By: mk 
 on 28 February 2025 - 10:03
Tags:
on 28 February 2025 - 10:03
Tags:

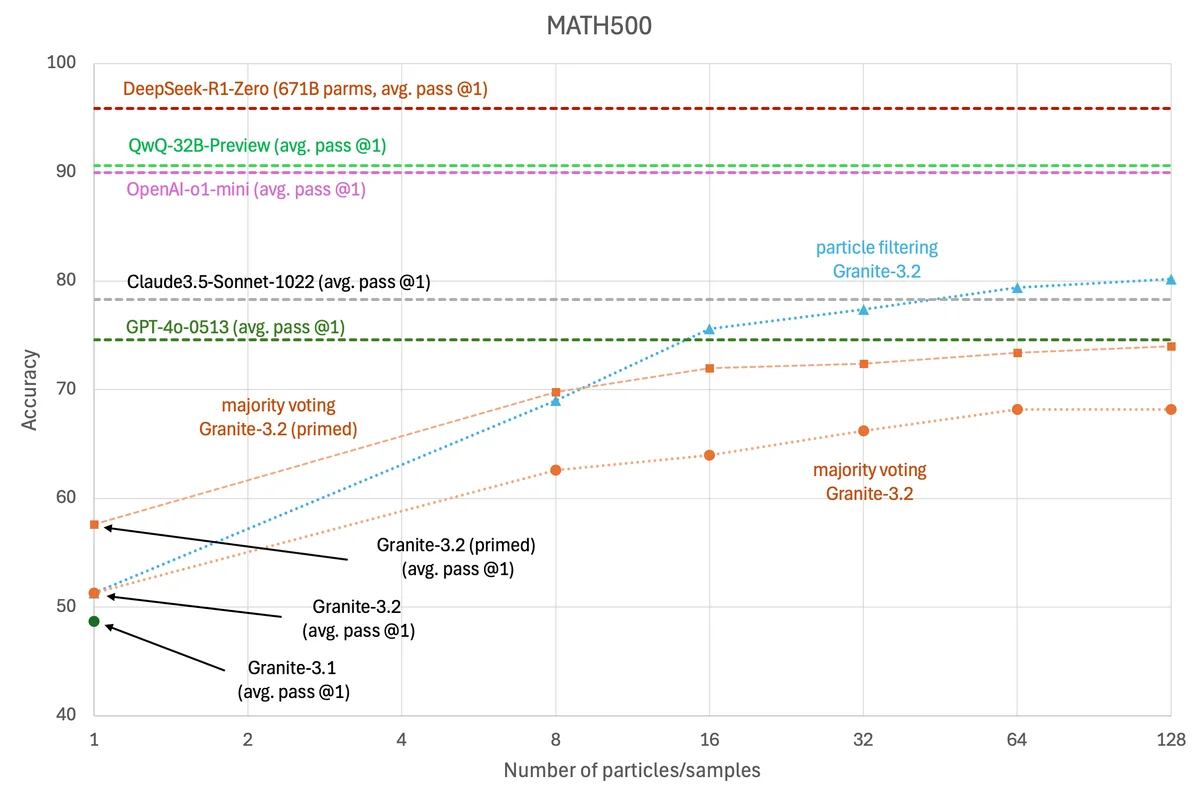
IBM ออกโมเดลภาษาขนาดใหญ่ (LLM) ของตัวเอง Granite เวอร์ชันใหม่ 3.2 ขนาดพารามิเตอร์ 8B (ข่าวของ Granite 3.0) ปรับปรุงความสามารถด้านคณิตศาสตร์และการให้เหตุผลขึ้นจากเดิมมาก และทำคะแนนเบนช์มาร์คชนะโมเดลระดับเดียวกันอย่าง GPT-4o-0513 และ Claude-3.5-Sonnet ได้
ความสามารถด้านคณิตศาสตร์และการให้เหตุผลของ Granite 3.2 มาจากเทคนิค inference scaling ของโลก LLM ที่เปิดให้โมเดลตอบหลายๆ คำตอบแล้วค่อยมาเลือกคำตอบที่ดีที่สุดอีกครั้ง เทคนิคที่ IBM นำมาประยุกต์ใช้คือไม่ต้องรอให้ LLM ตอบให้เสร็จทั้งหมดแล้วมาเลือก แต่แบ่งเป็นขั้นย่อยๆ ระหว่างนั้น แล้วมีการให้คะแนนคำตอบก่อนเลย เพื่อให้รู้ตัวก่อนว่าคำตอบแบบไหนบ้างที่ไม่เวิร์คแล้ว (เรียกว่า process reward models หรือ RPM)
IBM บอกว่าวิธีการนี้ต่างจากท่าของ DeepSeek ที่ใช้เทคนิค long chain of thought โดยวิธีของ DeepSeek ใช้โมเดลตัวเดียวกันมาไล่เช็คคำตอบของตัวเอง แต่ของ Granite เป็นการนำโมเดลสองตัวมาตรวจสอบคำตอบกัน (โมเดลอีกตัวที่ใช้ทำ RPM คือ QWEN2.5-Math-PRM-7B)

อีกข่าวที่เกี่ยวเนื่องกันคือ IBM ยังออกโมเดลภาพ VLM (vision-language language model) ชื่อ Granite Vision ออกมาเป็นครั้งแรก ฐานของมันเป็นโมเดล Granite 3.1 ขนาดพารามิเตอร์ 2B แล้วนำมาปรับแต่ง (fine-tuned) ให้รู้จักภาพ 4.2 ล้านภาพ, เอกสารองค์กร 13.7 ล้านหน้า ทำให้ Granite Vision มีความเชี่ยวชาญเรื่องการอ่านเอกสารมากเป็นพิเศษ ตัวโมเดลมีขนาดเล็ก ทำงานเร็ว และเอาชนะคู่แข่งระดับเดียวกันอย่าง Microsoft Phi 3.5 Vision (phi3.5v) ได้ในหลายการทดสอบ
ตัวโมเดลเปิดให้ใช้งานแล้วบน Hugging Face ใช้สัญญาอนุญาต Apache 2.0


ที่มา - IBM Granite 3.2, IBM Granite Vision

Get latest news from Blognone
Follow @twitterapi



Comments
IBM!!! Open Source !!! ไม่น่าเชื่อว่าพี่เค้าเปิดซอร์สเป็นกะเค้าด้วย 555
https://github.com/ibm
Qwen นี่เจ๋งเนอะ หลายโครงการละ ที่เอาไปต่อยอด
WE ARE THE 99%
คือไม่ได้ทำ reflection ? .. ถ้าเป็นคน ก็คือการทวนคำตอบ , แต่ llm นี่ไม่รู้ว่าจะเหมือนคนมั้ย 🤔