By: mk 
 on 23 August 2017 - 14:57
Tags:
on 23 August 2017 - 14:57
Tags:
ไมโครซอฟท์โชว์ผลงาน Project Brainwave ระบบประมวลผลสำหรับเร่งความเร็ว AI ที่งานสัมมนาด้านซีพียู Hot Chips 2017
Project Brainwave ประกอบด้วยส่วนประกอบ 3 อย่างคือ ชิป FPGA สำหรับประมวลผลงานด้าน deep neural network (DNN), สถาปัตยกรรมการประมวลผลแบบกระจาย, ระบบคอมไพเลอร์และรันไทม์สำหรับใช้งานโมเดลที่เทรนแล้ว

ส่วนของชิป FPGA เป็นผลงานมาจาก Project Catapult ที่ไมโครซอฟท์เคยทำไว้ การออกแบบ FPGA ให้รันงาน AI โดยตรงจะช่วยลดภาระของซีพียู ละลดระยะเวลา latency ในการทำงานลง แนวทางของไมโครซอฟท์คือยัดโมเดล AI ทั้งตัวเข้าไปใน FPGA เพื่อไม่ให้ต้องเสียเวลาประมวลผลแบบ batch ทีละชุด และถ้าโมเดลใหญ่เกินไปก็ใช้วิธีกระจายโหลดไปยัง FPGA หลายๆ ตัวที่อยู่ในศูนย์ข้อมูลแทน
ส่วนตัวซอฟต์แวร์จะเข้ามาแก้ปัญหาเรื่องความยืดหยุ่น เพื่อให้ FPGA สามารถรองรับข้อมูลที่มาประมวลผลได้หลากหลายรูปแบบมากขึ้น โดยไม่ต้องใช้วิธี hard code ไปที่ตัวฮาร์ดแวร์ที่ยากแก่การปรับเปลี่ยน
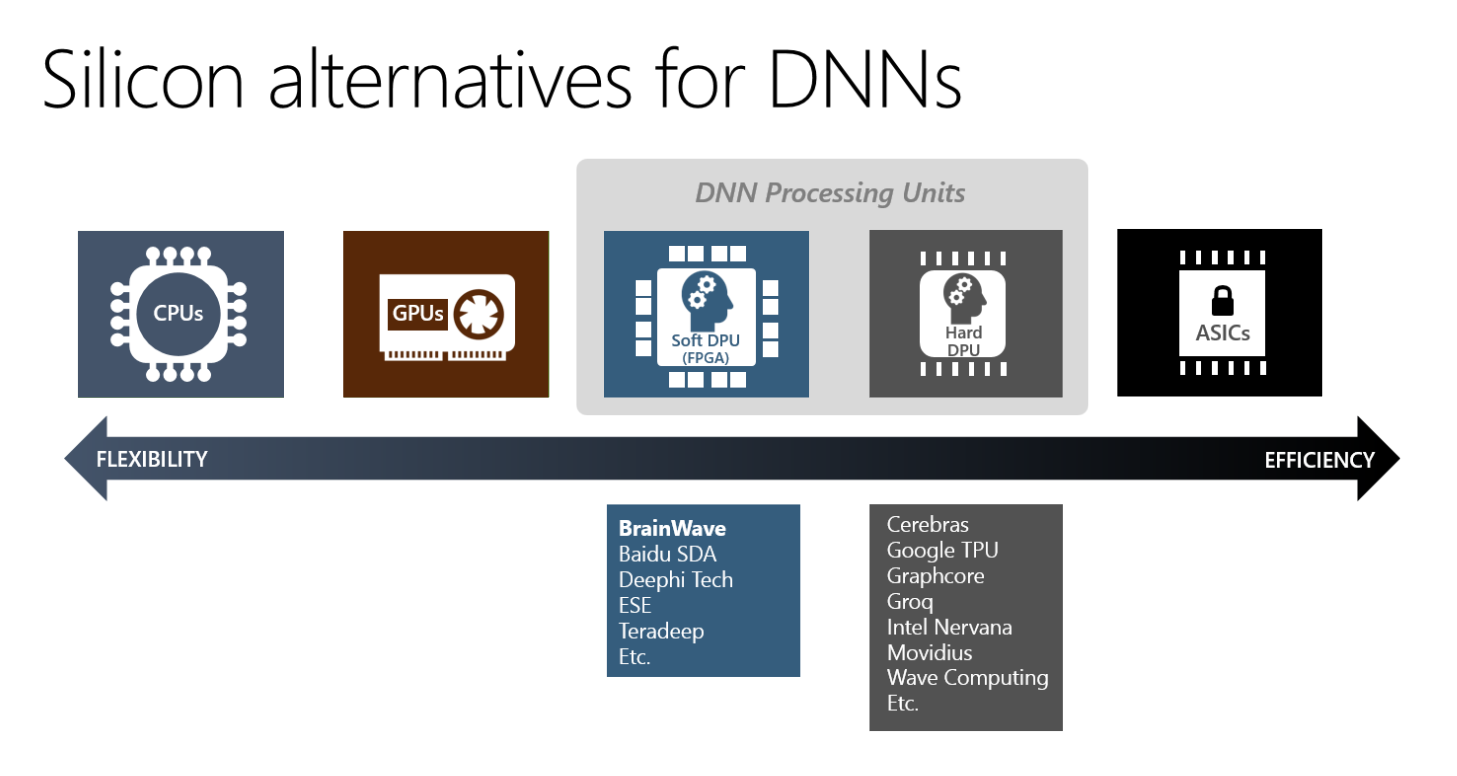
จากภาพจะเห็นว่า Project Brainwave อยู่ในระดับของ FPGA ที่มีความยืดหยุ่นกว่า ในขณะที่ TPU ของกูเกิลอยู่ในระดับของ Hard DPU ที่ยืดหยุ่นน้อยกว่า แต่ประสิทธิภาพดีกว่า
ผลการใช้งาน Project Brainwave โดยใช้ FPGA รุ่น Stratix 10 ตัวใหม่ของ Intel/Altera รันงานประมวลผล AI ขนาดใหญ่ สามารถให้สมรรถนะสูงถึง 39.5 Teraflops ซึ่งถือเป็นสถิติที่สูงมาก และไมโครซอฟท์บอกว่าถ้ามีเวลาปรับแต่งประสิทธิภาพต่อไปอีกสักพัก ก็จะให้ผลลัพธ์ที่ดีกว่านี้อีก
ตอนนี้ Project Brainwave ใช้งานได้กับเฟรมเวิร์ค AI สองตัวคือ Microsoft Cognitive Toolkit และ TensorFlow แต่ก็จะขยายให้รองรับเฟรมเวิร์คอื่นๆ อีกในอนาคต
ที่มา - Microsoft Research

Get latest news from Blognone
Follow @twitterapi


