By: lew 


 on 12 October 2019 - 19:21
Tags:
on 12 October 2019 - 19:21
Tags:
กูเกิลเขียนบล็อกรีวิวงานวิจัยปัญญาประดิษฐ์ในกลุ่มการแปลภาษาอัตโนมัติที่รองรับภาษาจำนวนมาก (massively multilingual, massive neural machine translation - M4) ที่กูเกิลพยายามพัฒนาอย่างหนักในช่วงหลัง เนื่องจากภาษาบางภาษานั้นมีข้อมูลจำนวนน้อย ทำให้การพัฒนาซอฟต์แวร์แปลภาษาอัตโนมัตินั้นได้คุณภาพไม่ดีนัก
ตัวอย่างเช่นการแปลภาษาฝรั่งเศส, ภาษาเยอรมัน, หรือภาษาสเปนนั้นมีตัวอย่างนับพันล้านรายการต่อภาษา แต่ที่มีตัวอย่างน้อย เช่น ภาษาฮาวาย กลับมีข้อมูลเพียงระดับหมื่นรายการเท่านั้น
งานวิจัยที่แสดงให้เห็นว่าการใช้ข้อมูลจากภาษาอื่นมาช่วยปรับปรุงการสร้างโมเดลแปลภาษาในคู่ภาษาที่ข้อมูลน้อยนั้นมีมาระยะหนึ่งแล้ว แต่งานวิจัยในช่วงหลังก็สามารถหาความสัมพันธ์ะระหว่างภาษาที่มีความใกล้เคียงกันเพื่อปรับปรุงการแปลในคู่ภาษาใหม่ๆ อย่างไรก็ดี เมื่อพยายามฝึกโมเดลสำหรับการแปลภาษาที่มีข้อมูลน้อย โดยฝึกภาษาเหล่านี้มากขึ้น คุณภาพการแปลของภาษาที่มีข้อมูลมากๆ ก็จะต่ำลงไป
กูเกิลสร้างโมเดลขนาดใหญ่มากระดับพันล้านถึงหมื่นล้านพารามิเตอร์ เพื่อให้คุณภาพการแปลยังคงดีขึ้นในภาษาที่มีข้อมูลมาก ทำให้คะแนนการแปลดีขึ้นในทุกภาษาเมื่อเพิ่มข้อมูลภาษาที่ข้อมูลน้อยเข้าไปก็ตาม การฝึกโมเดลขนาดใหญ่เช่นนี้มีค่าใช้จ่ายสูงมาก การพัฒนาเทคนิคเพื่อให้ฝึกโมเดลได้เร็ว หรือฝึกเฉพาะส่วนที่จำเป็นจึงเป็นการวิจัยอีกด้านที่กูเกิลกำลังพัฒนา
รีวิวงานวิจัยนี้ ระบุว่าเป้าหมายของการสร้างโมเดล M4 สำหรับแปลภาษาคือการสร้างโมเดลที่รองรับได้ถึงระดับพันภาษาในโมเดลเดียว ขณะเดียวกันก็สามารถเพิ่มภาษาหรือหัวข้อเฉพาะ (domain) ได้โดยง่าย และการสร้างโมเดลแปลภาษาครอบจักรวาลยังเป็นประตูไปสู่การสร้างปัญญาประดิษฐ์ที่รองรับงานหลายประเภทในอนาคต
ที่มา - Google AI Blog
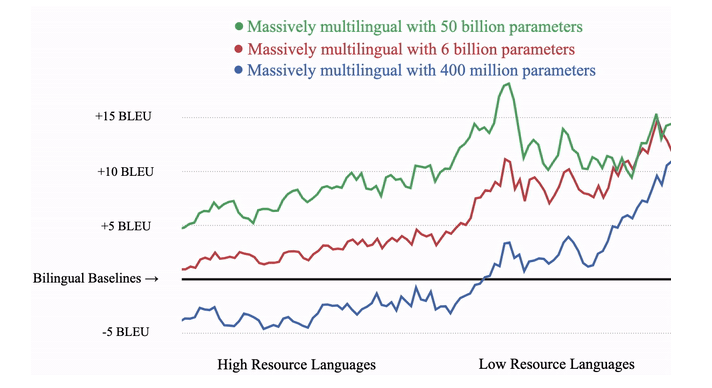
ภาพคะแนนคุณภาพการแปล BLEU ที่เปลี่ยนแปลงเมื่อใช้โมเดลแปลภาษาครอบจักรวาลเทียบกับโมเดลแปลภาษาที่แปลทีละคู่ภาษาแบบเดิมๆ โดยแสดงโมเดลที่มีขนาดใหญ่มากจะสามารถแปลได้ดีขึ้นแม้ในภาษาที่มีข้อมูลตั้งต้นเยอะ

Get latest news from Blognone
Follow @twitterapi


