี่ยนตัว tokenizer ใหม่ขนาดคำศัพท์ 128K และฝึกด้วย sequence ขนาด 8,192 tokens ชุดข้อมูลขนาดใหญ่ขึ้น 7 เท่าตัวจาก Llama 2 เป็น 15T มีข้อมูลภาษาอื่น 5% รวม 30 ภาษา โดยทั่วไปประสิทธิภาพในภาษาอื่นน่าจะลดลง สองโมเดลรวมใช้เวลาฝึก 7.7 ล้านชั่วโมงจีพียู ปล่อยคาร์บอน 2,290 ตัน
ทีมงานพัฒนา Llama 3 โดยเตรียมให้ทำ fine-tune ได้แต่แรก โปรแกรม torchtune รองรับ Llama 3 มาแต่แรก พร้อมกับโมเดลป้องกันพรอมพ์อันตราย Llama Guard 2 ที่สามารถปรับแต่งโมเดลได้เช่นกัน
ทาง Meta กำลังนำ Llama 3 มาเปิดเป็นบริการผ่านเว็บ แต่ตอนนี้ยังไม่เปิดให้บริการในไทย
ที่มา - Meta

Get latest news from Blognone
Follow @twitterapi



Cloudnone
- AWS มาไทย ย้ายเลยดีไหม อะไรยังมาไม่ครบบ้าง? | Cloudnone Ep. 23
- NVIDIA จะไปหยุดที่ตรงไหน ทำไมครองโลกดาต้าเซ็นเตอร์ | Cloudnone EP.22
- ถึงคลาวด์เคราะห์: ทำอย่างไรเมื่อบริการคลาวด์ที่ใช้ถูกยกเลิก | Cloudnone EP. 21
- รู้จักอาชีพ Site Reliability Engineer สำคัญยังไง? | Cloudnone EP. 20
- อธิบาย CrowdStrike ทางเทคนิค ทำไมถึงทำพีซีจอฟ้าเป็นล้านๆ เครื่อง | Cloudnone EP.19
Comments
คำศัพท์
สองโมเดลรวมใช้เวลาฝึก 7.7 ล้านชั่วโมงจีพียู. ...:)น้ำตาไหล
7.7 ล้านชั่วโมงจีพียู
มันแปลว่าถ้าใช้ 7.7 ล้านจีพียูก็จะฝึกเสร็จใน 1ชั่วโมงใช่มั๊ยครับ แต่เค้าไม่อยากบอกว่เค้าใช้กี่จีพียูและฝึกนานเท่าไรเลยบอกรวมๆแบบนี้หรือเปล่านะ
ปล. model ตอนนี้เยอะไปหมดจนแทบจะไม่รู้ละว่า การที่มันดีกว่าตัวที่อ้างอิงน่ะมันดีจริงหรือเปล่า หรือก็แค่ดีกว่าเฉยๆ เพราะว่าก็มีอีกเยอะที่ดีกว่าตัวของเรา
ประมาณนั้นฮะ
ไม่ใช่ฮะ มันเป็นคนละหน่วยกัน คือคนไม่ได้สนใจว่าใช้ GPU กี่ตัว ใช้ตัวละกี่ชั่วโมง เหมือนที่ค่าไฟฟ้าบ้านเราไม่ได้สนใจจากว่าใช้ไฟกี่วัตต์ กี่ชั่วโมง แต่เป็น เอ้อ เดือนนี้คุณใช้ไฟฟ้าไป 100 กิโลวัตต์ชั่วโมงนะ